AI’s Scarcity Moves From Models To The Systems Around Them
Caldwell, Baglino, Helberg, Rao, Huang, and others describe an AI economy constrained by minerals, grid equipment, compute commitments, accelerated infrastructure, and stateful workflows rather than model capability alone. The same shift is reshaping venture debates, where Fielding, Lessin, McClure, and Calacanis distinguish thin model interfaces from companies that control scarce capacity, operational data, distribution, or embedded workflows.

AI’s bottleneck is becoming physical before it is becoming theoretical
The applied-AI economy is running into the parts of the stack that do not scale like software. Chips still matter, but several arguments push the constraint lower: copper, lithium, rare earths, refining, transformers, transmission, local permitting, and the industrial capacity to build and operate all of it.
Erin Price-Wright frames AI dominance as a physical buildout problem: every breakthrough model, factory, and autonomous system needs materials, energy, and grid capacity underneath it. Turner Caldwell, co-founder and CEO of Mariana Minerals, gives the minerals version of that constraint. He says the United States is “50 years behind” China on critical minerals supply, and that even after a project has secured permission to operate, the country remains too slow at designing, building, commissioning, and ramping new minerals capacity.
Caldwell’s answer is not a software layer sold to miners. Mariana is trying to become a vertically integrated mining and refining operator with software and machine-learning systems embedded into the asset itself. Its internal “Capital Project OS,” “Plant OS,” and “Mine OS” are meant to accelerate project delivery and improve autonomous control of refineries and mines. The company already operates a copper mine in Southeast Utah, is building a lithium refinery in Texas, and has set a goal of 10 projects in 10 years.
That matters because the minerals problem is not only extraction. Caldwell argues that the vulnerable handoff is often processing and refining: turning variable earth into usable, high-purity material. In an industry where many sites still run on “pen and paper and maybe 150 spreadsheets,” his view is that software engineers need to sit inside the operating culture, not sell dashboards from the outside. The constraint is know-how, execution speed, and operational discipline as much as ore.
Drew Baglino, founder and CEO of Heron Power and a former Tesla executive, makes the same argument from the grid side. The edge of the grid has changed quickly — electric vehicles, charging, batteries, data centers — while much of the underlying grid equipment remains mechanical, old, and difficult to monitor or control. Heron’s bet is that solid-state transformers can replace “steel, oil, and copper” with silicon and software in power conversion for data centers, large-scale solar and battery projects, and other major energy installations.
solid-state transformerBaglino’s emphasis on silicon carbide also turns grid modernization into an industrial-policy issue. He says the world’s leading producer of silicon carbide, a key power semiconductor, is based in the United States, and argues that the country should commercialize and manufacture around that advantage domestically. His broader diagnosis is that factories do not move only because labor is cheaper elsewhere. In modern automated factories, he says, the labor-cost differential may be less than 10% of cost of goods sold, and possibly less than 5%; China’s larger advantage is co-located supply chains.
Pax Silica is the geopolitical and institutional version of the same thesis. Jacob Helberg, the U.S. Under Secretary of State for Economic Affairs, describes the initiative as a 14-country “economic security coalition” meant to secure the full AI supply chain, not only advanced semiconductors. His list includes precision reducers, servo motors, rare earth magnets, actuators, robotics components, and processing capacity — the inputs that determine whether AI infrastructure and robotics can scale outside a China-dominated supplier base.
The first proposed implementation is a 4,000-acre economic-security zone in the Philippines. Helberg frames it as a forward-deployed industrial base: a platform for private companies to invest in manufacturing, processing, logistics, and other supply-chain functions under a long-term framework still to be negotiated. His contrast with China’s Belt and Road model is ownership and capital allocation. Pax Silica, as he describes it, is not supposed to be a government-operated supply chain; it is supposed to create commercially viable platforms that private companies can use and eventually operate outside direct government control.
| Layer | Constraint described | Proposed response |
|---|---|---|
| Critical minerals | Slow U.S. design, build, commissioning, and refining capacity after projects are licensed | Mariana’s vertically integrated mining/refining operations with embedded software and autonomy |
| Grid hardware | Mechanical, aging power-conversion infrastructure with limited control and monitoring | Heron’s silicon- and software-based solid-state transformers |
| Allied supply chains | Dependence on China across rare earths, robotics components, actuators, and processing | Pax Silica industrial zones and partner-country specialization |
The common thread is that “AI infrastructure” now means more than model training clusters. It means an industrial system that can produce minerals, refine them, convert and move power, manufacture components, and absorb geopolitical shocks. Chips are the visible scarcity. Caldwell, Baglino, and Helberg each argue that the harder constraint is the system around the chips.




Compute has become capital allocation, not IT procurement
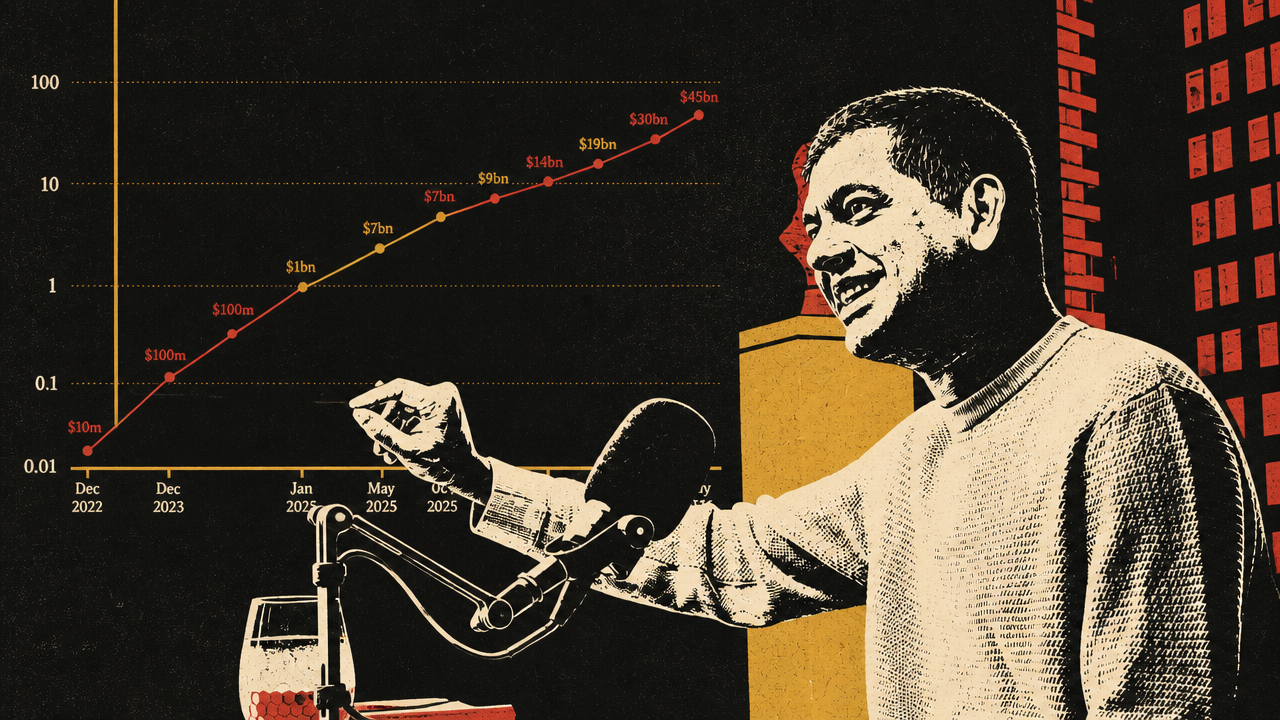
At the frontier labs, the same shift appears one layer up. Compute is no longer an IT line item bought to serve a known software business. Krishna Rao, Anthropic’s CFO, describes it as “the lifeblood” of the company: the resource that determines model development, customer capacity, internal productivity, product releases, and strategic option value.
That framing breaks ordinary software finance. A chip can support customer inference in the morning, model-development work later, and internal automation after that. Compute behaves like R&D, cost of goods sold, capital expenditure, employee leverage, and future-product inventory at once. Rao says he still spends 30% to 40% of his time on compute, not only procurement but allocation: how much goes to training, customer inference, internal acceleration, and future products.
Anthropic’s planning problem is a “layer cake” rather than a fleet. Rao describes multiple chip platforms — Amazon Trainium, Google TPUs, and Nvidia GPUs — arriving at different times, with different price-performance curves, locations, workloads, and durations. Some capacity is suited to reinforcement learning; some to leading-edge training; some to low-latency customer inference; some to consumer or prosumer expansion. Anthropic has announced or discussed large-scale commitments including up to 5 gigawatts of Trainium with Amazon, 5 gigawatts of Google/Broadcom TPUs beginning in 2027, Nvidia GPUs, and near-term access through xAI’s Colossus facility in Memphis.
Rao’s account makes compute look less like a pool of servers than a portfolio of strategic options. The same capacity can be reallocated across present revenue, future model capability, internal productivity, and products that do not yet exist.
Rao says the risk cuts both ways. Buy too much compute and “you gut a business.” Buy too little and the company cannot serve customers or remain at the frontier. Because gigawatt-scale capacity cannot be ordered at the last minute, Anthropic works backward from scenarios rather than point forecasts. The problem is not whether next quarter’s usage is higher or lower than expected; it is whether the company has bought enough future capacity if model capability, customer adoption, and revenue compound together.
That is why Rao argues old gross-margin and forecasting frameworks mislead. The company may choose to allocate compute internally even when it could serve near-term revenue, because internal acceleration feeds the next product and model cycle. Rao says more than 90% of Anthropic’s code is written by Claude Code, and describes finance, tax, reporting, and product teams using Claude as a “digital co-worker.” In that account, compute consumed internally is not overhead; it is part of the mechanism by which the company builds faster.
The private-capital market is responding to the same scarcity. Bloomberg reported that Anthropic is in early talks to raise at least $30 billion at a valuation above $900 billion, with no finalized deal and no signed term sheet. Natasha Mascarenhas described the discussions as moving from unsolicited investor interest to active engagement, with demand exceeding the amount Anthropic was likely to accept. The reported use of funds was a computing-infrastructure push.
The number is striking, but the underlying logic is more important than the valuation headline. If a frontier lab believes compute demand is a cone of uncertainty and private investors are willing to finance infrastructure-scale ambition, the IPO no longer serves the same function it once did. Bloomberg’s Ed Ludlow raised that question directly: if private markets provide the capital, what is the need to go public? The report also noted that a round at the discussed level would place Anthropic above OpenAI in valuation, which Mascarenhas called a major narrative shift.
The caveats matter. Bloomberg presented the financing as early talks, not a completed round. The round had not been finalized, and no term sheet had been signed. But Rao’s operating explanation and Bloomberg’s reporting point to the same market structure: compute scarcity is becoming a private-capital financing problem as much as a procurement problem. Frontier AI companies are raising not just to cover operating losses, but to buy strategic capacity years ahead in a market where being underbuilt can be as damaging as being overbuilt.



Continuous AI changes what computing systems are designed to optimize
Jensen Huang’s Stanford lecture supplies the conceptual bridge between physical infrastructure and software practice. His claim is that computing is shifting from prerecorded, on-demand execution to continuous generation. The old model stored content, compiled software, and invoked computation when a user asked for it. AI systems generate outputs in real time, reason internally, call tools, and increasingly operate continuously rather than waiting for discrete requests.
That shift changes what the stack must optimize. Huang argues that the industry has to rethink chips, compilers, networks, storage, systems, cloud services, and institutions because the bottlenecks are no longer captured by generic peak FLOPs. Large AI systems are constrained by memory bandwidth, memory capacity, networking, latency, storage movement, and energy. He rejects model FLOPs utilization as a sufficient metric because a system can show low FLOPs utilization while still producing the most valuable result if decode is bandwidth-constrained or peak capacity is needed for bursty workloads.
MFUHuang’s roadmap description maps NVIDIA generations to workload regimes. Hopper was aimed at pretraining. Grace Blackwell NVLink 72 targets inference and decode by aggregating bandwidth across a rack-scale system. Vera Rubin is designed for agents, where storage, CPUs, GPUs, and tools have to interact with low latency. Feynman is described as a future architecture for swarms of agents and sub-agents. The sequence shows the point: “more compute” is too blunt a phrase for systems that must be tuned to different patterns of generated work.
| Workload regime | System requirement Huang emphasized | Why it matters |
|---|---|---|
| Pretraining | Very large training systems | Scale model capability before market demand is fully visible |
| Inference and decode | Aggregate memory bandwidth and tokens per watt | Useful generation is often bandwidth- and energy-constrained, not just FLOPs-constrained |
| Agents | Low-latency CPUs, fabric-connected storage, tool-use orchestration | Agentic systems wait on tools, memory, and external actions |
| Swarms | Architectures for many agents and sub-agents | Software may become a coordinated population of continuously operating systems |
Snap’s production migration shows the same logic outside a frontier lab. Prudhvi Vatala, Snap’s head of engineering platforms, says the company’s experimentation system processes more than 10 petabytes of data per day and must deliver results by morning so product teams can make decisions. Rather than keep adding CPUs, Snap moved Spark workloads onto NVIDIA GPU-accelerated infrastructure on Google Cloud, then found a way to reuse idle online-inference GPUs overnight.
The reported result was a 76% reduction in job costs, 62% fewer cores, an 80% lower memory footprint, and about 120 terabytes of disk and memory spill eliminated. The migration did not require application code changes, but it did require platform work: Kubernetes-based Spark runtime on GKE, preemption so user-facing inference kept priority, GPU-to-CPU fallback, and fallback again to Dataproc when shared resources were constrained.
Snap’s example is useful because it is not a lab training a frontier model. It is a consumer platform turning an inference GPU fleet into shared computational infrastructure. Idle accelerated capacity becomes a schedulable asset. Batch jobs must yield to online serving. Data pipelines, experimentation, inference, and platform reliability become one capacity-management problem.
The shared lesson from Huang and Snap is that AI-era systems are optimized around throughput, latency, memory bandwidth, energy, warm state, and utilization of scarce accelerated capacity. “More FLOPs” is not wrong, but it is incomplete. The system that matters is the one that can keep generated work moving continuously under real constraints.




Agents are forcing workflow infrastructure to become stateful and routed
The same move from discrete requests to continuous operation is now showing up in workflow infrastructure. The strongest examples are not generic claims that “agents are coming.” They are operational changes that appear when agents are allowed to produce code, operate tools, speak to customers, and manage model workflows.
Madison Faulkner and Hugo Santos of Namespace argue that traditional CI/CD was built around human-paced pull requests. A human developer creates a small number of changes, waits for reviews and CI, and iterates. The latency of machines hides behind the latency of people. Agents remove that hiding place. They can generate continuous, overlapping streams of changes across many repositories, creating bursts, cache misses, runner saturation, and merge conflicts that the pull-request model was not designed to absorb.
Santos’s key move is to treat the repository as a ledger and merging as a serialization problem. The pull request was a useful unit for human review, but it is the wrong unit for continuous agents. Validation has to move into the agent loop. Environments need warm state. External evaluators — security agents, API-conformance agents, test agents — provide feedback before work reaches human approval. Completed changes enter a pre-merge layer where humans review intent and outcome rather than every diff.
The CI functions do not disappear. Validation, invariant enforcement, coordination, and governance still matter. They move into caches, stateful environments, agent harnesses, pre-merge queues, and policy layers. In Faulkner’s version, an “agent cache” begins as acceleration for GitHub Actions-style workflows but grows into intake, orchestration, routing, identity, retries, and short-lived credentials for agents. In Santos’s version, the future loop has no PRs: intent enters an agent harness, code is generated inside a stateful environment, validation runs inside the loop, and humans approve summarized outcomes.
OpenAI’s GPT-realtime-2 release is the user-facing counterpart. Teri Yu and Erika Kettleson presented the model as a voice agent system with a 128K context window, stronger instruction following, preambles, parallel tool calling, long-running turn context, and controllable speech behavior. The demos were not only about better voice. In the shopping demo, the agent searched products, inspected reviews, called an external weather source, compared options, checked saved sizing, and added items to a cart. In the analytics demo, the agent operated a dashboard, applied filters, preserved investigation state, and spoke only when asked.
Sierra’s Ken Murphy and Soham Ray made the production constraint sharper. A customer-service voice agent has to know when to act, what tools it may use, what policy applies, when to escalate, and how to behave under interruptions, noise, accents, spelling, and user corrections. Murphy said an agent that hallucinates a policy or takes the wrong action even 0.1% of the time is not shippable. Sierra wraps Realtime-2 in a harness with tools, guardrails, supervisors, barge-in handling, redaction, tracing, and customer-specific workflows. Ray’s τ-voice benchmark showed OpenAI Realtime performance improving, but still peaking at 37.2% pass@1 on realistic agentic voice tasks.
| Agent setting | Old unit of work | New operating requirement |
|---|---|---|
| Software development | Pull request | Stateful agent loop, inline validation, pre-merge reconciliation |
| Voice workflows | Conversation turn | Tool routing, interruption handling, long context, guardrails, tracing |
| Model operations | Manual selection and training setup | Agents that choose models, size hardware, launch jobs, and inspect traces |
Hugging Face shows the open-stack version of the same shift. Merve Noyan argues that open models are becoming useful through an operational stack: benchmarks for selection, inference providers for testing, local-serving metadata, trace repositories, MCP access, and Skills for training and job orchestration. Her strongest example is an agent that can be prompted to fine-tune a model, ask follow-up questions about infrastructure and validation splits, estimate VRAM, choose hardware, and launch the job.
The pattern across Namespace, OpenAI/Sierra, and Hugging Face is consistent. Agents are not just model calls with better prompts. They require state, tools, routing, memory, evaluation, observability, and governance. Once agents do real work, the surrounding system becomes the product.





The market is punishing thin AI and rewarding control points
The startup and venture debates are the market consequence of the same systems shift. If durable value moves toward compute, infrastructure, workflow ownership, distribution, data, and deep operational integration, then a product surface wrapped around a foundation model becomes harder to defend.
Jenny Fielding’s legal-tech example captures the speed of strategic obsolescence. She described a founder who raised a $15 million Series A from a top-tier venture firm and, six months later, planned to return the money because he believed Claude and other models would erode the company’s long-term value. Fielding emphasized that this was not a shallow wrapper with no customer understanding; the founder was experienced, technical, close to law firms, and believed he had a data moat. The issue was the five-year view of where frontier models would be.
That story turns AI risk from a product roadmap issue into a board-level and founder-psychology issue. Should a founder who no longer believes in the original strategy return capital, or should investors expect them to pivot aggressively? Fielding leans toward giving strong founders room to rebuild. Sam Lessin argues that if conviction is gone, forcing a founder to run a “zombie company” may waste the scarcest asset: a decade of attention. Dave McClure frames the test as edge and will. Jason Calacanis adds that seasoned founders may compare a risky 10-year rebuild against large compensation packages at the leading AI labs.
The later-stage version is the SaaS-to-agent transition. Fielding says several later-stage portfolio companies are trying to move from SaaS into AI-native or agentic products, and estimates only about half will make it, mainly those willing to move fast. Her examples of real change are painful: replacing executives who are not AI-native, changing pricing from subscriptions to usage, and accepting disruption to the existing business. Intercom’s shift toward Fin is held up as one of the more serious attempts because it changes product identity, pricing, and company structure, not just feature copy.
Lessin’s separate argument sharpens the application-layer question. He says OpenAI and Anthropic are moving into the application layer faster than expected, threatening startups whose main advantage is access to a model plus a thin product interface. His test is severe: if the AI itself is the moat, the company is fragile. Fielding pushes back by distinguishing thin wrappers from companies deeply embedded in enterprise workflows, where distribution and last-mile process ownership may matter. McClure adds that niche applications may remain because the large labs will not bother to serve every specific market.
The debate is not whether the application layer survives. It is what counts as an application with a defensible control point.
| Exposed position | More defensible position |
|---|---|
| Thin interface over a foundation model | Deep workflow integration with proprietary process context |
| Model access as the moat | Operational data, distribution, trust, or regulated workflow ownership |
| SaaS pricing attached to old seats | Usage or outcome models aligned with agentic work |
| Board expectation of predictable late-stage growth | Tolerance for revenue disruption and company rebuilding |
| Generic AI feature roadmap | Control of a system customers cannot easily rip out |
Private-market pressure compounds the strategic pressure. McClure describes the secondary market for many late-stage companies as “cooked,” with some SaaS names seeing 60% to 70% discounts. Fielding warns that if the IPO window does not open meaningfully until 2026, bridge rounds will be brutal. Lessin argues the venture model itself has to shift away from multi-stage markups in an abundant-capital world and toward early, priced exposure to scarce founder talent.
Across these arguments, AI does not eliminate startups. It raises the bar for what a startup is allowed to call defensible. The defensible assets look like the assets running through the rest of the system: scarce compute, operational data, workflow ownership, trusted distribution, regulatory or enterprise trust, physical infrastructure, and systems that become difficult to remove once they are operating continuously.



