AI’s Scarcity Premium Moves Beyond The Model
Nvidia’s quarter, SpaceX’s IPO pitch, startup compute shortages, token economics, agent runtimes, and YC’s operating model all pointed to a broader bottleneck around useful AI work. Gil Luria, Joe Kaiser, Sarah Guo, Shruti Koparkar, Ivan Burazin, Liam Hampton, and Tom Blomfield each located that constraint in different parts of the stack, from packaging and GPUs to execution environments and organizational memory.
AI’s valuation premium moves to scarce infrastructure
The useful way to read the AI market discussion is not as separate stories about Nvidia earnings, a SpaceX IPO pitch, or another round of agent tooling. The common question is where AI demand is now bottlenecked. The answers differed: advanced packaging, GPUs, launch capacity, token economics, agent runtime, and company operating design all appeared as candidates. But the opening fact pattern was clear enough: AI has become large enough that investors are paying attention to who controls hard-to-get capacity.
Nvidia and SpaceX were the clearest examples. Gil Luria of DA Davidson and Joe Kaiser of Switchyard Partners described Nvidia’s latest quarter as evidence that the company’s advantage is not only chip design. Luria said Jensen Huang used the quarter to argue that competitors still have little traction in important parts of the market. Kaiser went further, arguing that Nvidia’s moat sits in the supply chain: advanced packaging capacity at TSMC, networking scale, and the ability to turn silicon into complete “AI factory” systems.
That is a different story from a normal semiconductor cycle. If Kaiser is right, a competing accelerator is not enough. A rival also needs enough access to the constrained packaging and system capacity required to ship at scale. Kaiser said Nvidia is consuming almost two-thirds of TSMC’s packaged-chip output, leaving would-be rivals to compete not only on design but on allocation.
The AI trade is shifting from a contest over model capability toward a broader contest over who can supply, price, run, and absorb the work the models now make possible.
SpaceX’s public-market pitch fits the same pattern, even though the asset base is different. Bloomberg’s Ed Ludlow said SpaceX’s filing presents the company not simply as a rocket launcher but as a vertically integrated infrastructure company: reusable rockets, Starlink broadband, a proposed network of orbital data centers, and AI inference running on GPUs in space. The proposed Nasdaq ticker is SPCX. Bloomberg reported that SpaceX is targeting as much as $75 billion in proceeds at a valuation above $2 trillion, citing people familiar with the matter.
The numbers made the ambition concrete. Ludlow said SpaceX reported almost $5 billion in first-quarter revenue, $11.4 billion for calendar 2025, and about 10.3 million Starlink subscribers. Bloomberg Technology’s broader discussion added that SpaceX disclosed a $4.28 billion loss, a $29 billion debt pile, and a claimed $28.5 trillion total addressable market, of which Ludlow said $26.5 trillion was AI. Benedikt Kammel called the valuation ask “obviously pretty steep” against the current financial base. Lauren Webster treated the TAM as aspirational in the familiar prospectus sense: large, contestable, and meant to assemble several future growth paths for investors.
The SpaceX pitch also showed how AI infrastructure is stretching beyond the terrestrial data-center map. Ludlow described IPO proceeds as helping buy GPUs for AI inference infrastructure in orbit. That proposition depends on several unresolved steps: fully reusable rockets, sufficient launch cadence, satellite deployment, unit economics for space-based inference, and Starship’s ability to carry the required payloads. Bloomberg’s Sana Pashankar said Starship is central because Falcon rockets cannot build the envisioned orbital infrastructure at the same scale or pace.
The comparison with Nvidia is imperfect but useful. Nvidia is selling into the compute bottleneck now. SpaceX is asking investors to underwrite a future in which launch, Starlink, and orbital compute become part of the AI bottleneck. OpenAI and Anthropic were also placed in the same capital-market frame by Luria and Kaiser: companies with enormous demand, heavy losses, and a need for infrastructure capital. Kaiser said OpenAI is discussing hundreds of billions of dollars in infrastructure deployment through the rest of the decade. Luria said Anthropic’s growth has been constrained by compute availability, while OpenAI’s prior advantage included securing more compute.
That is the capital-market turn. AI demand is no longer being discussed only as software adoption. It is being priced through claims on scarce physical capacity: chips, networking, packaging, launch cadence, satellites, data centers, and the financing required to acquire them.






Nvidia tries to widen the demand map
Once the infrastructure question is framed through Nvidia, the central issue becomes whether the company remains a hyperscaler capital-spending story or becomes a broader AI infrastructure platform. Nvidia’s own answer, as described by Bloomberg’s Neil Campling and T. Rowe Price’s Anthony Wang, is that demand is widening beyond the largest cloud buyers into agentic AI, physical AI, sovereign AI, enterprise deployments, inference, edge systems, robotics, and fast-growing AI companies.
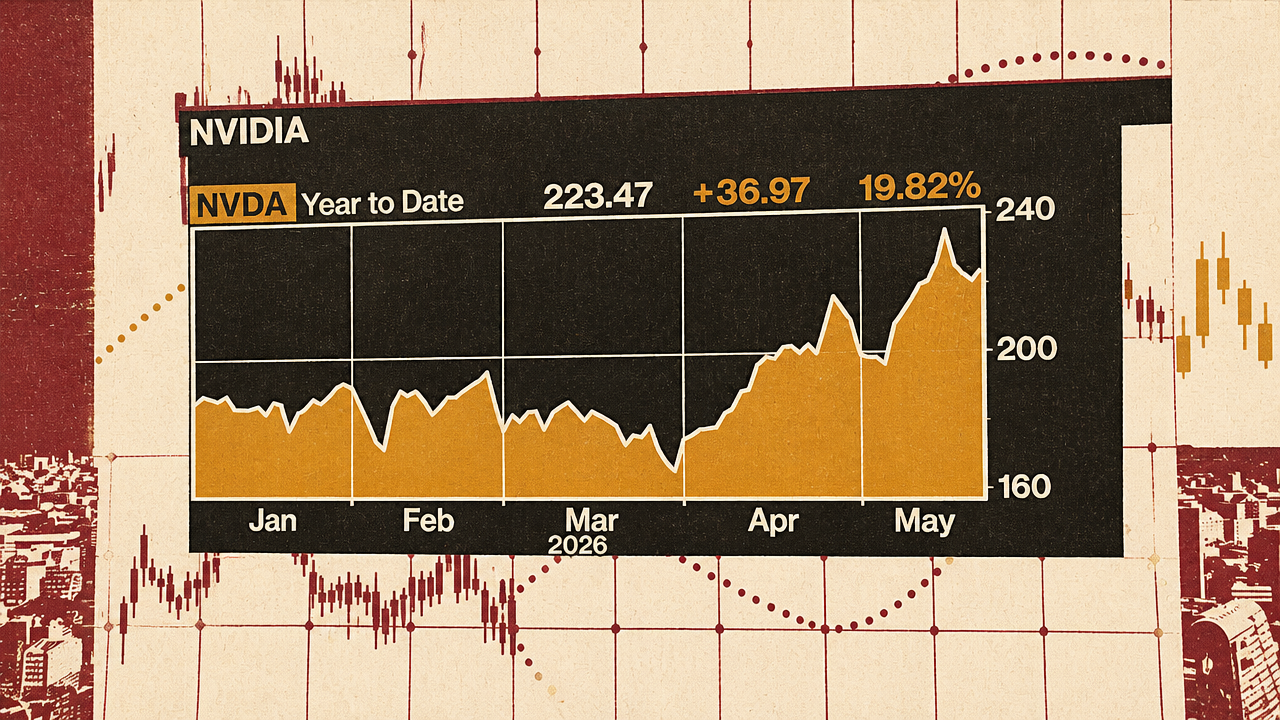
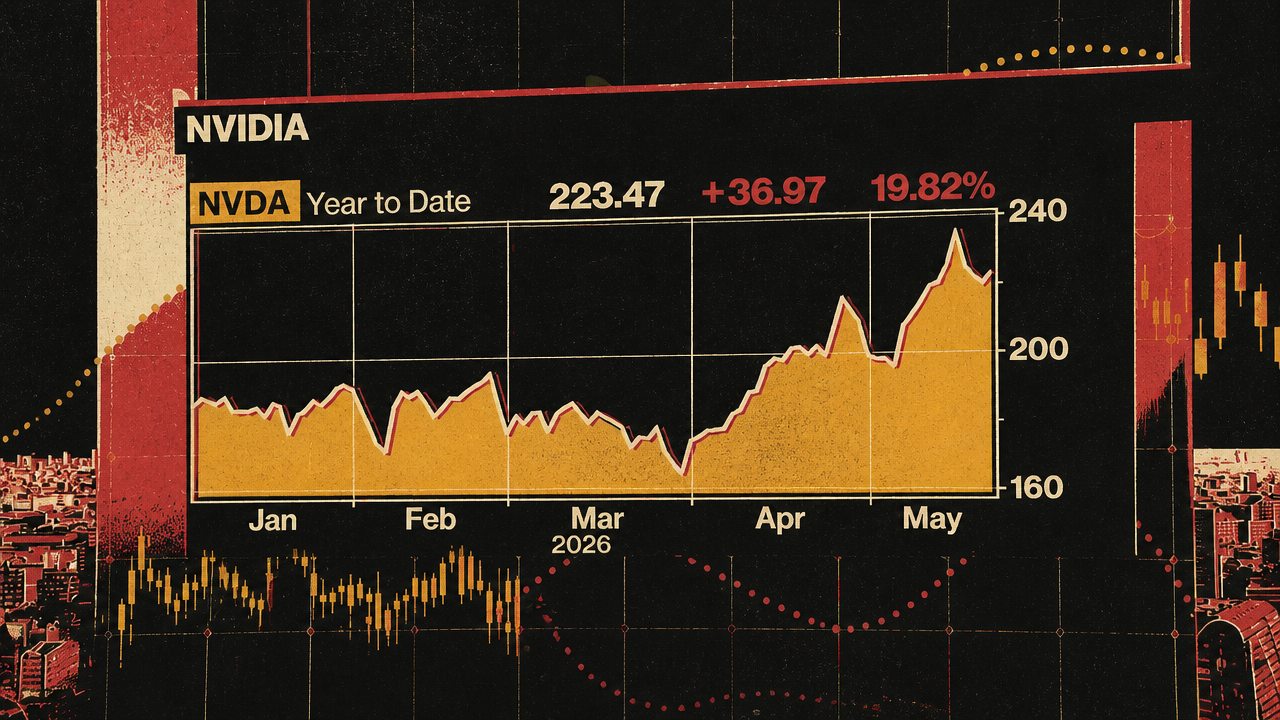
Campling said Nvidia’s reported quarter was extraordinary on its face: 85% top-line growth and a 15th consecutive quarter beating both revenue expectations and guidance expectations. Bloomberg’s segment table showed total fiscal first-quarter 2027 revenue of $81.6 billion, 11.4% above estimates. Compute remained dominant at $60.4 billion, though 1.1% below estimate. Networking was $14.8 billion, 16.1% above estimate. Edge computing was $6.4 billion, 13.1% above estimate.
| Segment | Fiscal 1Q 2027 revenue | Versus estimate | Why it mattered |
|---|---|---|---|
| Compute | $60.4B | -1.1% | Still the core revenue engine, but not the upside surprise in the table |
| Networking | $14.8B | +16.1% | Supports the claim that Nvidia is selling systems, not only chips |
| Edge computing | $6.4B | +13.1% | Fits the broader demand story outside central cloud training |
| Total | $81.6B | +11.4% | Showed another large beat against already high expectations |
The muted stock reaction did not necessarily contradict the strength of the quarter. Campling attributed it to expectations and positioning: Nvidia was already a large index weight, already heavily owned, and already up sharply year to date. Strong results landed in a market that expected strength. Wang made a related but more investor-specific point: traditional semiconductor investors may be using an old cycle playbook, selling growth at scale because they assume margins and demand will eventually normalize.
Wang’s counterargument was that the demand curve may be different this time because inference and agents change the unit of consumption. A one-shot prompt consumes one kind of infrastructure. A persistent agent that works across long time horizons consumes another. Wang said agents may move from minutes of work toward tasks that persist for months, requiring more compute because they must think, act, check, and continue. He also argued that frontier models can be economically efficient despite their cost because better models avoid unproductive paths and complete tasks more reliably.
Campling’s version of the same expansion thesis came through Huang’s market framing. Campling said Huang talked about AI infrastructure spending reaching $3 trillion to $4 trillion a year by the end of the decade. He also said Nvidia was trying to move investor attention away from a narrow debate about hyperscaler custom chips and toward a larger demand set: agentic AI, physical AI, sovereign AI, and companies such as Anthropic scaling at a speed he compared favorably with the early SaaS era.
The distinction matters because the main bear case is not that Nvidia has no demand. It is that Nvidia cannot outgrow hyperscaler capital expenditure indefinitely. Wang identified that concern directly. If Nvidia is mainly a supplier into the capex budgets of a few large cloud operators, then its growth can be bounded by those customers’ budgets and by their interest in custom silicon. If enterprise, sovereign, edge, inference, and robotics demand become material, the capex ceiling moves.
Neither Campling nor Wang presented this as settled. Campling acknowledged competition from alternative chipsets in hyperscaler markets. Wang’s thesis depends on durable demand and continued economic use for Nvidia’s platform. But both framed Nvidia’s next argument the same way: the company wants investors to judge it less like a cyclical chip vendor and more like the infrastructure layer for a widening AI economy.
That is why Nvidia’s networking and systems businesses matter in the debate. Kaiser’s packaging argument, Campling’s networking table, and Wang’s platform thesis all point in the same direction: Nvidia’s moat, if it endures, is not only the GPU. It is the full stack of hardware, networking, software, supply-chain coordination, ecosystem investment, and installed base that turns model demand into delivered compute.


Startups feel the shortage before investors model it
The buyer-side view makes the infrastructure story less abstract. Sarah Guo of Conviction told Bloomberg that compute access is shaping how startups experiment, sequence product development, and spend capital. Her claim was not that startups never care about efficiency. It was that capability discovery comes first.
Guo said Conviction bought H100 compute early for its portfolio because the firm expected its companies would need access and could absorb timing risk better than individual startups. The pattern she described is straightforward: companies begin with current-generation Nvidia chips because frontier performance reveals what is newly possible. As they mature, they post-train smaller models, optimize costs, and redesign user experiences around more token-heavy workflows. But the starting point remains frontier chips.
That sequencing is important because it explains why infrastructure shortages can shape product direction. A startup that cannot access small-scale on-demand compute cannot easily run the first experiments. A company that can secure frontier chips can discover capabilities first and optimize later. Guo said on-demand, small-scale compute is now hard to get, while larger buyers can still struggle even when trying to commit very large sums.
Guo said the shortage has intensified over roughly two quarters and spans different buyer sizes. That is the demand-side counterpart to Nvidia’s earnings commentary. Huang can say demand exceeds global capacity; Guo described the lived version as trying hard to pay for compute and still not being able to secure what startups need.
Her comments also connected the chip bottleneck to agent adoption. Guo pointed to cloud coding and long-horizon software agents as early evidence that AI can generate meaningful revenue in a specific knowledge-work function. But she emphasized that code is not the whole economy. If models, tools, and harnesses can automate tasks people already perform, she said, the opportunity extends across many enterprise functions.
That view helped explain her reaction to SpaceX’s AI TAM. Guo called the presentation of Starlink alongside enterprise AI “funny,” but she did not dismiss the size of the automation opportunity. She treated the central strategic question as a value-chain question: if useful agents emerge, who captures the value? Infrastructure providers, model companies, application companies, or vertically integrated actors that try to own multiple layers?
| Layer | Scarcity or uncertainty described | Who the discussion placed in frame |
|---|---|---|
| Physical compute | Current-generation Nvidia chips and cloud access are constrained | Nvidia; cloud GPU providers; startups |
| Capital | Infrastructure-heavy AI companies need unusually large financing | SpaceX; OpenAI; Anthropic |
| Model capability | Frontier performance determines what startups can discover first | OpenAI; Anthropic; Google; xAI |
| Applications | Revenue may accrue where agents perform valuable work | Coding tools; enterprise AI startups; Cursor-like products |
| Vertical integration | Owning several layers may change who captures margin | SpaceX; Nvidia ecosystem strategy |
The unresolved part is whether scarcity favors the infrastructure owner permanently or only temporarily. Guo’s comments leave both possibilities open. Infrastructure is “extraordinarily valuable,” in her view, and she said Musk will make money from it “no matter what.” But she did not say infrastructure alone settles the market. The model and application layers remain contested because the economic value of AI work may be captured where customers experience the outcome, not only where the compute is supplied.
That makes startup behavior a leading indicator for the broader AI economy. Investors can debate Nvidia’s multiple or SpaceX’s TAM. Founders face the bottleneck in operational form: get frontier compute, find what works, then reduce cost and build the user experience around more capable, longer-running agents.


Token economics becomes the infrastructure lens
The shift from compute shortage to token economics changes the measurement problem. Shruti Koparkar of Nvidia’s Accelerated Computing team argued that AI infrastructure should be evaluated by delivered token value and cost per token, not mainly by GPU-hour pricing or FLOPS per dollar. That framework helps explain why efficiency improvements may not weaken the infrastructure boom. They may make more AI work economically viable.
Koparkar defines tokenomics as the economics of how tokens are valued, supplied, consumed, and monetized. The useful move is to treat tokens as the output of AI infrastructure. A GPU-hour is an input. FLOPS are an input. Tokens, in her framework, are closer to the business unit being produced.
That does not mean all tokens are the same. Koparkar said a token’s value depends on the intelligence it carries and how fast it arrives. A token from a larger, more capable model with a longer context window may be more valuable for some tasks than a token from a smaller model. But a specialized small model may produce better relative value for a narrow domain task if the extra intelligence of the larger model is unnecessary. Interactivity also matters: an agentic system that must complete several steps before responding may need faster tokens than a batch process or an internal search tool.
Tokenomics becomes more complicated when reasoning models and agents are involved. Koparkar said demand forecasts must include “thinking tokens” that are consumed but not shown to users. They also need to include loops: a single user request may trigger multiple model calls, tool calls, sub-agent calls, code execution steps, or checks before the system returns an answer.
That point connects directly to Guo’s startup sequencing and Wang’s agentic Nvidia thesis. If one useful agentic action consumes many hidden intermediate calls, then the user-facing request is a poor proxy for infrastructure demand. Token demand is multiplied inside the workflow.
| Demand factor | What Koparkar said to count | Why it changes the bottleneck |
|---|---|---|
| Base usage | Users, sessions, tokens per session | Sets the visible demand estimate |
| Reasoning | Thinking-token thresholds and average or peak use | Adds invisible token consumption |
| Agent loops | Turns, tool calls, sub-agents, code execution, checks | Multiplies calls behind one user request |
| Cache behavior | KV cache hit rate | Changes how much repeated work must be recomputed |
| Variability | Intraday, seasonal, and growth patterns | Determines peak capacity rather than average use |
Koparkar’s supply-side claim was equally important. She said Blackwell delivers 50 times more tokens per watt than Hopper and 35 times lower token cost. Those are Nvidia claims, and they belong inside Nvidia’s own infrastructure argument. But the conceptual point extends beyond one product generation: if businesses run on token output, then the relevant metric is how many useful tokens a full system can deliver at what cost.
That framework also explains why lower token cost may increase GPU demand. Noah Kravitz asked whether cheaper tokens eventually mean fewer GPUs are needed. Koparkar answered no, citing the Jevons-paradox logic: as efficiency improves, new use cases become economical, and demand expands. Reasoning, test-time scaling, and agentic workflows can consume the efficiency through more turns and more automation.
This is one place the arguments reinforce each other. Nvidia bulls can argue that efficiency improvements expand demand rather than cannibalize it. Startups can justify starting with frontier chips because high token budgets let them discover new experiences. Agent infrastructure providers can expect more runtime demand as each user request becomes a chain of model calls and tool actions.
But Koparkar’s framework also introduces discipline. More tokens are not automatically more value. The use case determines the needed model, context length, interactivity, demand pattern, and monetization strategy. An enterprise AI feature that burns expensive tokens without producing a valuable outcome is not rescued by infrastructure scale. Cost per token matters because it links the physical AI buildout to business value rather than treating compute consumption as success by itself.


Agents turn software work into an infrastructure problem
If token economics explains why AI demand is hard to forecast, agent runtime explains why AI demand is hard to serve. Daytona chief executive Ivan Burazin argued that agents need “composable computers,” not merely disposable code-execution sandboxes. That claim moves the bottleneck from GPUs alone to the full execution environment around agents: state, persistence, operating systems, CPU bursts, isolation, file systems, terminals, desktop access, evaluation runs, and workflow orchestration.
Burazin’s distinction is between a sandbox as a temporary test box and a sandbox as production infrastructure for software that acts. An agent writing code, running tests, manipulating files, calling tools, or using a desktop environment needs more than a stateless function. It may need a Linux machine for code, a Windows environment for enterprise software, a macOS environment for Apple-specific workflows, GPU-backed rendering, or a persistent machine that can pause and resume.
Daytona’s scale claims show why this is not just developer-tool polish. Burazin said Daytona can start a sandbox in roughly 60 milliseconds including network latency, spin up 50,000 sandboxes in about 75 seconds, and support one customer running about 850,000 sandboxes per day. He said mean utilization is around 15% because workloads are spiky, while peak utilization can reach 90%. Reinforcement-learning and evaluation workloads, he said, were expected to become roughly half of usage in the month discussed.
Those numbers matter because agent workloads look different from ordinary human software usage. Background agents may follow a global workday. RL and eval jobs can arrive as rectangular bursts: nothing, then 10,000, 50,000, or 100,000 CPUs at once, then nothing again. If expensive GPUs are waiting on CPU-side environment startup, slow sandbox provisioning can waste the most constrained resource in the system.
RL/eval workloads therefore add another bottleneck to the AI stack. GPUs may be scarce, but agents also need fast CPU environments, local disk, snapshots, nested execution, Docker-like interfaces, and the ability to scale abruptly. Burazin said Daytona chose bare metal, local NVMe snapshots, and its own scheduler to combine startup behavior closer to Lambda with state closer to EC2.
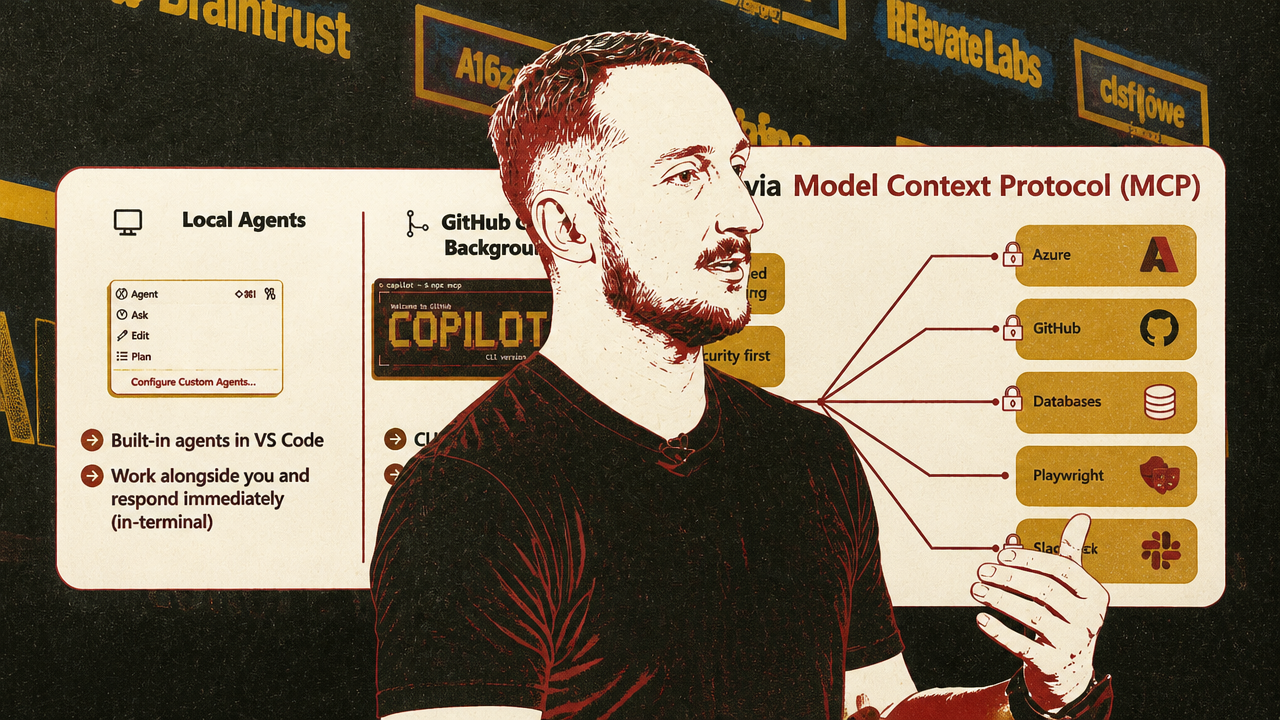
The same shift is visible at the application layer in VS Code. Microsoft’s Liam Hampton presented local, background, and cloud coding agents as different execution modes selected by risk and desired developer control. In his demo, tests belonged to a local agent because he wanted close iteration. A front-end implementation ran through a background agent isolated in a Git worktree. Documentation and open-source housekeeping went to a cloud agent running through GitHub Actions.
The important point was not that VS Code alone solves agent infrastructure. It was that developer interfaces are becoming control planes for multiple agent execution modes. Hampton’s categories map directly onto the runtime problem Burazin described: local work where the human stays close, background work that needs isolation and persistence, and cloud work that needs remote execution, permissions, branch isolation, and restricted tool access.
| Agent mode | Infrastructure requirement | Human posture |
|---|---|---|
| Local coding agent | Immediate environment, project context, fast feedback | Hands-on iteration |
| Background coding agent | Isolated worktree, long-running task execution, inspectable result | Partial delegation |
| Cloud coding agent | Remote ephemeral compute, branch isolation, controlled network and tool access | Hands-off delegation |
| RL/eval agent workload | Large bursts of sandboxes, CPU capacity, snapshots, nested execution | Automated large-scale testing or training |
This complicates the simple “GPU bottleneck” story. Agentic AI can increase demand for GPUs through more model calls, but it also creates demand for stateful compute, CPU-heavy sandboxes, versioning systems, CI capacity, desktop environments, and orchestration tools. Burazin said some customers are already straining Git, GitHub, and CI with agent-generated work, including high volumes of pull requests and new approaches to versioning sandbox state.
The broader implication is that AI work is becoming infrastructure-heavy even inside software teams. A coding agent is not only a chat interface. It is an execution environment with state, permissions, isolation, tools, and cost. Once agents move from suggesting code to doing work, the runtime becomes part of the product.


The last bottleneck is institutional absorption
The final bottleneck is not physical supply or runtime infrastructure. It is whether organizations can make themselves usable by AI. YC general partner Tom Blomfield argued that startups should not bolt copilots onto existing org charts. They should build recorded, queryable operations that AI systems can observe, use, and improve.
Blomfield’s claim starts with company design. Traditional companies use people as the coordination mechanism: managers, meetings, hierarchies, and information passed up and down the organization. AI changes the constraint only if company knowledge becomes legible to machines. That means recording work, preserving context, exposing deterministic tools, creating feedback loops, and allowing systems to detect failures and improve the next run.
His practical line was stark: if work is recorded, it happened to the AI; if it is not recorded, it did not. YC’s own example was office hours. Blomfield said YC had roughly 2,000 hours of recorded office hours from the previous three months and used that material to regenerate a 150-page user manual, organized around categories such as fundraising, hiring, and co-founder disputes. The point was not simply better documentation. It was that each new piece of advice can be compared with the existing manual and folded back into a living system.
This is the organizational analogue to Koparkar’s tokenomics and Burazin’s agent runtime. A company cannot benefit from more tokens if its work is hidden in inaccessible channels. It cannot deploy agents effectively if those agents lack tools, policies, data, and feedback. It cannot improve through AI if failures are not detected and routed back into the system.
Blomfield described the operating unit as a loop: sensors and data, a policy layer, deterministic tools, quality gates, and a learning mechanism. In YC’s internal case, a monitoring agent looked at employee queries, identified failures, inferred what tools or indexes would have made the query succeed, wrote code, opened a merge request, had an agent review it, and deployed improvements. He contrasted that with a simple assistant that makes a human somewhat more productive.
- Initial AI adoptionCompanies add copilots to existing workflows and measure incremental productivity.
- Recorded operationsWork moves into captured, searchable, compressed systems that AI can query.
- Tool exposureAgents get deterministic APIs and permissions to act, not only context to read.
- Feedback loopsFailures are detected, improvements are proposed, and systems update the next run.
- Institutional absorptionThe company becomes easier for AI to operate and improve, rather than merely staffed by people using AI tools.
This is a more demanding claim than “AI makes employees faster.” It requires companies to redesign work so AI can see it and act on it. Internal software becomes more disposable; context becomes more durable. Blomfield said startups should “burn tokens, not headcount,” and claimed YC is seeing companies reach Demo Day with about five times more revenue per employee than companies did 18 months earlier. But the mechanism is not just token spending. It is operational structure.
The arguments all treat AI as economically material, but they locate the binding constraint in different places. Nvidia and its bulls point to global capacity, advanced packaging, networking, inference, and broader demand. SpaceX asks investors to imagine launch and Starlink scale becoming part of AI infrastructure. Guo sees startups constrained by frontier compute before they can even discover product possibilities. Koparkar shifts the metric to delivered token value and cost per token. Burazin sees agents demanding stateful computers and bursty CPU infrastructure. Hampton shows developer workflows splitting across local, background, and cloud execution. Blomfield says organizations themselves must become recorded, queryable, and recursive.
None of those bottlenecks excludes the others. As AI leaves the demo phase, the constraint stops being one model feature and becomes the whole system around the model: the capital to build capacity, the supply chain to deliver it, the economics to price it, the runtime to execute work, and the institutional design to absorb it.

