Applied AI’s Edge Moves From Model Output To The Systems That Validate It
Today’s sources put the visible AI capability in a larger operating loop: Waymo’s generated driving plans depend on validation and simulation, Einride’s autonomous freight on orchestration, voice agents on interaction infrastructure, and commerce AI on fresh data and latency. The shared question is not whether models can produce useful output, but what systems make that output safe, current, reliable, and durable enough to deploy.
The model is not the moat; the validation loop might be
Waymo gives the cleanest version of today’s applied-AI pattern: a generative model matters only if the system around it can test, constrain, and improve what it generates.
Srikanth Thirumalai described Waymo’s driver as generative software that produces plans for how the vehicle should move. But in his framing, the plan is not the product by itself. The product is the driver plus the surrounding machinery that makes the plan safe enough to deploy: real-time safety checks, an onboard validation layer independent of the driver, simulation, and a “critic” that finds weak performance in both real and simulated driving.
That is a narrower claim than “full stack beats end-to-end.” Bloomberg’s Tom Mackenzie framed the strategic divide as Waymo’s componentized approach versus “brain-only” or end-to-end strategies associated with competitors such as Tesla and Wayve. Thirumalai did not say those rivals are unserious. He called Tesla formidable if it reaches L4 autonomy and can ship it broadly across its fleet. He also treated convergence as plausible, because the safety problem is shared. Companies may differ on hardware, model design, and decomposition, but they are all trying to drive safely at scale.
The important point for applied AI is what Waymo says scale means. It is not just more model capacity or more fleet miles. It is a closed loop: collect experience, detect failures or suboptimal behavior, improve the driver, validate the fix in simulation and onboard checks, deploy, and repeat. Thirumalai called this the “Waymo flywheel.” In that description, miles are useful because they feed an improvement and validation system, not because data volume alone guarantees competence.
The implication of Thirumalai’s account is that a generated plan is only useful if a separate system can decide whether it is safe enough to act on.
That structure is becoming familiar well beyond autonomous driving. A model proposes. Another layer checks. A simulator or evaluation harness stresses the system. A runtime layer enforces constraints. Deployment turns into a managed loop rather than a one-time model release.
Waymo’s driver-simulator-critic triad is therefore a useful template for reading the rest of today’s sources. In freight, the autonomous truck is only one piece of a deployment platform. In voice, natural-sounding output is only one piece of a conversational system. In commerce, a fluent shopping assistant is only one piece of a real-time data and prediction network. In startup strategy, a model wrapper is only durable if it becomes embedded in a workflow or infrastructure layer that is hard to replace.
| Domain | Visible AI capability | Surrounding system the sources emphasize |
|---|---|---|
| Robotaxis | Generated driving plans | Simulation, critic, onboard safety checks, validation, deployment loop |
| Freight | Autonomous driving | Routing, charging, loading-site workflows, remote supervision, regulation |
| Voice agents | Natural speech generation | Turn-taking, interruption handling, streaming, tool latency, observability, cost control |
| Commerce | Conversational product discovery | Fresh catalogs, embeddings, consent, bidding latency, retailer data |
| AI startups | Model-powered features | Workflow depth, operating context, distribution, strategic acquirer interest |
The contrast with Tesla matters because it keeps the frame honest. Waymo is not claiming that rivals cannot catch up with a different architecture. Thirumalai’s answer is that safe scaling depends on the whole loop around the driving model. If Tesla or another end-to-end competitor reaches L4 at fleet scale, Waymo’s competitive answer is not a prediction that this cannot happen. It is that the company’s own route to that outcome runs through independent validation, simulation, critique, and real-road learning.


Freight shows why autonomy needs orchestration before spectacle
Einride applies the same logic to logistics. Roozbeh Charli’s argument is not that autonomous trucks alone will transform freight. It is that freight modernization requires a platform coordinating electric trucks, autonomous assets, routing, charging, handoffs, loading-site operations, remote supervision, and regulatory deployment.
That distinction matters because freight is not a demo environment. Large shippers already operate inside dense logistics systems. They cannot simply replace diesel manual trucks with autonomous trucks and expect the rest of the network to absorb the change. Electric vehicles require charging plans. Autonomous vehicles require deployment zones and operating rules. Loading bays still involve people, facilities, exceptions, and site-specific workflows. Remote operators need to monitor vehicles and intervene tactically when edge cases arise.
Charli’s sequencing also makes the infrastructure point. Einride begins with electrification through electric manual trucks, then introduces autonomy into the system. The software platform “sits in the middle,” in his description, orchestrating the technologies and workflows needed to change how fleets operate. The vehicle is one object in a larger operating system.
Regulation is part of that operating system. Charli said the United States has taken a “clear leadership position” on autonomous regulation over the prior 18 to 24 months, especially through state-level frameworks and visible robotaxi deployments. Europe, in his account, is beginning to respond because the US lead creates a pull effect.
That is not a technical footnote. For autonomous freight, permission to operate is a deployment dependency. A company can have capable vehicles and still be blocked from meaningful scale if rules, sites, insurers, customers, and public agencies are not ready to support them.
Labor fits the same pattern. Charli does not describe a system that simply removes humans. He describes a system that moves human work into monitoring, remote supervision, exception handling, and human-facing operational support. Einride’s current deployments, in his account, have vehicles driving fully autonomously while a human operator supervises from a remote station. The operator can help with tactical decisions or interactions around the freight process.
This is a recurring applied-AI pattern: automation changes the shape of work before it eliminates the need for human judgment. The question becomes where the human belongs in the loop, how often they are needed, and what kind of interface lets them intervene without collapsing the efficiency gains.
In freight, as in robotaxis, the impressive capability is not sufficient by itself. The business depends on a managed system that coordinates vehicles, energy, routes, facilities, people, and regulators. That makes Einride’s argument less a rebuttal to vehicle autonomy than a warning against treating vehicle autonomy as the whole category.


Voice AI is the clearest consumer version of the infrastructure gap
Voice is where the gap between model capability and usable system is easiest to hear. Today’s voice sources describe three layers of the same stack: the model substrate, the interaction problem, and the commercial wrapper.
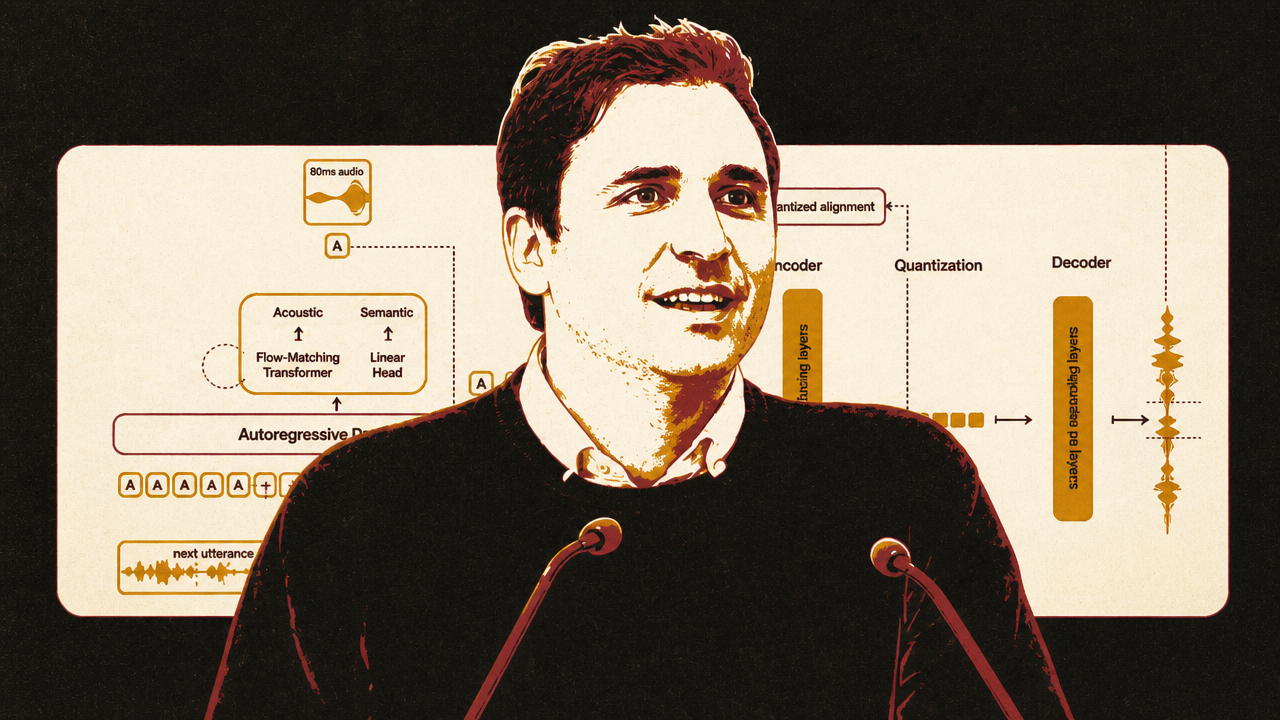
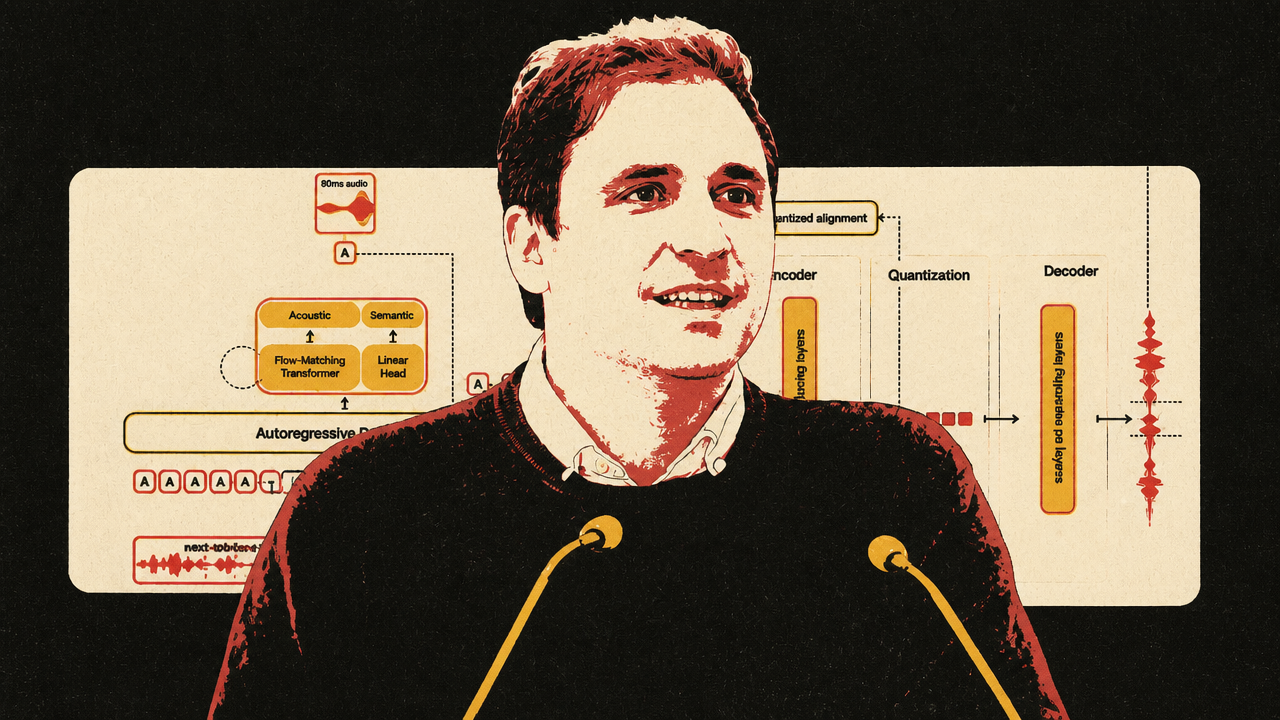
Samuel Humeau’s account of Mistral’s Voxtral TTS shows how text-to-speech is converging technically toward large-language-model-like architectures. Modern systems do not generate raw waveforms sample by sample. Audio is too dense for that. Instead, neural audio codecs compress speech into token-like frame representations that a transformer can model. Voxtral, as Humeau described it, cuts audio into roughly 80-millisecond frames, represents each frame with 37 tokens, and uses an autoregressive backbone to generate audio frame by frame.
Neural audio codecs are what make the LLM analogy practical. Humeau used standard-quality MP3 at 192 kbits/s as a reference point and said Voxtral’s codec operates at 2.2 kbits/s, roughly a 100x compression factor. That compression lets the system model speech as a sequence without throwing away voice, accent, prosody, and other acoustic features the way plain text transcription would.
The latency story is more subtle than many demos suggest. Humeau showed that Voxtral can stream playable audio quickly once it has the full text. But he was explicit that the released system does not yet consume an LLM’s live text stream as the LLM is still writing. In one demo, the apparent overlap came from a small LLM producing text very quickly, followed by streamed audio playback. The next frontier, in his telling, is TTS that can begin speaking as soon as early LLM tokens arrive, rather than waiting for the full answer.
Neil Zeghidour’s critique starts where that model story ends. Better TTS, he argues, is still not real conversation. Many systems are cascades: speech-to-text, then an LLM, then text-to-speech. That architecture is useful and commercially practical, but it strips away much of what makes speech valuable: hesitation, tone, discomfort, backchanneling, overlap, and other paralinguistic signals.
Zeghidour’s benchmark is not whether the voice sounds pleasant. It is whether the system can participate in conversation while doing useful work. He gave three requirements for a “Her”-like interaction: naturalness, intelligence, and empathetic response. Naturalness means low latency and the ability to listen and speak simultaneously. Intelligence means maintaining context, understanding intent, and performing agentic tasks. Empathy means detecting and responding to emotional and social cues in the user’s voice.
His latency critique is especially important for product teams. He said a human-like conversation needs the entire stack — understanding, answer generation, and pronunciation — to fit around a roughly 200-millisecond response window. But tool calls, retrieval, booking flows, search, and other real agent work can add hundreds of milliseconds to several seconds. Zeghidour cited tool-call latency from 500 milliseconds to four seconds in current workflows.
| Voice problem | Why a better voice model alone does not solve it | System response described in the sources |
|---|---|---|
| First-audio latency | Fast playback after full text still leaves waiting if the LLM has not finished writing | Streaming audio now; future streaming-input TTS that consumes live LLM tokens |
| Turn-taking | Half-duplex systems mistake backchannels for interruptions | Full-duplex models or stronger turn-taking and interruption handling |
| Tool delays | Useful agents must call external systems with unpredictable latency | Contextual fillers, parallel tool calls, orchestration that keeps the interaction alive |
| Paralinguistic cues | Transcripts discard tone, hesitation, overlap, and emotion | Speech-native models trained to use voice signal, not just output speech |
| Unit economics | Cloud TTS can dominate costs for heavy voice usage | On-device or cheaper inference where possible |
Zeghidour used full-duplex conversation as the sharpest dividing line. A half-duplex model listens or speaks, but not both at once. Human conversation is messier: people overlap, cough, affirm, interrupt, and signal attention while the other person continues. Zeghidour said overlap can reach up to 20% of speaking time and showed how half-duplex systems can misread simple backchannels such as “mhmm” or “yeah” as interruptions.
Moshi, the full-duplex research system developed at Kyutai, proved for him that conversational flow can be improved. But he was equally clear about what it did not solve. It had no tool calling, lacked production observability and reliability, did not offer the controls product teams need, and did not meaningfully solve empathy. His updated view is pragmatic: cascaded systems remain useful because they compose with today’s text-first agents, even if they are not the endpoint for natural voice interaction.
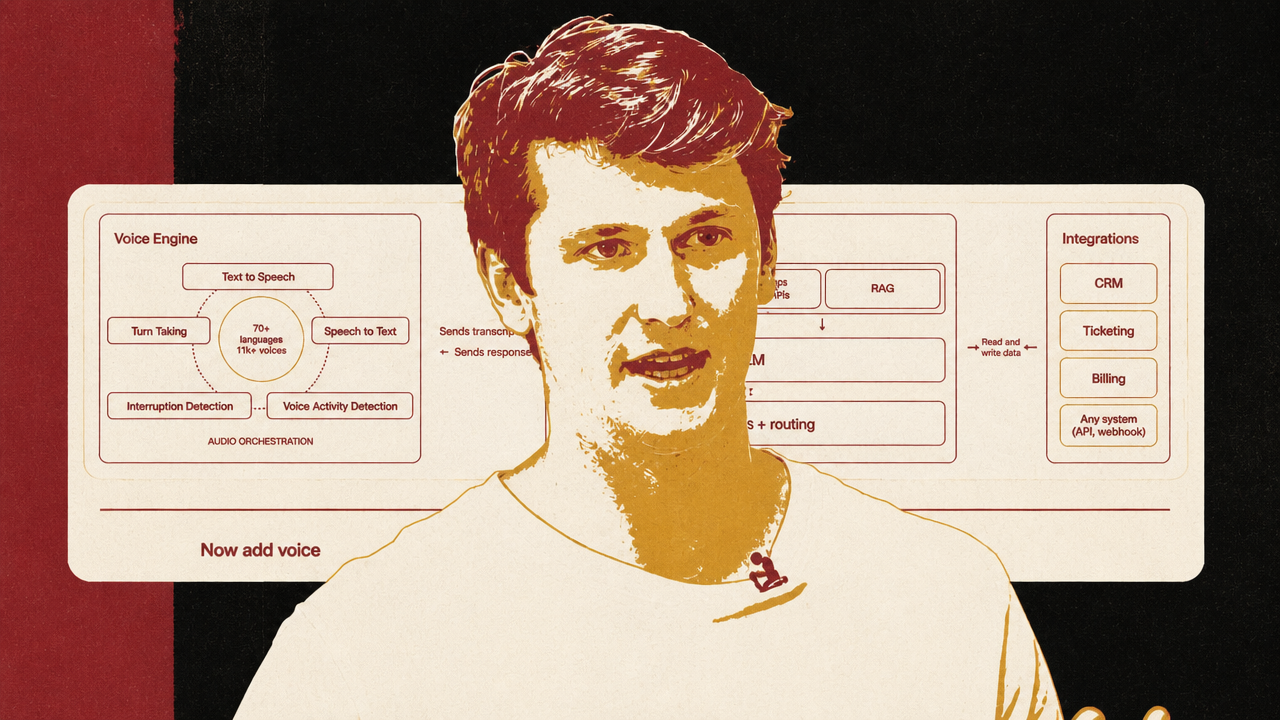
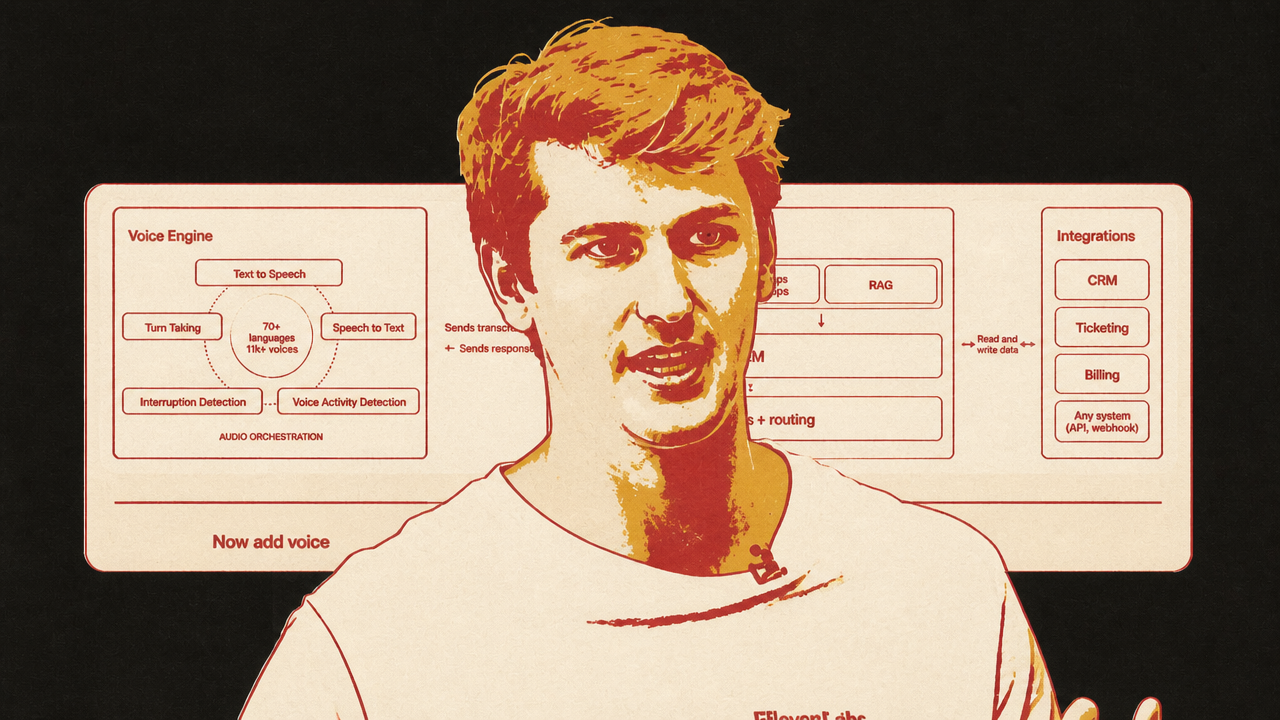
That is where ElevenLabs’ Voice Engine fits. Luke Harries presented it not as a replacement for existing agents, but as an audio wrapper around them. Many teams already have chat agents with LLM logic, RAG, tools, business rules, routing, and evaluations. Voice Engine is aimed at the teams that do not want to rebuild that orchestration inside a new managed platform just to add speech.
Harries separates the voice agent into layers. Voice Engine handles speech-to-text, text-to-speech, voice activity detection, turn-taking, interruption handling, and channels such as web, phone, or meetings. The customer’s existing backend keeps the system prompt, knowledge base, RAG, LLM, workflows, routing, and integrations. The wrapper sends transcripts into the existing agent and returns the agent’s response through the voice layer.
That packaging is the near-term commercial answer to Zeghidour’s deeper critique. It does not claim to solve full-duplex empathy or all paralinguistic understanding. It does acknowledge that voice requires its own orchestration layer. Companies do not just need a better TTS endpoint; they need interruption detection, turn boundaries, streaming, channel support, and a way to preserve the agent logic they have already built.
The three voice sources therefore do not contradict each other as much as they occupy different levels of the stack. Mistral explains why speech generation is becoming more model-like and streamable. Gradium argues that speech generation is being confused with conversation. ElevenLabs shows how the market is packaging the missing interface layer around existing agents.


Commerce AI exposes the data and latency constraints behind agentic discovery
Criteo’s account of commerce AI brings the same infrastructure theme into a domain where AI has already been operating for years. Diarmuid Gill and Liva Ralaivola describe modern ad tech as a millisecond-scale prediction system: decide whether to bid, what to bid, what product to show, and how to render it, using limited anonymous commerce signals and learned representations.
That is not the public’s usual image of AI, but it is applied AI in production: billions of predictions per day, under strict latency constraints, with seasonal traffic spikes and commercial consequences. Gill said Criteo’s system must be accurate, fast, and able to do this billions of times a day. Ralaivola frames one core task as a binary classifier — should the system bid on this impression or not? — while the real system also estimates click probability, purchase likelihood, product relevance, and expected value.
The technical evolution mirrors the broader AI shift from handcrafted features to learned representations. Criteo moved from large sparse vectors and logistic regression over manually engineered features toward dense learned embeddings and foundation-model-like representations for products, user timelines, and other commerce objects. Ralaivola said the company is building several foundation models to compute embeddings that other teams can reuse as starting points for new systems.
The LLM-commerce question is what happens when product discovery moves into conversational assistants. Gill and Ralaivola do not frame LLMs as replacing the ad-tech infrastructure. They frame LLMs as a new surface that needs that infrastructure. A general model may reason well and recommend plausible products, but commerce data changes too fast for static model knowledge. Prices move. Inventory disappears. Catalogs update. Promotions change. A conversational answer that recommends an out-of-stock product or stale price is not just imperfect; it breaks trust.
Freshness is therefore the bottleneck. Gill said Criteo ingests product data daily, sometimes multiple times per day. In the hybrid architecture he expects, the LLM supplies language and conversational reasoning while a commerce system supplies current product data, relevance signals, and matching under operational constraints.
This connects directly to voice and agents. A voice shopping assistant may sound natural. A text assistant may present recommendations fluently. But the surface is only useful if the system behind it can answer with products that exist, prices that are current, inventory that is available, and personalization that respects consent. The agentic interface raises the standard for infrastructure because the user may treat the assistant’s answer as a recommendation, not a list of links to verify manually.
Privacy and control are not separate from performance in Criteo’s telling. Gill argues that advertising works only when the value exchange is trusted: users get relevant experiences, advertisers reach likely customers, and publishers or services receive funding. If advertising feels creepy, he said, it will not work. Ralaivola adds that conversational agents may receive far more user context than traditional ad systems, making consent, hallucination control, and trustworthy machine learning more important.
Human oversight also reappears. Ralaivola’s broad principle is “human in the loop,” but not in a symbolic sense. The design problem is where the human belongs: too much automation strips users or advertisers of agency; too many required human decisions destroy the benefits of automation. In creative generation, bidding systems, and agentic discovery, the useful system has to decide what the machine can do at runtime and where humans must retain control over brand, consent, and judgment.
Criteo’s strongest relevance to the day’s theme is that it makes the invisible deployment machinery legible. LLMs may change the shopping interface from search boxes and ad slots to conversation. But the hard part remains accurate matching under real-time constraints with fresh, permissioned, operational data.


The startup implication: infrastructure depth may decide who survives
Elad Gil’s argument supplies the capital-market consequence of the same shift. He says many AI companies should consider selling within the next 12 to 18 months, not because AI is weak, but because most companies formed during major technology cycles do not survive them.
His filter is durability. In every major cycle, Gil said, “90, 95, 99%” of companies go bust. He used the internet bubble as the analogy: by his estimate, roughly 1,500 to 2,000 companies reached the public markets around that era, and perhaps a dozen or two endured. For AI, he argues that founders need to ask whether they are building one of the durable companies or whether they are in a window where growth, buyer interest, and market enthusiasm may produce the best exit.
That advice is selective. Gil explicitly excludes companies he sees as durable, including leading foundation-model labs such as OpenAI and Anthropic. At the foundation layer, he expects something closer to an oligopoly than a monopoly: a handful of major labs and cloud-aligned providers, unless one model provider pulls decisively ahead. But most application companies, in his view, need a different defense.
The relevant defense is not simply “we use AI.” It is workflow depth. Gil asks whether improving underlying models make the application more valuable to customers, or whether they make the product easier for a lab, incumbent, or competitor to copy. He looks for companies that become deeply embedded in customer processes, route work through their systems, manage change inside organizations, and potentially become systems of record. Data can help, but he warns that generic data-moat arguments are often overstated unless the product is actually capturing proprietary operational context that matters.
That maps cleanly onto the day’s case studies. Waymo’s claimed durability is not only a driving model; it is validation infrastructure, simulation, a critic, and accumulated deployment loops. Einride’s is not an autonomous truck; it is freight orchestration across energy, routes, sites, people, and regulation. ElevenLabs’ Voice Engine is not just TTS; it is an audio layer around existing agent workflows. Criteo’s is not a conversational shopping answer; it is retailer data, embeddings, consent, latency systems, and a commerce network. Zeghidour’s critique of voice demos points in the same direction: natural output alone is exposed if the product cannot handle turn-taking, tools, reliability, privacy, and cost.
Gil’s acquisition logic also reflects this infrastructure frame. If an AI startup is a feature likely to be absorbed by model progress or platform vendors, the best buyer may appear before the weakness is obvious. If it is deeply embedded in a workflow or controls infrastructure a large company needs, it may be worth building for the long run. The decision is not whether AI is transformative. It is whether the company’s role in that transformation is durable.

