Text-to-Speech Models Are Converging on LLM-Style Architectures

Samuel Humeau of Mistral argues that modern text-to-speech has converged on an architecture that resembles large language modeling: an autoregressive transformer generates compressed audio tokens frame by frame, rather than raw waveform samples. Using Mistral’s open-weight Voxtral TTS model as the example, he says neural audio codecs make that possible by reducing dense speech signals to token-like representations a transformer can handle. The remaining latency frontier, in his account, is not just streaming playable audio early, but letting TTS consume an LLM’s text stream as it is still being written.
Text-to-speech has converged on the shape of language modeling
Samuel Humeau’s central claim is that modern text-to-speech has begun to look structurally familiar: the dominant pattern is now an autoregressive decoder backbone generating audio as a sequence, in much the same broad style that large language models generate text tokens. The reason is not that audio is text, but that the field has learned to turn audio into something a transformer can model: compressed, token-like units emitted one frame at a time.
Humeau framed the talk around Mistral’s newly released text-to-speech model, Voxtral-4B-TTS-2603, described on the slide as an open-weight, 4B-parameter TTS model supporting nine languages, released under Apache 2.0 for the model weights, with reference voices licensed under CC-BY-NC 4.0. He called the model “extremely strong” and “fast, instantly adaptable,” and used it as the running example for the architecture discussion.
The practical pressure behind the architecture is voice agents. Humeau acknowledged offline use cases such as “listen to the article,” but said the current “king use case” for TTS is as the speech interface to a chat agent. The classic pipeline is simple: speech-to-text transcribes the user, an LLM produces text, and text-to-speech renders the answer as audio. In that pipeline, latency is not a peripheral metric. It determines whether the interaction feels like a conversation or a queue.
On the input side, latency can be reduced by running speech-to-text in real time, so that when the system detects the end of the user’s turn, the transcript already exists. Humeau focused on the output side: the TTS system should begin emitting the first playable audio packets before the full audio has been generated. If the LLM can stream text, the eventual target is more aggressive still: a real-time text-input TTS system that begins speaking as soon as the first LLM tokens arrive.
That final version is not what Mistral’s released model does. Humeau was explicit about that distinction later in Q&A. Voxtral’s released TTS model belongs to the category that takes the full text prompt first, then generates audio. But even within that constraint, the audio output itself can be streamed: the first audio arrives early enough to play while later audio is still being computed.
The latency trick is to stream audio, not necessarily to stream text
The live demonstrations were meant to isolate that distinction. Humeau showed a small web app he had built for the talk, selecting a voice named “Paul_en_us” and generating speech from a short passage. He first played an actual recording of Paul, then generated new text in Paul’s voice. The point was not only that the voice clone sounded similar, but that the generated audio began with an initial packet before the entire utterance was complete.
The same property made the voice-agent demo feel responsive. Humeau combined speech-to-text, a Mistral LLM, and Voxtral TTS into a simple agent with conference schedule information in its context. He asked: “Hey Paul, can you tell me what’s the title of the session at 12:20, please?” The assistant answered in Paul’s voice: “The session at 12:20 PM is titled ‘Reachy mini: giving a body to AI’ by Andres Marafioti.” He then asked what the 11:15 session was, and the assistant answered with the title “Beyond Transcription: Building Voice AI that Actually Understands Conversations” by Hervé Bredin. When he asked whether the agent enjoyed it as much as he did, it replied that it did not have personal experiences or emotions, but was glad he enjoyed it.
The demonstration could easily be mistaken for simultaneous LLM generation and speech generation. An audience member raised exactly that point: if the model takes all the text first, why did the voice-agent sample seem to generate text and audio at the same time? Humeau corrected the impression. In that demo, the text was produced “in one go”; he was using a small LLM that responded very fast, and then audio was produced afterward. The perceived responsiveness came from streaming the audio output, not from truly consuming a live stream of LLM tokens as TTS input.
That distinction matters because it separates two latency problems. One is already handled in the released system: once text is available, generate and play early audio before finishing the whole waveform. The other remains the next meaningful win: accept a stream of text from the LLM and begin speaking before the LLM has finished its complete answer.
Humeau reported a concrete serving number for the current model: excluding network effects, on a single GPU, the model can produce the first playable audio about 70 milliseconds after text input at concurrency 1.
| Concurrency | Latency | RTF | Throughput | Wait rate |
|---|---|---|---|---|
| 1 | 70 ms | 0.103 | 119.14 char/s/GPU | 0% |
| 16 | 331 ms | 0.237 | 879.11 char/s/GPU | 0% |
| 32 | 552 ms | 0.302 | 1430.78 char/s/GPU | 0% |
The numbers supported his practical point: for short utterances, a fast LLM plus low first-audio latency can look almost like full overlap. But for longer generations, the limitation becomes visible. If the user asks the agent to generate a full page of text, Humeau said, “it will be nice if I don’t have to wait the end of the text generation to voice it out.”
Audio must be compressed before a transformer can model it
The architectural problem starts with the density of audio. A waveform is a physical pressure signal measured thousands of times per second. Historically, speech generation systems have ranged from stitching recorded words together, to neural systems that generated samples one after another, to systems that generated the whole audio at once. Humeau argued that for conversational systems, generating the whole audio at once is less attractive because the beginning of the audio should be available early.
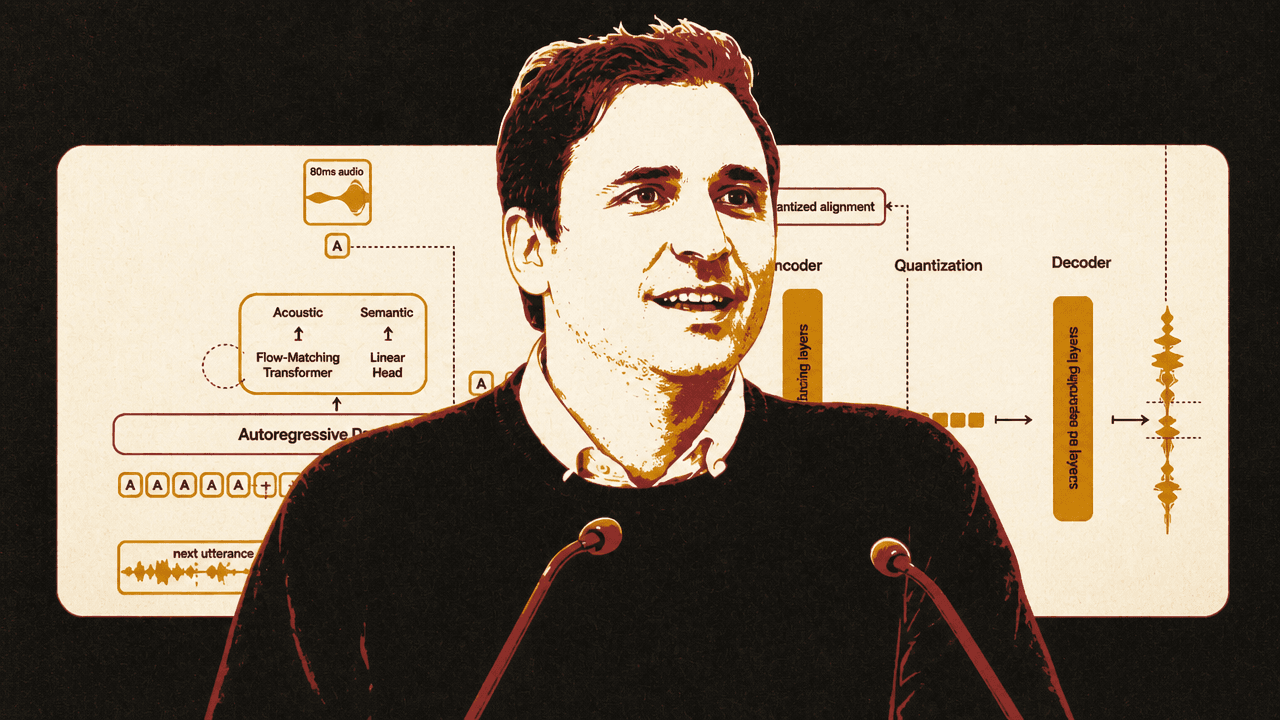
But generating raw samples autoregressively is not viable either. The modern compromise is to generate patches or frames of audio, represented as tokens. Humeau described the desired system as an encoder that turns a frame of audio — “something like 80 milliseconds” — into token-like units, and a decoder that turns those units back into raw audio.
For text, tokenization is comparatively easy: words can serve as crude tokens, and better tokenizers work well. For audio, the information rate is much higher. Humeau used simple bit arithmetic to show why. A token drawn from a vocabulary of 1,024 values carries 10 bits of information. Standard-quality MP3, by contrast, is around 192 kilobits per second. Text captions are vastly smaller, on the order of tens of bits per second, because they discard nearly all acoustic information.
Humeau demonstrated the difference with a bitrate tool in the same app. It used live speech-to-text, tokenized the transcript with an approximately 100,000-token vocabulary, and computed bitrate as tokens times log2 of vocabulary size divided by elapsed time. The visible app read 43.9 bit/s during the demo, while Humeau joked that despite being “a very competitive person” and “very good at speaking,” he was “barely 15 bits per second of actual information.” Either way, compared with roughly 200,000 bits per second of audio, text is tiny.
The goal of a neural audio codec is therefore not to reduce speech to text. A subtitle track drops the voice, accent, prosody, speaker identity, and acoustic detail. A TTS codec must preserve enough of those features to reconstruct lifelike speech while reducing the bitrate enough for a sequence model to handle. Humeau said these codecs typically reduce audio to a few thousand bits per second. In Voxtral’s case, the slide listed 2.2 kbits/s, about a 100x compression factor relative to standard MP3.
In the Voxtral setup Humeau described, the system cuts audio into 80-millisecond pieces, or 12.5 frames per second. Each frame is represented by 37 tokens, producing roughly 460 tokens per second. The codec is trained to reconstruct large amounts of audio through a bottleneck that forces each frame to be decomposed into discrete tokens. Reconstruction losses and adversarial losses guide training, and for some tokens the system is guided to retain text information so that text can be reconstructed from them.
| Representation | Rate or structure | Purpose |
|---|---|---|
| Standard-quality MP3 | 192 kbits/s | Reference point for dense audio signal |
| Text captions | ~50 bits/s | Semantic text with most acoustic information removed |
| Voxtral codec | 2.2 kbits/s | Compressed audio representation retaining acoustic features |
| Voxtral frames | 12.5 frames/s | Audio divided into roughly 80 ms chunks |
| Voxtral tokens | 37 tokens/frame; ~460 tokens/s | Tokenized representation modeled by the generation system |
The mainstream backbone predicts frames, while smaller modules handle per-frame detail
Once audio has been converted into token-like units, the next question is how much work the large backbone should do. Humeau said a naive approach would place the roughly 500 audio tokens per second one by one in a long sequence and let the main transformer generate them autoregressively. That would require many steps through the largest and most expensive part of the model.
The pattern Humeau described as common is to use one step of the main autoregressive backbone per audio frame, not per token. A smaller model then generates or recomputes all the tokens inside that frame. He described this smaller module as typically a depth transformer: the backbone advances frame by frame, while a vertical per-frame model handles the multiple codebook tokens representing the acoustic content of that frame. This preserves a high-information representation without requiring the large backbone to take a step for every codec token.
Voxtral differs from that common pattern in the per-frame generation mechanism. Humeau said Mistral’s released model does not use the vanilla depth-transformer approach for the 37 tokens per frame. Instead, it generates those tokens at once using a diffusion-like method, specifically a flow-matching model. The slide contrasted “37 tokens to generate via depth-transformers” with “8 function evaluations” in the flow-matching setup.
He did not spend much time on that deviation, but the implication was clear enough: the high-level industry pattern is autoregressive frame-by-frame generation over compressed audio units, but implementations still vary in how they fill in each frame. Voxtral uses a 4B-parameter backbone and a flow-matching transformer for the acoustic portion, with a semantic linear head shown in the diagram.
Conditioning is where implementations diverge
Humeau separated “speech generation” from actual text-to-speech by making conditioning the central issue. A model that only generates plausible audio is not yet a TTS model. It must be conditioned on text, and often on a speaker reference, style, language, or other control signals. He said this is where there is “way more” variation across labs, papers, and implementations.
He grouped systems into two broad tendencies. In the first, the model receives all relevant context at the beginning — the voice reference and the complete text to pronounce — and then generates audio. Voxtral’s released model belongs to this category. Humeau described its context as a few seconds of audio for the voice to clone, followed by the text to pronounce.
In the second tendency, the model receives additional context as audio is being produced. This is the class of architectures meant for streaming text input, where an LLM is still producing tokens while the TTS system is already speaking. Humeau described several possible patterns, including generating segments independently and stitching them together, interleaving audio and text tokens in the same sequence, and dual-stream architectures where text and audio streams are blended during inference.
He was careful not to overstate Mistral’s direction. In response to a question about “the next steps on the interleaved function,” Humeau clarified that he had not said Mistral’s next step would be interleaving. He had said only that several patterns exist for handling a text stream instead of a finite block of text. Interleaving is one option; another he mentioned was delayed sequence modeling. He said it remains unclear, at least to him, which architecture is best.
The benefit, however, is straightforward: lower latency. Once the LLM emits the first bit of text, a streaming-input TTS system could begin voicing it. That would turn the pipeline from a sequence of waiting periods into overlapping work: speech-to-text completes or streams the user’s turn, the LLM begins producing an answer, and TTS begins speaking before the LLM has finished writing the whole response.
Voice cloning is becoming easy enough to change brand behavior, but Mistral withholds the open cloning path
The demo also showed how little reference audio is needed to adapt a voice. Humeau said Voxtral can clone a voice from “a few seconds” of audio. He played Paul’s reference voice and then generated new text in that voice. He also showed cross-language inference: using a French voice reference, the model generated English with the recognizable voice and a strong French accent, which Humeau, as a French speaker, said he enjoyed. He then cloned his own voice from a short “Hi, this is Sam” recording and used it to generate the same sample text, joking that this would let him discuss complicated problems with himself “in my time of delusion and at the peak of my ego.”
The broader point was not just a demo of mimicry. Humeau argued that as voice impersonation becomes easy to configure, “vocal identity” will become a more general branding concern. Large companies already care about the voice of the company in advertising; he expects that concern to spread, much as companies define the visual identity of a website today.
The open-release boundary matters here. When asked whether voice cloning was entirely open, given that the model weights are open, Humeau answered that there is “a small asterisk.” Mistral did not release the encoder part needed for users to clone arbitrary voices. Users can run the TTS model and use the open voices Mistral provides, and the company may provide more voices in the future. But the missing encoder is, in Humeau’s words, “the only thing that is missing for you to clone your own voice.” For now, Mistral serves that capability proprietarily because it “just didn’t want to give everybody the ability to clone any voice.”
That answer creates an important boundary around “open-weight” in this release. The TTS model is open-weight, and reference voices are available under their stated license, but the arbitrary voice-cloning path demonstrated on stage depends on a component Mistral has not released.
The cascade remains useful because speech can be just an interface
An audience question contrasted the cascade architecture — speech-to-text, LLM, text-to-speech — with native voice-to-voice systems associated with large labs. Humeau’s answer was pragmatic. On the consumer side, he said, users will always feel as if they are speaking to one system that hears them and responds. The difference is architectural.
His view was that systems can go “very, very far” by using speech as an interface to a central LLM. The reason is partly leverage: those central LLMs are already extremely capable and do many things. If speech is an interface layer, the same voice interface can be applied to many agents that have already been released. That gives the cascade an advantage, especially if the TTS side eventually consumes streamed text tokens from the LLM.
This was not a claim that native voice-to-voice architectures are irrelevant. Humeau did not dismiss them. But he argued that the cascading design has a long runway because it composes with existing text agents and because much of the user experience problem can be solved by careful streaming at the boundaries. The architecture may remain modular while the experience feels unified.