Applied AI Moves From Models To Systems
AI Engineer Melbourne speakers, OpenAI CFO Sarah Friar, Microsoft, NVIDIA, GitHub, Lovable, and others described a market where the model is only one part of the product. The throughline is a shift toward harnesses, routing, evals, trust systems, compute supply, and cost discipline as the pieces that determine whether AI usage becomes shipped value.
The model is no longer the product
Applied AI’s center of gravity is moving outward from the model. The cleanest formulation came from AI Engineer Melbourne, where Shawn Wang contrasted Greg Brockman’s 2023 line, “the model is the product,” with the 2026 update: “the model alone is no longer the product.” The model still matters. But the commercial product now includes the harness, routing layer, memory, state, evals, deterministic tools, latency budget, deployment path, product surface, and cost controls around it.
George Cameron’s Artificial Analysis benchmark made the point concrete. In the coding-agent comparison he presented, the same model behaved very differently depending on the surrounding system. “Claude Code + Claude 3.7” scored 97 on the Coding Agent Index shown, while base “Claude 3.7 Sonnet” scored 61. Cursor Agent and Copilot V2 using Claude 3.7 scored 83. The model was not irrelevant; the harness changed the result.
| Setup | Score shown | What the comparison implies |
|---|---|---|
| Claude Code + Claude 3.7 | 97 | The strongest result came from model plus coding-agent harness. |
| Claude Code + Claude 3.5 | 92 | A prior model in a strong harness beat newer-model setups in weaker harnesses. |
| Cursor Agent + Claude 3.7 | 83 | Product architecture shaped the same base model’s usefulness. |
| Copilot V2 + Claude 3.7 | 83 | The benchmark treated the agent system as the unit of comparison. |
| Claude 3.7 Sonnet base | 61 | The raw model lagged the agent products built around it. |
That is the applied-AI systems argument in miniature. Once a model is embedded in a product, the practical metric becomes cost, capability, latency, and outcome — not leaderboard position alone. Cameron argued that frontier progress remains fast and that open-weight models remain useful even if they trail proprietary frontier models by months. But his more operational claim was that the cost of reaching a given intelligence tier can fall by 10–100x over 6–18 months, while frontier-agent workloads can also multiply cost through many tool calls and reasoning turns. The product problem is choosing the right point on the curve.
Sarah Sachs described Notion’s version of that problem as “win on the product, not the token.” Notion’s Auto model routes most AI traffic across models rather than locking the product to one provider. Sachs said Notion changes its default model roughly every three to four weeks, runs open-weight traffic in production, evaluates providers on whole-task value, and uses deterministic Workers when a repeated task can be handled by an API call, shell command, state machine, or small code action instead of another reasoning call. For some repeated tasks, she said Workers reduced token costs by up to 80%.
The same architecture-first argument appeared in two more specialized settings. Igor Costa argued that coding agents fail over longer horizons because the industry often treats context and memory as the same thing. Larger context windows help, but they do not solve whether an agent’s memory is correct, current, shared across agents, or verifiable. His warning was that agent memory becomes a reliability boundary when agents work for days or months rather than turns.
Vamsi Ramakrishnan made the voice-agent version of the same claim. In real-time voice, the latency budget is the architecture. A system handling consent, turn boundaries, tool use, and call-state transitions cannot rely only on a speech-to-speech model. It needs low-latency observers, typed state, deterministic checks, and governed flows. A regex or state machine may be the right answer when the alternative is a costly, variable model call that misses a millisecond-scale interaction window.
Geoffrey Huntley pushed the point into organizational design. Cheap execution does not make a fragmented organization coherent. If a company has duplicated sources of truth, wasteful processes, unclear ownership, or one repository per component, more tokens may simply amplify the mess. In his framing, the scarce skill shifts toward deciding what should exist and building the system around the work.
The durable advantage described across the Melbourne talks is not model access alone. It is the ability to decide when to use which intelligence, when not to use a model at all, and how to turn the result into a reliable product.


Compute scarcity is becoming a strategy constraint
If the product boundary has moved outward, the capital boundary has too. OpenAI CFO Sarah Friar framed the company’s next phase less as an IPO-timing story than as a compute-scarcity story. OpenAI raised $122 billion in committed capital, according to Friar and the on-screen materials, to preserve optionality across compute, products, cloud providers, chips, and infrastructure models.
Friar’s strongest operational claim was that 2026 compute is already difficult to buy and 2027 is “pretty limited.” She described OpenAI as climbing a “vertical wall of demand” while navigating bottlenecks in energy, land, power, regulation, racks, chips, memory, and talent. The Saline, Michigan one-gigawatt data center she discussed will not produce compute until late 2027 or early 2028, and she said the areas where she feels most short are now 2030, 2031, and 2032.
That time mismatch matters. AI products are becoming more multimodal, real-time, personalized, and agentic. Those products require inference capacity, not only training clusters. Friar said OpenAI had to make hard choices around video because it lacked enough compute, while also arguing that speech, multimodality, and natural interfaces will increase real-time demand. The interface strategy and the infrastructure strategy are linked.
OpenAI’s response is a multi-cloud, multi-chip, multi-financing stack. Friar said OpenAI now sits on top of Oracle, CoreWeave, Microsoft, Google Cloud, AWS, and smaller neo-scalers. Nvidia remains its priority chip partner, but she also named AMD, Cerebras, and OpenAI’s own chip work with Broadcom. Cerebras, she said, is already useful for low-latency workloads such as real-time coding. That diversification is not a generic procurement move. It is an attempt to avoid a single chokepoint in a market where compute supply is becoming a strategic constraint.
| Constraint | Friar’s framing | Business consequence |
|---|---|---|
| Compute availability | 2026 is hard to source; 2027 is limited. | Capital is raised years ahead of product demand. |
| Infrastructure inputs | Energy, land, power, regulation, racks, chips, memory, talent. | AI strategy depends on supply-chain execution, not only product demand. |
| Provider concentration | OpenAI moved beyond a one-cloud, one-chip setup. | Optionality becomes a financing and operating goal. |
| Product interface | Multimodal and agentic products require real-time inference. | More useful interfaces can increase compute pressure. |
Bloomberg’s broader financing discussion showed the same pressure spreading beyond OpenAI. Alphabet’s planned $80 billion equity raise was framed as a sign that AI infrastructure spending is now large enough to reshape balance sheets. The proposed package included a $10 billion Berkshire Hathaway investment, $30 billion in public offerings, and a $40 billion at-the-market program. Bloomberg Intelligence’s Robert Schiffman called the move “wildly bullish” because equity issuance at that scale implies confidence that AI infrastructure returns can justify dilution.
Anthropic’s confidential IPO filing, SpaceX’s planned listing, and OpenAI’s expected public-market path were discussed as a sequencing problem for public investors rather than a simple race. Shirin Ghaffary noted that Anthropic’s filing lacks public financial details and does not guarantee timing. Emily Zheng of PitchBook said the prospective values are in “uncharted territory,” with estimated 2026 U.S. VC-backed IPO value dwarfing recent years if SpaceX, Anthropic, and OpenAI all come through. The market may have demand for core AI exposure, but the public filings will have to reveal how revenue, compute commitments, and margins actually fit together.
The financing pressure also reaches suppliers. Memory constraints came up as a core AI bottleneck. Arm CEO Rene Haas argued that memory companies cannot reasonably take all expansion risk alone after losing money in the prior downcycle; he suggested shared investment and shared risk with the hyperscalers that consume the capacity. HPE CEO Antonio Neri, meanwhile, said enterprise demand for AI infrastructure is durable enough that HPE pulled forward guidance, with customers bringing AI on-premise for compliance, governance, privacy, and security.
The common thread is not that every large AI financing will work. It is that AI infrastructure now shapes balance sheets, IPO timing, supplier risk, and enterprise deployment choices. The model race is still visible, but the financing race is about securing the physical capacity to turn models into products.




Agentic workloads are redesigning the machine underneath
The agentic shift is not only a UX category. Microsoft and NVIDIA described it as a workload that changes PCs, data centers, operating systems, developer tools, and the physical design of AI infrastructure.
At Microsoft Build, Jensen Huang told Satya Nadella that the PC is evolving from a tool used directly by a person into a tool an AI assistant can operate autonomously. RTX Spark was presented as local hardware for that pattern: a machine with 128GB of memory and a petaflop of AI performance, able to fit large local models and let an assistant work on code, designs, or other tasks while the user is elsewhere. Nadella framed the edge version as “unmetered intelligence right at the edge.”
The cloud version is larger but structurally similar. Huang said Hopper was built for pre-training, Grace Blackwell for training, post-training, reasoning, and inference, and Vera Rubin for a world where AIs are agentic. In his framing, agents are impatient. They need low-latency iteration, secure access to memory and tools, and data centers matched to the AI system rather than generic capacity. Microsoft’s Fairwater data-center design and NVIDIA’s rack-scale systems were presented as co-designed pieces of that workload.
NVIDIA’s Vera Rubin announcement made the infrastructure concrete. NVIDIA describes Vera Rubin as a multi-rack pod-scale “AI factory” for agents, not simply as a faster accelerator. The company breaks the system into five connected rack-scale roles: NVL72 for reasoning and planning, Vera CPU for orchestration, Groq 3 LPU/LPX for ultra-low-latency token generation, Vera BlueField-4 STX for storage and memory processing with security, and Spectrum-X SFX for AI networking.
| Layer | Agentic role | Why it matters |
|---|---|---|
| NVL72 | Reasoning, planning, context understanding | Agents need high-throughput intelligence for multi-step work. |
| Vera CPU | Orchestration, memory movement, tool launching | Agents create management work around accelerator output. |
| Groq 3 LPU / LPX | Low-latency token generation | Fast iteration matters when agents call tools and sub-agents repeatedly. |
| BlueField-4 STX | Storage, memory, in-silicon security | Agentic systems need protected long-term and working memory. |
| Spectrum-X SFX | AI networking | Rack and pod-scale systems depend on low-latency movement across components. |
DSX pushes the same systems logic into power control. NVIDIA’s DSX MaxLPS claim is that a one-gigawatt AI factory can support 399,096 GPUs with MaxLPS versus 274,968 without it, by dynamically allocating power, smoothing peaks, recovering stranded watts, and coordinating cooling and grid responsiveness. NVIDIA’s proposed metric is not just installed GPUs. It is reliable tokens or useful compute per watt inside a real power envelope.
Arm’s Rene Haas added a useful counterpoint from the CPU side. Accelerators are the “token factory,” he said, but agents create persistent work around distributing, managing, orchestrating, and delivering those tokens. Arm’s March estimate was that future systems may need 4x CPU cores in the same power envelope. Haas treated the exact number as uncertain, but the direction as clear: agents do not run on accelerator throughput alone.
Orchestration is becoming a first-order infrastructure job. That is why Microsoft and NVIDIA talk about PCs, racks, data centers, networking, confidential computing, and software acceleration in one breath. Agentic AI is physical. It reaches chips, CPUs, storage, cooling, grid behavior, and the manufacturing systems needed to assemble them.








The ROI test is shifting from usage to shipped value
The necessary skepticism is not whether AI is being used. It is whether usage becomes shipped value.
Alex Kantrowitz and Ranjan Roy focused on the gap between token consumption and demonstrable output. Kantrowitz cited EntelligenceAI data, discussed in the Wall Street Journal context, saying that among companies using advanced AI coding tools, only 18% of token spending was translating into shipped coding products that reached real users. EntelligenceAI was described as aggregating data from more than 2,000 companies using advanced AI tools for coding.
That number is sharper than anecdotes about companies exhausting AI budgets or engineers burning tokens. It asks whether coding-agent spend is changing what customers or employees can actually use. Uber’s Andrew Macdonald, as cited by Kantrowitz, said higher token usage did not yet map cleanly to a proportional increase in useful consumer features. If a technically capable company struggles to draw that line, less technical companies should not assume the measurement problem will solve itself.
Roy’s term for the failure mode was “token maxing”: organizations encouraging aggressive AI usage without cost visibility, workflow discipline, or a clear definition of useful output. He argued that some early waste is rational if companies identify what works and optimize. Passing a giant CSV into a model, for example, may later become a structured retrieval workflow using only relevant JSON chunks, cutting token use by 70% or 80%. But experimentation becomes risky when capital markets, internal culture, and vendor economics reward usage before value is proven.
Kantrowitz connected that concern to circular financing. Cloud providers invest in AI labs; labs spend heavily on cloud compute; the cloud providers book revenue and mark up private stakes; private valuations support future financings and IPO expectations. Roy did not call this unethical. He argued that it can become reflexive if end-user value does not arrive fast enough to support the infrastructure, backlogs, and valuations built around it.
Fine-tuning is one constructive answer, but only under the right conditions. Benjamin Cowen argued that fine-tuning is becoming a normal maturity stage for AI products when generic APIs no longer match a product’s unit economics, latency requirements, throughput needs, or domain-specific quality metric. His trigger list was practical: API costs overwhelm revenue, evals stop improving through prompting, or shared frontier endpoints cannot meet enterprise constraints. His warning was equally practical: if the product lacks data or mature evals, it is probably not time to train.
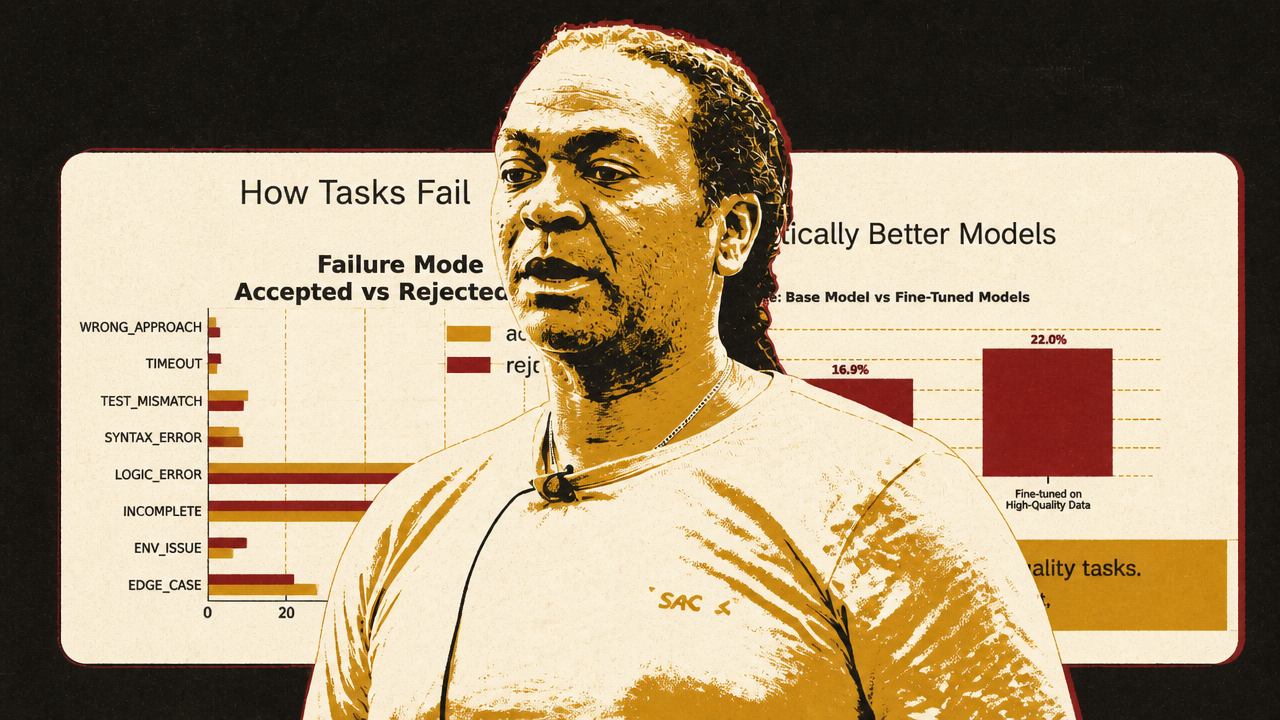
Snorkel’s Kobie Crawford supplied the data-quality caution. In Snorkel’s Terminal-Bench-style experiment, the same base model, Qwen3-8B, was trained with the same compute budget and task count. Low-quality rejected tasks improved average test pass rate from 15.6% to 16.6%. High-quality accepted tasks improved it to 22.8%, a 6.2 percentage-point uplift. Crawford’s point was not simply “more data.” It was that well-specified, reliable tasks produce learnable failures, while ambiguous prompts, broken environments, and test mismatches create noise.
| Question | Weak answer | Stronger answer described across the articles |
|---|---|---|
| Are people using AI tools? | Count tokens, seats, or chats. | Measure whether outputs ship to real users. |
| Are models good enough? | Compare frontier leaderboards only. | Evaluate product-specific quality, latency, and cost. |
| Should we fine-tune? | Train because APIs are expensive. | Train when evals, data, and product-specific metrics show a plateau or economics break. |
| Do we need more tasks? | Add volume. | Use tasks with clear specs, reliable environments, and failures tied to capability gaps. |
The balanced reading is that AI coding and agents can create value, but value is no longer proven by usage. It depends on measurement discipline, evals, routing, cost controls, and data quality. Token consumption is an input. Shipped product is the test.





Software platforms are becoming trust and feedback systems
At the software layer, the systems phase becomes operational. GitHub COO Kyle Daigle described the agent era as a stress test for the platform’s core assumptions: commits, pull requests, Actions, permissions, packages, stars, dependency management, and trust.
GitHub’s load profile is already changing. Daigle said GitHub had 1 billion commits in 2025 and, by April, was seeing 275 million commits per week — a pace of 14 billion for the year if growth stayed linear, though he cautioned it would not. Actions usage had moved from 500 million minutes per week in 2023 to 1 billion minutes per week in 2025, and then 2.1 billion minutes so far in the displayed week. GitHub now has more than 200 million developers, according to Daigle.
These numbers matter because Copilot is no longer only an autocomplete box. Daigle described a coding-agent harness spanning CLI, desktop, cloud agents, security remediation, documentation checks, issue handling, and internal workflows. More agents mean more pull requests, more builds, more Actions minutes, more CPU demand, and more pressure on permissioning systems that were built around human-paced collaboration.
The deeper platform problem is trust. A pull request used to carry social meaning: a known person proposed a change, another known person reviewed it, and project maintainers applied their judgment. Daigle asked what a pull request means when a large share of a project’s PRs may come from agents. If one agent writes code, another reviews it, and a human glances over the result, trust becomes diffuse. Stars are noisy and gameable. Package security remains hard. Dependency choices may shift as agents vendor snippets or inspect source directly, but verification does not disappear.
GitHub’s posture, as Daigle described it, is not to impose one workflow across every community. It is to expose enough context, compute, permissioning, sandboxing, and policy primitives that maintainers can encode their own trust rules. That could include account age, prior accepted PRs, social identity, dependency checks, security scans, or project-specific contribution policies. The hard part is that attackers adapt to simple thresholds, while open-source communities differ in what they are willing to accept.
Lovable shows the same systems argument at product scale. Benjamin Verbeek described two feedback loops for an AI coding product used by many nontechnical users. The first, “Lovable Stack Overflow,” identifies sessions where users got stuck and later recovered, extracts the missing context that would have helped earlier, clusters similar cases, reviews the proposed guidance, and tests it against production holdouts. Verbeek said early results showed messages with “fix” intent fell 4.56% and projects deployed at least once rose 1.65%, both with 99.9% confidence shown.
The second loop lets the agent complain. Lovable’s vent tool gives the main agent a channel to report missing tools, confusing docs, broken platform behavior, or repeated failures caused by the environment. Verbeek said that within the first hour of launching the vent tool, the agent filed roughly 20 complaints about a filename-copy failure involving spaces and special characters in user-uploaded files. The team fixed the issue, then discovered more edge cases through continued complaints. Vent spikes later became an incident signal when sandboxes or platform pieces broke.
- User gets stuckLovable detects repeated requests, complaints, or abandonment risk in a project session.
- User later recoversThe resolved session becomes evidence of what context would have helped earlier.
- Knowledge is testedA candidate guidance entry is clustered, reviewed, and evaluated against holdouts.
- Agent complainsWhen the blocker is Lovable’s own tooling or platform behavior, the vent loop routes a specific complaint to engineers.
- Fix is reviewedDuplicates are removed, issues are investigated, and some agent-generated PRs are reviewed and merged by developers.
GitHub and Lovable sit at different scales, but they point to the same conclusion. Agentic products need trust boundaries, permission systems, feedback loops, incident signals, context management, and mechanisms for deleting stale guidance. The product improves through harnesses and telemetry, not only by swapping in a stronger model.



