High-Quality Agentic Tasks Drove 5x More Fine-Tuning Uplift

Snorkel’s Kobie Crawford argues that task quality, not just model size or compute, can determine whether agentic fine-tuning produces useful gains. In a Terminal-Bench-style experiment holding the base model, compute budget and task count constant, Snorkel reported that fine-tuning on rejected low-quality tasks improved Qwen3-8B by about one percentage point, while accepted high-quality tasks improved it by 6.2 points. Crawford’s case is that well-specified, reliable tasks create learnable failures, while ambiguous prompts, mismatched tests and broken environments mostly add noise.
Task quality was the experimental variable, not model size or compute
Kobie Crawford framed the result as a test of a familiar data-quality thesis in a newer setting: agentic tasks. Snorkel’s position, he said, is that model capabilities are bounded by training data quality regardless of architecture, scale, or agent harness. In agentic coding work, the relevant unit of data is not only an input-output example but the task itself: the containerized environment, the task definition, the tests, the dependencies, and the conditions under which an agent is expected to act.
The experiment Crawford described held the usual confounders fixed. Snorkel trained the same base model, Qwen3-8B, with the same compute budget and the same number of tasks. The comparison was between two buckets: tasks Snorkel’s process accepted as high quality and tasks it rejected as lower quality.
The reported difference was large. Fine-tuning with reinforcement learning on low-quality tasks improved the average test pass rate from 15.6% to 16.6%. Fine-tuning on high-quality tasks improved it to 22.8%.
Crawford called the uplift “really striking.” The low-quality bucket produced about a one-point gain; the high-quality bucket produced a 6.2 percentage-point gain. On Snorkel’s slide, the conclusion was stated directly: “5x the improvement from data quality alone.”
| Training condition | Average test pass rate | Uplift from base |
|---|---|---|
| Base model (Qwen3-8B) | 15.6% | — |
| Fine-tuned on low-quality data | 16.6% | +1.1 pp |
| Fine-tuned on high-quality data | 22.8% | +6.2 pp |
The claim is not that architecture and harness choices are irrelevant. Crawford explicitly noted that those factors matter. The narrower claim is that underneath them, task quality remains central, and that the agentic setting does not escape the older rule that models improve only on the signal their data actually contains.
A good agentic task is not just one a model fails
Snorkel’s definition of task quality had four acceptance criteria. A task had to be achievable, meaning the success criteria were well-defined and unambiguous. It had to be non-trivial, because easy tasks do not improve models or agents. It had to be functionally correct, with valid code and logic. And it had to be reliable, with an environment that guarantees all dependencies are available.
Crawford described these tasks in the style of Terminal-Bench: a containerized environment, a task definition, and a setup intended to make runs reproducible, isolated, and parallelizable for rollouts. The container is not incidental. For agentic coding tasks, the environment is part of the data. If the environment is broken, missing dependencies, or inconsistent with the task, the resulting failure may say little about the model.
Snorkel’s research harnesses test for the four criteria. Tasks that pass become “accepted” and are used for training and research. Tasks that do not pass go into the “rejected” bucket. Crawford used those two buckets as a proxy comparison between high-quality and low-quality tasks.
The accepted tasks, in Snorkel’s analysis, looked harder in measurable ways. Evaluated with Claude Sonnet 4.5 and Codex, they averaged twice as many tool calls as rejected tasks. Their pass rate was lower: 41.4% versus 48.8%. They also required more output tokens, which Crawford interpreted as more model reasoning and more engagement with the task.
| Measured behavior | Accepted tasks | Rejected tasks | Interpretation Crawford gave |
|---|---|---|---|
| Tool calls | 2x more | Lower | Accepted tasks required more multi-step workflows and external-tool engagement. |
| Pass rate | 41.4% | 48.8% | Accepted tasks were harder to solve. |
| Output tokens | More | Fewer | Agents needed more reasoning to attempt accepted tasks. |
But Crawford treated those surface metrics as only the first check. A harder task is useful only if failure on it is meaningful. If failures are caused by ambiguity, hidden requirements, or broken execution environments, they do not produce the kind of learning signal a model can hill-climb on.
The important difference was in the failure modes
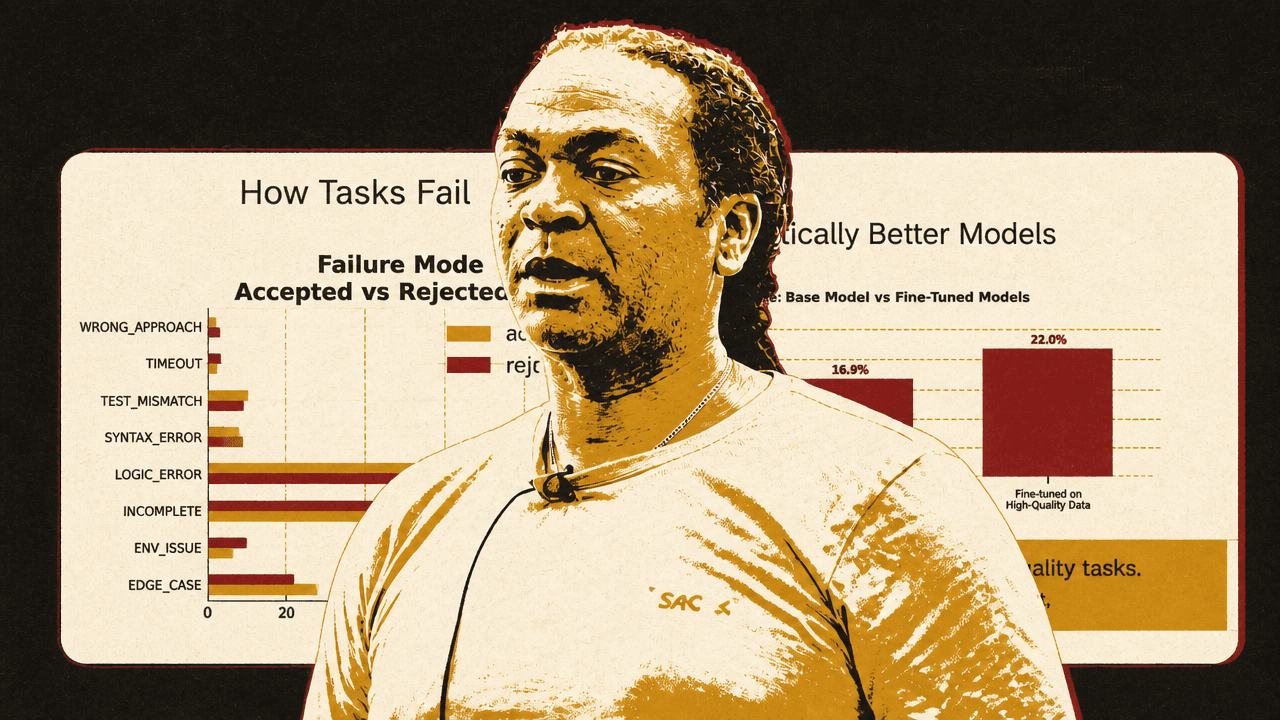
Snorkel categorized failures from task traces to distinguish useful model failures from noise. The categories included wrong approach, incomplete solution, syntax error, logic error, edge-case failure, test mismatch, timeout, environment issue, and other.
The distinction between those categories mattered because they do not all mean the same thing for training. A wrong approach means the model fundamentally misunderstood the problem. An incomplete solution means it produced only part of what was required. A syntax error means the code would not run. A logic error means the code runs but produces the wrong output. Edge-case failures work on basic cases but fail under less obvious inputs. Those are more directly about model behavior: they point to a gap in how the agent planned, implemented, generalized, or checked its work.
Test mismatch and environment issues are different. A test mismatch means the agent solved a different problem than the tests expected. An environment issue means Docker, dependencies, or the task environment prevented a clean attempt. Those failures can lower a pass rate, but they do not necessarily identify a capability the model should learn. They may identify a bad task.
The goal, then, was not merely to count failures. It was to decide whether the failures reflected something the model failed to learn or something wrong with the task. Crawford described a meaningful failure as one where the model does not reach the logical conclusion required by the task. A degenerate failure is one where no model could reasonably complete the task in that flow because the environment or specification is defective.
On Snorkel’s first failure-mode chart, accepted and rejected tasks showed different percentages across wrong approach, timeout, test mismatch, syntax error, logic error, incomplete solution, environment issue, and edge-case failure. Crawford highlighted logic errors and incomplete tasks as places where the pattern reversed between accepted and rejected tasks. A second chart, labeled “The Quality Signal,” showed over- and under-representation by category, measured as accepted-task failure share minus rejected-task failure share. The slide’s caption stated the intended interpretation: “Accepted tasks produce harder, cleaner failures. Rejected tasks produce noisy, unlearnable ones.”
Crawford’s explanation was that accepted tasks fail because the task is genuinely more difficult: the steps are harder, the logic is harder, and the agent has to do more real work. “The accepted tasks are producing cleaner failures,” he said. That makes the failure useful for training. Rejected tasks, by contrast, more often fail for reasons that do not say much about the model’s capability.
This is the core distinction in the talk. Ambiguity can make a task look hard. It can lower pass rates. It can cause agents to spend more time and fail more often. Crawford’s argument was that this is not the kind of hardness that improves models: the useful signal is a failure tied to a real capability gap, not a mismatch between the task, tests, and environment.
Underspecification creates apparent difficulty, not useful difficulty
The question period sharpened the distinction between hard tasks and underspecified tasks. One audience member asked whether the input itself might make tasks hard: a less prescriptive prompt could increase difficulty, while a very prescriptive one could make a task easier.
Crawford said yes, and pointed to underspecification as a common reason a task lands in the rejected bucket. In those cases, the desired testable outcome is not clearly specified in the task definition, but the backend tests still expect particular behavior. The model may solve a reasonable version of the requested task and still fail because the tests encode requirements that were never given.
He gave another failure pattern: implicit dependencies. A task’s tests may depend on something that the task definition never tells the model to account for. If that dependency is not in the model’s context, the model lacks the information needed to approach the problem.
An audience member pushed further, noting that real problem-solving is often iterative and not every task should be treated as a one-shot pass or fail. Crawford agreed with the premise. In benchmarking, however, Snorkel tries to construct tasks with backend verifiability. The intended bridge, he said, is that if the tasks are built correctly, the skills learned in verifiable settings can still be applicable in cases where outcomes are less cleanly verifiable or where further iteration is required.
That answer keeps the experiment inside an important constraint. Snorkel’s reported measurement came from a domain where verification is comparatively tractable: agentic coding tasks with tests. Crawford treated verifiability as the practical condition that made this analysis possible, while acknowledging that real-world problem-solving often extends beyond a single pass-fail interaction.
Bad tasks can mask whether models are improving
Another audience question asked whether Snorkel had tested a third condition: training on all tasks together, accepted and rejected, to see whether rejected tasks actively pull performance down or whether the model can learn around them as long as accepted tasks are present.
Crawford said this particular analysis did not give a direct answer to that mixed-training condition. He connected the question instead to Snorkel’s work looking at public benchmarks, including TerminalBench 1 versus TerminalBench 2 and variants of SWE-bench. Across that kind of benchmark analysis, he said, task quality can become a source of noise in evaluating model improvement.
The issue is saturation and impossibility. Some tasks never get completed not because the models have failed to improve, but because the tasks cannot be completed as written. If a benchmark contains enough such tasks, then model progress can be masked. The benchmark may appear to show a hard ceiling, while part of that ceiling is caused by tasks that are unsolvable or invalid rather than by remaining model weakness.
That distinction matters directly for evaluation. A benchmark is supposed to measure model capability. If a portion of its tasks fail for reasons unrelated to capability, then the benchmark’s signal is distorted. Crawford did not claim from this analysis to have measured whether rejected tasks pull down a mixed training run; he described them as a source of noise that can obscure whether improvement is actually happening.
Snorkel’s answer is expert curation plus scalable rubrics
Kobie Crawford tied the result back to Snorkel’s broader approach: datasets and RL environments should be built with human expertise in the loop. He said Snorkel has “a strong feeling” that expert involvement is an important part of delivering data quality, and that its platform is intended to scale that expert work without treating quality as optional.
The later Q&A made that more concrete, though Crawford kept it at the level of current direction rather than a fully specified methodology. In domains beyond coding and math, he said, verification becomes harder. Snorkel is working in areas where correctness may be fuzzy, where multiple outcomes may be acceptable, and where answers may need to be scored along a spectrum rather than marked simply pass or fail. He mentioned an open benchmark grants program through which Snorkel partners with people developing benchmarks and evaluations in less-verifiable areas, including human-centric evaluations involving emotional or qualitative judgment.
For those settings, Crawford described a rubric-based approach Snorkel uses. The platform brings together human annotators and LLM judges, with rubrics that list criteria and data points to be evaluated. He said those rubrics can be used by both people and LLM judges, and are meant to support high-level qualitative assessment as well as more quantitative comparisons. Human experts provide ground-truth information that can be used to inform LLM judges.
The agreement checks are part of Snorkel’s quality-assessment process as Crawford described it. Snorkel looks for high inter-annotator agreement among humans and also agreement between LLM judges and humans. In verifiable coding tasks, pass-fail tests make the assessment easier. In fuzzier domains, Crawford said Snorkel still uses the same guiding principle, but relies on richer rubrics and agreement measurement rather than only a deterministic test result.
The continuity across those domains, in Crawford’s account, is not that every task can be reduced to a clean binary grade. It is that task and evaluation quality have to be managed explicitly: the request, rubric, judge, environment, and failure signal all affect whether a dataset teaches the model something or merely produces noise.