AI Moves From Answers To Default Work Surfaces
John Coogan and Jordi Hays read Apple’s AI moment as a fight over the Siri button, private cloud path, and camera roll, while OpenAI’s Codex demo presents enterprise AI as a place where analysis is produced, inspected, revised, and delivered. Across retrieval, GPU deployment, coding revenue, compute scarcity, and employee ownership, the day’s applied-AI question is less which model wins a benchmark than who controls the working surface and who captures the gains.

The new AI battlefield is the default interface
Apple’s WWDC discussion, as read by John Coogan and Jordi Hays, turns Siri from a product-delay story into a control-surface story. The question is not only whether Apple can finally make Siri useful. It is whether the iPhone’s default assistant remains Apple’s interface when users increasingly build habits around ChatGPT, Claude, Gemini, or another model.
Coogan framed the moment through Siri’s long arc. Siri was introduced in 2011 with a promise that sounded much like today’s LLM assistant pitch: users should not have to learn rigid commands; they should ask naturally and have the phone infer intent. Coogan’s argument was that Apple did not suddenly discover AI. Siri came out of SRI International’s Artificial Intelligence Center, Apple acquired it, and then spent more than a decade shipping a voice assistant whose original ambition exceeded what the technology could deliver. Hays described the Tim Cook era as one in which Apple created immense value through operations, hardware, and the App Store, but did so through what he called an “AI winter.”
That history matters because the present fight is about the button, not just the model. Coogan said the expectation among heavy AI users is simple: if they trust ChatGPT, Claude, or Gemini for memory, work, and everyday tasks, they want the Siri button to invoke that model by default. The current pattern he described — ask Siri to ask ChatGPT, click through a permission prompt, and pass the request along — preserves Apple’s mediation. Hays called it “playing telephone.”
A model picker does not settle the issue. Hays said Mark Gurman responded to John Gruber’s skepticism with screenshots that appeared to match earlier reporting about Siri integrations, including what looked like a model picker. But Coogan and Hays treated the important question as persistence and friction. If the selection resets, requires repeated confirmation, or remains downstream of Siri permissions, Apple still controls the practical default. If the user can truly remap the assistant experience, Apple would be allowing more of the iPhone’s most valuable interface real estate to point outside Apple’s own assistant layer.
The privacy layer complicates that control question. Coogan said he had heard that Apple’s Private Cloud Compute had been extended into Google Cloud, involving Nvidia GPUs and infrastructure associated with Google while maintaining Apple’s privacy guarantees. He also referred to Apple Foundation Models and an “AFM3 Cloud Pro” reasoning model, while hedging the precise relationship to Gemini. In Coogan’s account, Apple is trying to preserve its privacy promise while extending inference into infrastructure associated with Google and Nvidia. That is a harder story than the old Apple privacy posture, because users store deeply personal material on their phones and Apple’s AI ambitions may require cloud partners that do not carry the same consumer meaning as Apple’s own hardware and software stack.
The camera discussion makes the same point from another angle. Apple’s Spatial Reframing in Photos, as described in the WWDC segment, lets a user adjust the perspective of a photo so it appears more straight-on, with the app showing that the photo has been reframed and allowing a tap back to the original. Coogan saw it as a practical Apple-style feature rather than generic image-generation “slop.” Hays focused on where Apple placed it: once the camera roll itself becomes an AI editing surface, the camera is no longer only a capture device. “The computer is now the camera,” in his framing.
That moves provenance from a niche generative-media concern into consumer-platform design. Coogan drew a tentative line between color grading, which enhances a captured image, and spatial reframing, which can produce a picture that “never existed.” But he also conceded the boundary is blurry. Computational photography already includes artificial depth of field, low-light cleanup, tone mapping, upscaling, filters, background removal, and now more aggressive reconstruction. Hays pressed the social implication: people’s memories may begin to diverge from what happened.
Spatial reframing is slightly... because it’s capturing a picture that never existed, whereas a filter is just sort of like enhancing colors. I don’t know. It’s clearly like a blurry line. But it’s the blurriest we’ve ever seen.
The labeling problem remains unresolved. Coogan wondered whether social platforms will split between accounts frequently tagged for AI use and accounts claiming “no AI ever.” Hays asked when the tag should apply. A small reframe? A filter? A neural-network black-and-white conversion? A generated scene? A producer noted that metadata might show some edits, but Hays pointed out that screenshotting could defeat that.
Apple’s consumer AI story therefore has three connected control surfaces: the assistant button, the private cloud path, and the camera roll. In each case the issue is less about a benchmark and more about defaults, trust, permissions, and provenance. Coogan and Hays read Apple as trying to make the original Siri promise technically real without turning the iPhone into a neutral launcher for someone else’s agent.


Enterprise AI is becoming workflow-native, not chat-native
OpenAI’s Codex analytics demo points in the same direction inside the enterprise. Codex is not shown merely as a SQL assistant or a chatbot answering an analyst’s question. It is presented as a workspace that takes a business problem through analysis, inspection, revision, and executive packaging.
The prompt in the demo is specific: “Using our Databricks data, create an interactive report diagnosing the recent spike in Wanderbricks booking cancellations and recommend what we should do next.” Codex then produces a report titled “Wanderbricks Cancellation Spike,” with an executive summary stating that July cancellations reached 28.8%, compared with 20.4% in June and roughly 19–21% from January through June.
The number matters less than the packaging. Codex is being positioned as an agentic data analyst — an AI system that can take actions across tools or steps rather than only answer one prompt — configured to an organization’s own data sources, skills, workflows, and templates. It gathers context, produces a business-facing report, generates charts, exposes the source query behind a chart, accepts edits, and exports the final artifact into Google Slides. The product claim is not “ask questions of your data.” It is “make Codex the place where analysis work happens.”
That distinction is important because enterprise adoption rarely turns on a single impressive answer. Analysts and business teams need artifacts they can inspect, edit, defend, and hand to leadership. In the demo, a user changes a “July daily cancellation rate” visualization to a bar chart because it is more business-user friendly. That edit happens inside Codex, not in a separate BI tool or slide editor. The report remains live as the user shapes it.
Codex also shows an audit surface. For one visualization, the user opens a data-source panel showing metadata and a visible SQL fragment beginning with SELECT CAST(created_at AS DATE) AS day, COUNT(*) AS bookings. The demonstration does not prove that every generated conclusion is reliable or that the system can handle messy enterprise data in production. But it shows how OpenAI wants to answer a key buyer objection: the work should not be a sealed chat transcript. A user should be able to inspect where a chart came from and decide whether the query belongs in the company’s systems.
The export step completes the workflow argument. Codex offers paths to publish a hosted link, create an HTML file, PDF, Google Doc, or Google Slides deck. The user selects Google Slides because leadership wants the report in the organization’s “exact templates.” The visible slide reads “WANDERBRICKS / EXECUTIVE READOUT” and “July cancellations spiked. Validate the window before changing operations.” The analysis has become a leadership artifact.
| Layer of work | What Codex is shown doing | Why it matters |
|---|---|---|
| Business question | Takes a cancellation-spike prompt tied to Databricks data | Starts from the user’s operational problem, not a generic chat |
| Analysis artifact | Builds an interactive report with findings and charts | Places analysis and explanation in one workspace |
| Inspection | Shows a source query behind a chart | Gives the user a way to check part of the analytical path |
| Revision | Allows chart edits inside the report | Keeps analyst judgment in the loop |
| Executive output | Exports to Google Slides in a familiar template | Moves from analysis to decision communication |
The comparison with Apple is useful. Apple is trying to keep the default assistant position on the phone. OpenAI is positioning Codex for a default workspace role in knowledge work. In both cases, the contested position is where the user begins, delegates, verifies, and finishes the task.
That also helps explain why the enterprise AI interface may not look like a general chatbot for long. A chat box can start a task, but the work surface needs data connections, templates, access controls, revision tools, exports, and some way to inspect the model’s path. Codex’s analytics demo is valuable because it shows the direction of the product bet even if it does not settle the reliability question.


The agent stack still depends on retrieval and developer infrastructure
The consumer and enterprise interfaces make AI feel increasingly autonomous. The technical middle layer tells a more prosaic story: agents still depend on retrieval architecture, indexes, grep, embeddings, GPUs, deployment loops, autoscaling, and cost controls. Applied AI is becoming agentic at the top, but underneath it is a fight to make context and compute cheaper, faster, and more reusable.
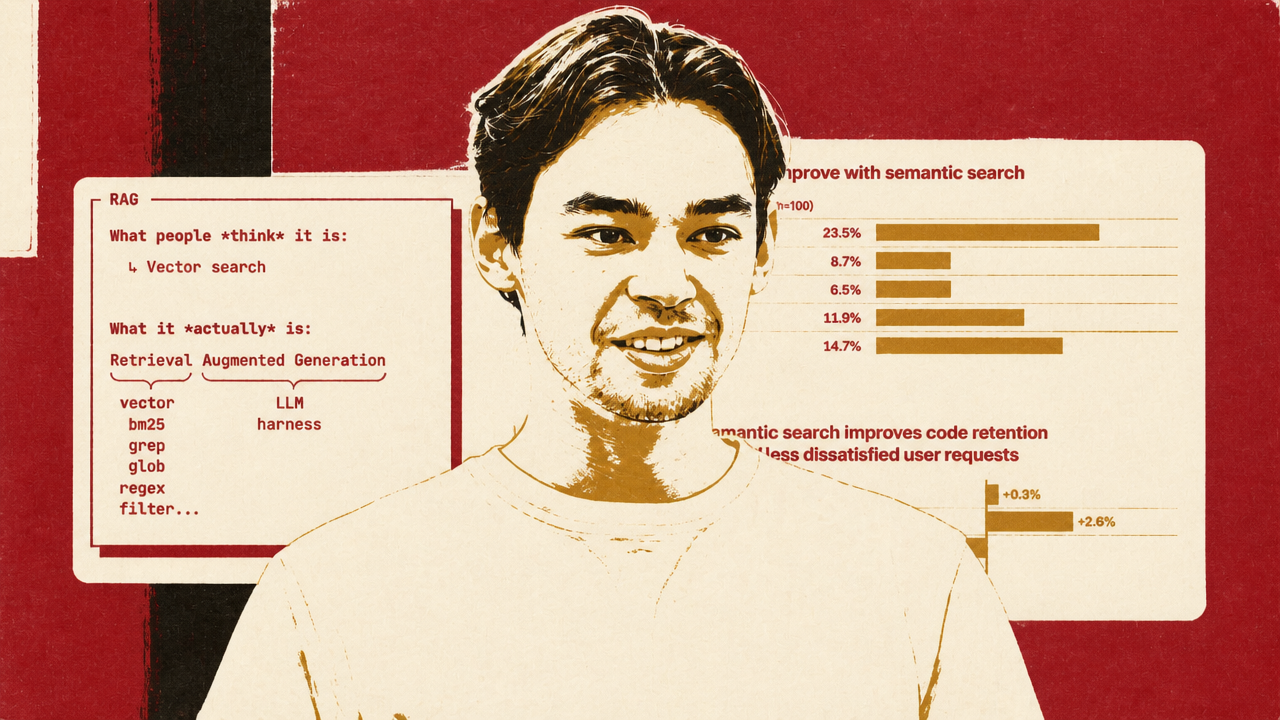
Kuba Rogut, a deployed engineer at Turbopuffer, pushed back on the claim that RAG is dead by arguing that the term has been defined too narrowly. The version often dismissed online is simple vector search: embed a corpus, retrieve a few chunks, put them in the prompt, and hope the answer improves. Rogut’s definition is broader. Retrieval includes vector search, full-text search such as BM25, grep, glob, regex, and filters. The augmented part is the model receiving external context.
That reframing turns “RAG versus agents” into a false opposition. Rogut’s preferred category is “agentic retrieval”: a model searches iteratively, reads what it finds, decides whether it needs more, tries another tool, and fetches the right context for the task. Long context windows do not remove the need to choose context. In Rogut’s telling, the practical task is narrowing huge corpora down to the right 100,000, 10,000, or million tokens, not dumping everything into the model.
The Cursor-versus-Claude Code contrast makes retrieval an economics question. Cursor indexes codebases by parsing, chunking, and embedding them so semantic search is available when a user opens a project or branch. Cursor reported that clones of the same codebase average 92% similarity across users within an organization, which lets it use Merkle trees to reuse indexes securely and process only changed files. Rogut cited Cursor’s reported semantic-search gains on Cursor Context Bench, including an average 13.5% answer-accuracy improvement across tested models and smaller online product-metric gains such as 2.6% higher code retention in large codebases and 2.2% fewer dissatisfied requests.
Claude Code, by contrast, was described through Boris Cherny’s explanation that early versions used “RAG + a local vector db,” but the team found agentic search simpler and better, with fewer issues around security, privacy, staleness, and reliability. Rogut does not treat that as proof retrieval is obsolete. He treats it as a tradeoff between per-session discovery and amortized understanding.
In Rogut’s example, a grep-based agent spends 6,314 tokens across several reads and searches to understand how metadata filtering works. An indexed system retrieves ranked chunks totaling 424 tokens. The indexed approach pays upfront to create reusable semantic representations. The grep-oriented approach pays discovery costs during each session. If many developers and agents ask similar questions over time, embeddings become cached compute.
RunPod’s Flash demo shows the parallel abstraction at the GPU layer. Audrey Hsu, presenting RunPod’s Python SDK, targets the commit-build-container-provision loop rather than model code itself. Her baseline loop is familiar to ML engineers: change inference code, commit it, push to GitHub, build a Docker image, pull it from a registry, load it onto a server, allocate a GPU, and test. Flash tries to replace that with a Python decorator on an async function.
The demonstrated code marks generate_image() with @flash.endpoint, requests a GPU family, and sets worker limits such as max_workers=5 and min_workers=1. Hsu’s summary was that a developer can take a regular async Python function, add the Flash endpoint decorator, and have RunPod package and deploy everything inside that function onto GPU cloud. The rest of the application stays in the local IDE, with hot reload pushing changes.
That does not make modeling trivial. Hsu’s first image-generation attempt, prompted by the audience for cats flying in the sky in cloudy London, initially produced a dragon because the prompt was not passed correctly. After correction, the model produced bad, distorted cats. Hsu then swapped from Stable Diffusion XL Turbo to DreamShaper, changed inference settings, and used the faster loop to try again. The value proposition was not “better cats.” It was that changing models and parameters did not require a full container and provisioning cycle.
The second RunPod demo made the infrastructure point more clearly. Hsu chained prompt expansion through Qwen, image generation through DreamShaper running on the Flash endpoint, and composition through Nano Banana 2. Flash was not the whole application; it was the GPU-backed function inside a larger local orchestration pipeline. That is how many applied AI products are being built: local application logic around multiple model calls, with remote inference inserted where needed.
| Technical layer | Rogut’s retrieval framing | RunPod’s deployment framing |
|---|---|---|
| Problem | Agents need the right context without repeatedly rediscovering it | Developers need GPU inference without rebuilding infrastructure for every change |
| Abstraction | Agentic retrieval across vector search, full text, grep, regex, glob, and filters | A Python decorator turns an async function into a GPU-backed endpoint |
| Economic question | Pay upfront for reusable indexes or pay per session in search tokens | Use Pods or low workers while experimenting; Serverless when autoscaling is needed |
| Practical caution | Long context does not eliminate retrieval choices | Fast deployment does not guarantee model quality |
Hsu’s product split reinforces the point. Pods are for persistent VM-like GPU environments; Serverless is for autoscaling inference with variable or spiky demand; Clusters are for training and multi-node workloads; Hub is for one-click deployment of open-source repositories and models. Flash sits inside that taxonomy as a developer interface into serverless GPU work. In the RunPod console, Hsu showed H100 80GB workers and a displayed cost of $0.00116 /s, while advising teams to experiment with low worker counts or Pods before moving to Serverless for larger scaling needs.
The technical middle layer is not glamorous, but it is where applied AI becomes usable. Agents need search tools and cached context. Developers need shorter loops between model experiments. Teams need to know when to pay for indexes, when to grep, when to keep a GPU reserved, and when to autoscale inference. The more AI becomes an operating layer, the more these choices determine cost, latency, reliability, and iteration speed.



Revenue proof is arriving first in code, and compute is the bottleneck underneath
Alex Sacerdote’s investment framework links the product-level shift to capital allocation and infrastructure demand. His claim is not simply that AI matters. It is that enterprise AI remains extremely early in deep workflow penetration, coding has become the first major proof that AI can generate large revenue by augmenting or replacing labor, and compute shortages are extending the boom from model providers into chips, memory, networking, fiber, power, cooling, and data-center supply chains.
Sacerdote estimated enterprise application AI penetration at less than 1%, while distinguishing casual AI usage from deep workflow usage. Hundreds of millions of people may use AI as a better search engine, but that is different from companies wiring AI into tools, building skills, and deploying bots that perform work. He cited Sundar Pichai’s estimate that only about 10 basis points of global knowledge workers are using AI in that deeper sense.
That low penetration figure is what makes the compute point striking in his framework. Sacerdote said that even before meaningful AI usage reaches 1% of knowledge work, “there’s not enough compute in the world.” He said Anthropic has only about half the compute it needs and cited Marc Andreessen’s view that there will not be enough compute over the next four years. For Sacerdote, tiny workflow penetration plus visible compute scarcity is evidence that the early adoption numbers understate the infrastructure problem.
Coding is the first proof point in that thesis. Sacerdote described the progression from early Microsoft Copilot-style assistance, which helped with blocks of code, bugs, and “grammar,” to more agentic coding tools such as Claude Code. The market, he said, “just exploded.” Whale Rock heard that unfettered users of Anthropic tools were spending about $100 a day on tokens; annualized, Sacerdote put that at $20,000 to $30,000 per user. With roughly 20 million coders globally, he framed coding alone as a possible half-trillion-dollar market.
That estimate is an investor’s scenario, not a settled market size. Its relevance to the applied-AI thread is that coding is where the workflow-native model is already producing spending behavior. Codex analytics, Cursor semantic search, Claude Code-style agents, and RunPod deployment loops all fit inside the same shift: AI is moving from a side assistant to a work substrate.
Sacerdote’s model-layer view is also more concentrated than the “models commoditize” argument. He described an emerging three-horse race among OpenAI, Anthropic, and Google, with OpenAI strong in consumer, Anthropic focused on enterprise and code, and Google still deeply relevant through Gemini and its broader technical base. He argued that open-source competitors can come close but struggle to leapfrog and sustain the frontier without comparable compute, and that model providers are building ecosystems around SDKs, orchestration layers, work products, and harnesses rather than exposing only raw APIs.
The software-incumbent contrast matters. Sacerdote said Whale Rock initially thought large software companies might benefit from AI because they had sales forces, customer relationships, proprietary data, and the ability to embed AI into existing products. He later became skeptical because their AI products did not move the needle or command meaningful pricing, in his view. CIO budgets may shift toward model tokens if the ROI is faster. Seat-based models may face pressure if companies freeze hiring or reduce headcount. AI-native competitors may attack old categories. At the same time, he left room for incumbent systems of record to matter if agents operate inside Slack, CRM, HR, and other enterprise data repositories.
That uncertainty is central to the “AI operating layer” question. If enterprise AI adoption accelerates, it does not automatically mean every existing software vendor benefits. AI may make some systems more valuable as data and workflow backplanes. It may also make the human-facing application layer less important if agents go directly to the data.
| Part of the stack | Sacerdote’s claim | Connection to applied AI |
|---|---|---|
| Coding tools | First clear revenue proof from augmenting or replacing labor | Shows workflow AI can drive substantial token spend |
| Model providers | OpenAI, Anthropic, and Google look more like an oligopoly than a commodity layer | Default workspaces and agents may cluster around a few model ecosystems |
| Software incumbents | May face budget pressure and interface disruption | AI operating layers can bypass or reframe seat-based applications |
| Compute infrastructure | Shortages extend demand into chips, memory, networking, power, cooling, and data centers | Every agentic workflow ultimately consumes inference and training capacity |
Underneath all of this is Sacerdote’s hardware renaissance thesis. He argued that the data center had been relatively commoditized for decades because workload growth and Moore’s Law improvements roughly offset each other. AI breaks that pattern because workloads are growing much faster and pushing physical systems to their limits. He called it the “de-commoditization of the hardware industry.”
High-bandwidth memory, liquid-cooled AI servers, Ethernet switches, printed circuit boards, fiber, and power supplies all become more strategic in Sacerdote’s account. He described AI servers as $200,000 to $300,000 systems that run hotter and are harder to swap once qualified. He said Ethernet upgrade cycles are compressing from roughly seven years to annual cycles. He said AI servers may require 40-layer printed circuit boards rather than 10-layer boards. He said fiber demand grows as clusters scale out, data centers scale across locations, and eventually GPUs inside racks may scale up over fiber rather than copper.
This is where the product and capital-market stories meet. If Apple wants richer assistant behavior, if OpenAI wants Codex to become an analytics workspace, if Cursor and Claude Code make developers spend more tokens, and if RunPod hides GPU deployment behind a decorator, then the usage has to run somewhere. Sacerdote’s argument is that investors are underestimating the earnings power of the winners and the amount of physical infrastructure required to support them.
He also named risks: negative regulation, model improvement slowing, open-source models catching up if frontier progress stalls, and wasted compute if major players abandon planned demand. Those risks are part of his framework. The useful industry read is narrower: the first obvious revenue pool is coding, the clearest bottleneck is compute, and the infrastructure beneficiaries may extend well beyond the model labs.


The unresolved question is who shares the productivity gains
The employee-ownership discussion widens the frame. If AI becomes an operating layer across phones, analytics, code, retrieval, and infrastructure, the next question is who participates in the value it creates. Maureen Conway of the Aspen Institute and William Castellano of Rutgers framed employee ownership as one possible answer, not as a settled solution.
Conway placed employee ownership inside a broader discussion of inequality, economic insecurity, and technological disruption. Her claim was that employee ownership is “an important arrow in our quiver,” not that it solves every problem. She described it as a fairness mechanism, a wealth-building mechanism, and a way to change how companies think about workers. Employee-owned firms, in her account, are more likely to treat workers as sources of knowledge, creativity, and value rather than as labor inputs alone.
Castellano made the AI link directly. After several years of research for a book on managing the future of work, he identified exponential advances in artificial intelligence and robotics, demographic pressure, and changing work organization as forces companies are trying to navigate. Broad-based equity programs, he argued, can increase engagement, commitment, and innovative behavior — precisely the behaviors organizations may need as technology changes objectives and workflows.
His strongest line was about distribution: rather than being replaced by robots or AI, workers should “own the robots and AI.” Castellano’s preferred mechanism was broad-based equity participation, supported by incentives, financial support, tax policy, AI guardrails, and upskilling or reskilling efforts. Conway similarly emphasized that technological progress does not automatically produce shared prosperity. Without intentional choices, innovation can concentrate wealth and widen inequality.
That question sits behind the rest of the applied-AI stack. Apple and OpenAI are battling over interface and workflow control. Developers and infrastructure providers are abstracting retrieval and GPU deployment. Investors are underwriting model revenue and compute scarcity. Workers and policymakers are asking whether productivity gains become wages, ownership, profit sharing, displacement, or some mix.
Employee ownership is only one proposed mechanism. Conway noted that the category includes ESOPs, worker cooperatives, employee ownership trusts, and structured equity or profit-sharing models. Those differ in design, but share the premise that when the business does well, the workers who help run it should do well too. Castellano added that government can shape the incentive structure through regulation, tax support, and workforce investment.
The employee-ownership argument also complicates the usual automation debate. The narrow question is whether AI replaces particular tasks or jobs. Conway and Castellano’s broader question is whether workers have any claim on the productivity gains from the systems they help deploy, maintain, supervise, and improve. If AI raises output per worker, ownership and profit-sharing arrangements become one way to connect productivity to household wealth rather than leaving the gains only with shareholders, founders, vendors, or infrastructure suppliers.

