RAG Is Becoming Agentic Retrieval, Not Disappearing

Kuba Rogut, a deployed engineer at Turbopuffer, argues that claims about RAG’s death rely on defining it as a narrow, one-shot vector search pattern. In his account, retrieval-augmented generation is becoming a broader agentic retrieval system: vector search, full-text search, grep, regex, glob and filters used iteratively by models that keep looking until they have the right context. He points to Cursor’s semantic-search gains and contrasts its upfront indexing with Claude Code’s per-session grep approach to frame embeddings as cached compute whose value depends on reuse.
The “RAG is dead” argument depends on defining RAG too narrowly
Kuba Rogut argues that the fight over whether RAG is dead is mostly a fight over a bad definition. Rogut is a deployed engineer at Turbopuffer, which he describes as a full-text search and vector-search database built from first principles on object storage. That matters because his argument is not that one retrieval product category should survive, but that retrieval itself has been defined too narrowly.
The version being dismissed on social media is “simple vector search”: embed a corpus, send an embedding vector, retrieve a few chunks, pass them to an LLM, and hope the answer improves. That is not what retrieval-augmented generation should mean in practice.
The practical implication for AI-product teams is that retrieval architecture is becoming a cost, latency, and reuse decision, not a theological choice between “RAG” and “agents.”
At Turbopuffer, retrieval includes vector search, full-text search such as BM25, grep, glob, regex, and ordinary filters. The “augmented generation” part is simply the model receiving retrieved external context. On that definition, RAG is not a single vector-database call. It is a broader retrieval system that can expose multiple search tools to a model.
The same narrowing happens with “agentic search.” The term is often used to mean filesystem grep, especially in discussions of tools such as Claude Code and Codex. Rogut’s preferred definition is broader: agentic search means giving agents a set of tools they can use progressively and iteratively to find and reason over external context. An agent can read a file, decide it has not found enough, search again, inspect more evidence, and continue until it has what it needs to complete the task.
That broader definition makes the alleged opposition between RAG and agentic search less clean. “RAG” is not necessarily one-shot vector search, and “agentic search” is not necessarily just grep. Rogut’s category for the emerging pattern is “agentic retrieval”: agents reason in steps, search as needed, and fetch only what is useful for the task at hand.
The usage curve and the discourse are moving in opposite directions
Rogut frames the social-media claim plainly: many posts in late 2023 and early 2024 declared that RAG was dead, that long context windows would make retrieval unnecessary, or that agents only needed filesystems. The examples he presented included lines such as “RAG is dead,” “Just give it 10M token context,” “AI Agents only need filesystems,” and “Agents Don’t Need Databases.”
The Google Trends chart he showed for “Retrieval-augmented generation” in the United States, covering March 2023 to February 2026, moved in the opposite direction. Interest rose in 2023, flattened through much of 2024, then hit a new inflection point around mid-2025 and spiked sharply into 2026.
The contrast is the point: while part of the AI conversation was treating RAG as obsolete, search interest in the term was increasing dramatically.
Cursor’s semantic search is evidence that retrieval still improves agents
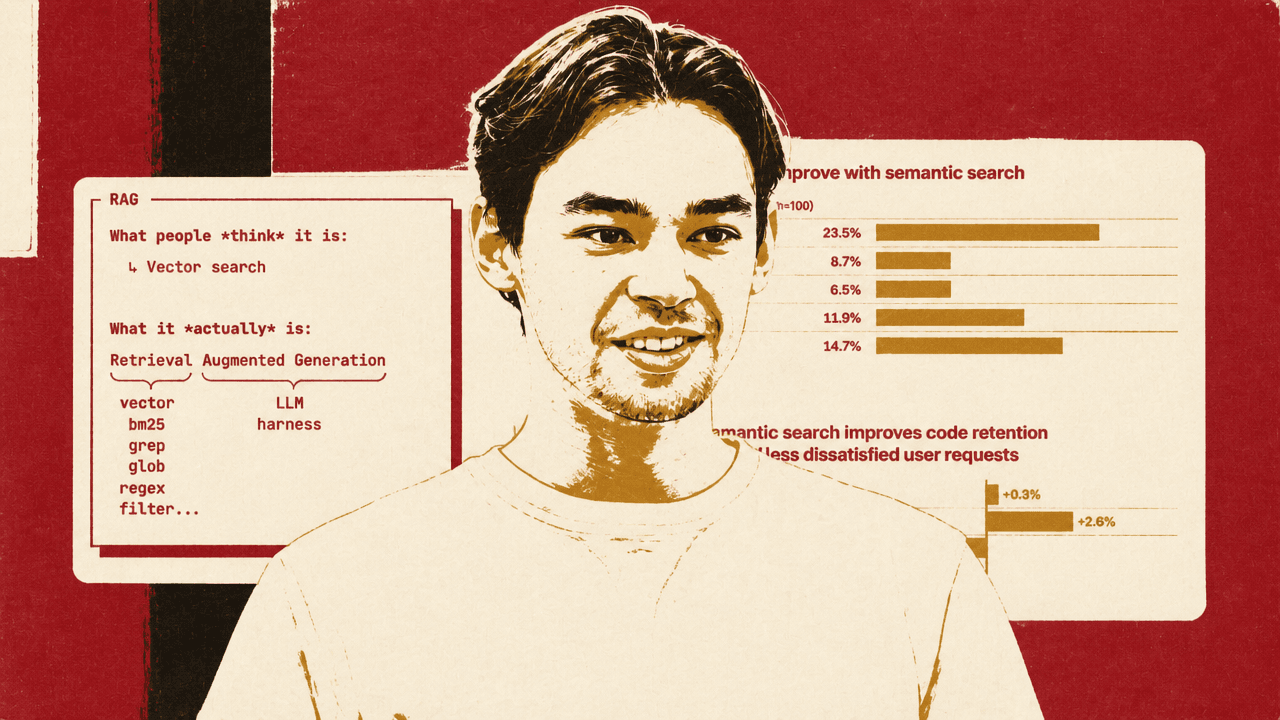
The central example is Cursor, which Rogut describes as one of Turbopuffer’s first customers and, in his view, an example of strong agentic search. Cursor indexes codebases by parsing, chunking, and embedding them so they become available for semantic search when a user opens a project or branch.
The large-codebase problem is that naively re-chunking, re-embedding, and re-uploading a repository every time a developer opens it can be expensive and slow. Cursor’s stated observation is that most teams work from near-identical copies of the same codebase; Cursor reported that clones of the same codebase average 92% similarity across users within an organization. It uses Merkle trees to calculate similarity between codebases, securely reuse an existing teammate’s index when appropriate, and reprocess only changed files.
The purpose of that infrastructure is not architectural elegance. In the Cursor semantic-search post Rogut showed, Cursor reported that semantic search improved answer accuracy by an average of 13.5% across tested models on Cursor Context Bench, with an 8.5% to 23.5% range across models.
| Model or metric | Reported effect |
|---|---|
| Composer | 23.5% relative improvement on Cursor Context Bench |
| Gemini 2.5 Pro | 8.7% relative improvement |
| GPT-4 | 6.5% relative improvement |
| Grok Code | 11.9% relative improvement |
| Sonnet 4.5 | 14.7% relative improvement |
| Code retention in large codebases | +2.6% |
| Dissatisfied user requests | -2.2% |
The online A/B-test gains can look small: 2.6% higher code retention in large codebases and 2.2% fewer dissatisfied user requests. But those are aggregate product metrics, and semantic search does not affect every request in the denominator. If the tool is available to 100 random queries, not all 100 queries will use or benefit from semantic search, so the measured average is diluted across requests where the tool may not matter.
Claude Code is a tradeoff, not a refutation
Kuba Rogut contrasts Cursor’s indexing approach with Claude Code’s grep-oriented approach. In a post he cited, Ethan Lipnik asked why Codex and Claude do not use cloud-based embeddings like Cursor to search a codebase quickly. Boris Cherny replied that early versions of Claude Code used “RAG + a local vector db,” but the team found agentic search worked better and was simpler, with fewer issues around security, privacy, staleness, and reliability.
That contrast introduces the idea that embeddings and semantic search are “cached compute.” The question is whether the cost of computing semantic representations upfront is worth amortizing across future queries.
The comparison is between “per-session discovery” and “amortized understanding.” In a Claude Code-like trace, an agent asked to understand how metadata filtering works might grep for “metadata filter,” read the wrong section of indexing.py, grep for “ingest pipeline,” read part of api_client.ts, then read types.ts for context. Rogut attached token counts to those steps: 820, 2,104, 640, 1,450, and 1,200 tokens, totaling 6,314 tokens for that sub-step.
In a Cursor-like trace, the codebase is chunked, embedded, and indexed ahead of time. At runtime, the agent asks “how is metadata filtered?” and receives ranked chunks from indexing.py, api_client.ts, and types.ts, totaling 424 tokens. The tradeoff is an upfront indexing cost in exchange for cheaper, faster retrieval later.
The economics depend on repetition. If 10 agents, across 10 developers, ask similar questions across multiple days, a grep-based agent pays the discovery cost repeatedly. An indexed system pays once, then reuses the semantic representation. In this framing, embeddings are not magic; they are cached work.
Rogut adds an observation from Turbopuffer: some team members who had been heavy Claude Code users were switching to Cursor because of speed, especially with Cursor’s Composer 2 models and semantic understanding.
Long context does not remove the need to choose context
Kuba Rogut does not describe the end state as old-style RAG, where an application retrieves once, stuffs the prompt, and “crosses fingers.” Sophisticated customers, in his account, are moving toward agents that make many retrieval calls, reason over several steps, search semantically or through full text as needed, and fetch only what is useful for the current task.
That matters even in a world of very large context windows. Rogut cites a Jeff Dean line, presented via a post attributed to swyx, that bigger context windows alone are not enough. What matters, in that framing, is staged retrieval: lightweight mechanisms that narrow a billion tokens down to 10 million, then to the million actually needed. The line Rogut emphasized was: “you don’t need a trillion at once, you need the right million.”
This is how Turbopuffer thinks about customers with trillions of embedded tokens. The practical task is not to place everything into context. It is to narrow a huge corpus down to the right 100,000, 10,000, or million tokens that the model should actually see.
In that framing, RAG is not dead. A narrow implementation pattern is being displaced by tool-rich retrieval systems where search is iterative, mixed-mode, and agent-controlled.