AI Demand Hardens Into Contracts, Controls, And Backlash
AI demand is showing up in revenue estimates, compute agreements, Nvidia results, and data-center politics, while enterprise adoption remains constrained by workflows, governance, and trust. Gavin Baker framed the infrastructure boom as demand becoming tangible; Errol Gardner, Yash Patil, OpenAI, Sarah Chieng, and David Plouffe each pointed to the operating, control, and legitimacy tests that now determine how much of it can be absorbed.
AI demand is turning into hard commitments
Applied AI is entering a less forgiving phase. The strongest signal is not another model release, but the conversion of AI demand into contracts, revenue, chips, power, data centers, controls, and political conflict. The easy story was that better models would unlock adoption. The harder story is that adoption now depends on whether companies, communities, developers, and regulators can absorb the systems being built around those models.
Gavin Baker’s appearance on the All-In panel captured the “real economy” side of the argument. Baker treated Anthropic’s reported move into operating profitability as more important than the personnel news that prompted the discussion. The Wall Street Journal headline shown in the segment said Anthropic expected a 130% revenue surge to $10.9 billion in the June quarter and its first operating profit. Baker’s broader claim was that OpenAI and Anthropic together were already around $100 billion of annual recurring revenue under a strict definition of LLM token revenue, with inference gross margins around “80 percent-ish.” He argued that it was not hard to imagine $200 billion, $300 billion, or $400 billion of ARR by year-end across OpenAI, Anthropic, Gemini, Cursor, xAI, and open source.
That framing matters because it shifts AI infrastructure from speculative capital expenditure to contracted demand. The clearest emblem was the SpaceX-Anthropic compute agreement shown in the discussion. The disclosed agreement said Anthropic would pay SpaceX $1.25 billion per month through May 2029 for compute capacity across COLOSSUS and COLOSSUS II, subject to a 90-day termination right. Jason Calacanis called it “Elon Web Services.” Baker interpreted it as evidence that SpaceX’s AI business had already “effectively quadrupled,” because a company that can build and power data centers quickly can convert demand into revenue.
The same discussion treated Nvidia’s latest results as infrastructure confirmation rather than only a stock-market event. Calacanis presented Nvidia’s quarter as $81.6 billion in revenue, up 85% year over year and 20% quarter over quarter, with $48.6 billion in free cash flow, roughly 75% gross margins, and an $80 billion new buyback authorization. Baker pushed back on bear cases around Nvidia share loss to hyperscaler ASICs and around short GPU useful lives. His view was that Nvidia’s position had broadened, including a CPU business expected to generate $20 billion this year, and that older GPUs could remain useful longer in disaggregated inference systems.
The infrastructure story is not cleanly bullish. The same panel tied AI acceleration to pressure points that make the boom more consequential: electricity demand, memory bottlenecks, data-center buildout speed, inflation, higher yields, U.S.-China policy, labor displacement, and local backlash. Baker said GPUs would flow to whoever could “start converting electrons into tokens.” That phrase clarifies both the opportunity and the constraint: AI demand is now a power, land, supply-chain, and permitting story.
| Signal | What it shows | Where the stress appears |
|---|---|---|
| Anthropic profitability and LLM ARR estimates | Model demand is showing up as revenue, not only usage | Investors must distinguish durable margins from cyclical enthusiasm |
| SpaceX-Anthropic compute contract | AI demand can become multi-year infrastructure commitments | Data centers need power, chips, land, and local acceptance |
| Nvidia revenue and free cash flow | The compute supply chain is monetizing the boom now | Markets are debating chip share, GPU useful life, and overextension |
| Data-center buildout claims | Speed of construction may become a competitive advantage | Communities and grids must absorb the physical footprint |
The point is not that the AI boom has been proven safe or permanent. It is that the boom has become tangible enough to create second-order problems. When demand was mostly discussed as future productivity, the debate could stay abstract. Once demand appears as revenue, buybacks, off-take agreements, power consumption, and public-market structures, it becomes harder to separate the technology cycle from the macro and political cycle around it. That same conversion from abstraction to reality reappears inside enterprises: capital can move quickly, but operating models usually cannot.


Enterprise agentic AI is still earlier than the market narrative suggests
The infrastructure numbers can make it sound as if enterprise operations are already being remade. Errol Gardner, EY’s global consulting chief, supplied the counterweight: he rates enterprise agentic AI adoption at “less than 1” on a 0-to-10 scale.
That is not a claim that companies are ignoring AI. Gardner separates three categories that are often collapsed. Traditional machine learning is already embedded across many organizations. Generative AI tools are widely used for research, analysis, drafting, knowledge access, and productivity. Agentic AI is the narrower and harder case: agents replacing activities, activities joining into workflows, workflows becoming business processes, and processes changing larger value chains.
Gardner’s distinction is useful because it prevents a common category error. A pilot is not a transformed process. A useful internal assistant is not a governed enterprise workflow. A single agent is not an operating model. A company can have real AI usage and still be far from agentic transformation.
The cloud comparison makes the point sharper. Craig Smith suggested cloud might be around 7 out of 10 in enterprise adoption. Gardner accepted the broad comparison but noted that cloud has been around for roughly 15 years and still is not universally or uniformly adopted. Some organizations embrace cloud broadly; others keep certain workloads, data, or systems outside it. Gardner’s implication was not that agentic AI must take 15 years. It was that claims of transformation in 15 days or 15 months ignore how large organizations actually change.
Gardner’s central bottleneck is not model access. It is the organization around the model. Leaders must sponsor the change. Middle managers must understand and reward new behavior. Workers must trust the system enough to use it. Data controls must prevent sensitive information from leaking into public tools. Regulators and customers must accept the process. Workflows must be redesigned rather than simply decorated with AI.
That turns enterprise AI from a procurement question into an operating-model question. The binding constraint is shifting from whether a company can access a capable model to whether it can integrate agents into accountable work.
EY’s own internal deployment illustrates the middle state. Gardner said EY has roughly 400,000 employees globally, built a private LLM, moved internal knowledge into it, and gave employees controlled access. The use cases he named were practical: research, proposals, contracting, information consolidation, access to knowledge, tax work, audit delivery, and software development. EY also has an increasing number of agents, but Gardner did not present the firm as fully transformed. He described the work as an ongoing test of how a large organization gives people tools, training, guardrails, and reasons to change how they work.
That has implications for vendors and buyers. Enterprise buyers are hard to reach, regulated industries move slowly, data sovereignty concerns vary by country, and workforce displacement fears can create resistance before the technology is even deployed. Gardner expects governments to become involved if AI displacement becomes large enough, whether through regulation, tax policy, peer pressure, or other mechanisms.
The practical lesson is that enterprise AI adoption should be measured by workflow penetration, not demo quality. A model can be impressive, a pilot can work, and an internal tool can save time while the company remains far from redesigning a value chain around agents.


The enterprise moat is knowing what correct means
If Gardner explains why scaled adoption is hard, Yash Patil explains where enterprise advantage can come from once companies begin doing the hard work. Patil, chief executive of Applied Compute, argued in a Stanford seminar that frontier models increasingly set the floor, while durable advantage comes from internal evals, proprietary context, verifiers, feedback loops, task environments, and company-specific definitions of correctness.
His most compact line was that “whatever hill you want to climb, you first define it with an Eval.” In that framing, evals are not just scoreboards. They decide what the system optimizes. Reinforcement learning then becomes, in Patil’s phrase, an “Eval-maxing machine.”
That changes the enterprise question. The scarce asset is not “data” in the generic sense. It is the ability to define the task, expose the right context, verify the result, and feed improvement back into the system. A general model may be a “smart genius” that knows nothing about a particular business. The business advantage comes from teaching the system what good looks like inside that business.
DoorDash merchant onboarding was Patil’s most concrete example. DoorDash onboards more than 100,000 merchants a year, he said. Merchants provide unstructured information, including menus. The problem is not simply optical character recognition. DoorDash has internal rules for how menu items, modifiers, add-ons, options, and special ingredients should be represented. A model must translate messy inputs into DoorDash’s own operating schema.
Patil said Applied Compute used a vision-language model, human corrections, and training against ground truth to reduce critical menu errors by 30% relative. The lesson is that “use a better model” is not always the answer. The model had to learn DoorDash’s definition of correctness.
The same logic applies in code, finance, compliance, slides, search, and support workflows. Code became an early frontier for agentic systems because it provides unusually clear verification: code can compile, tests can pass, and outputs can be checked. But many enterprise tasks do not have deterministic tests ready-made. Companies need to build them, or approximate them with verifiers, human feedback, and product-specific reward signals.
| Enterprise asset | Why it matters |
|---|---|
| Internal evals | Define what the system should optimize for inside the business |
| Proprietary context | Gives the model information not available in general training data |
| Verifiers | Provide a signal that an output is correct, useful, compliant, or safe |
| Feedback loops | Turn production behavior into improvement over time |
| Product constraints | Force tradeoffs among quality, latency, cost, and user experience |
Patil’s Cognition/Devin example added a product constraint. Applied Compute put a bug-checking model into production that runs shortly after a developer saves a file and targets sub-two-second latency. A large general model might be more capable in the abstract, but too slow or expensive for that loop. A smaller specialized model can win when the product needs low latency, low cost, and good-enough performance on a narrow task.
That is the enterprise AI moat in operational form: general models provide broad competence, but organizations capture value by encoding their own standards into the system. Gardner’s warning is that agentic transformation remains early because organizations are hard to change. Patil’s answer is that the path forward runs through evals, verifiers, and proprietary context rather than waiting passively for the next frontier model.


Agent products are becoming governed operators
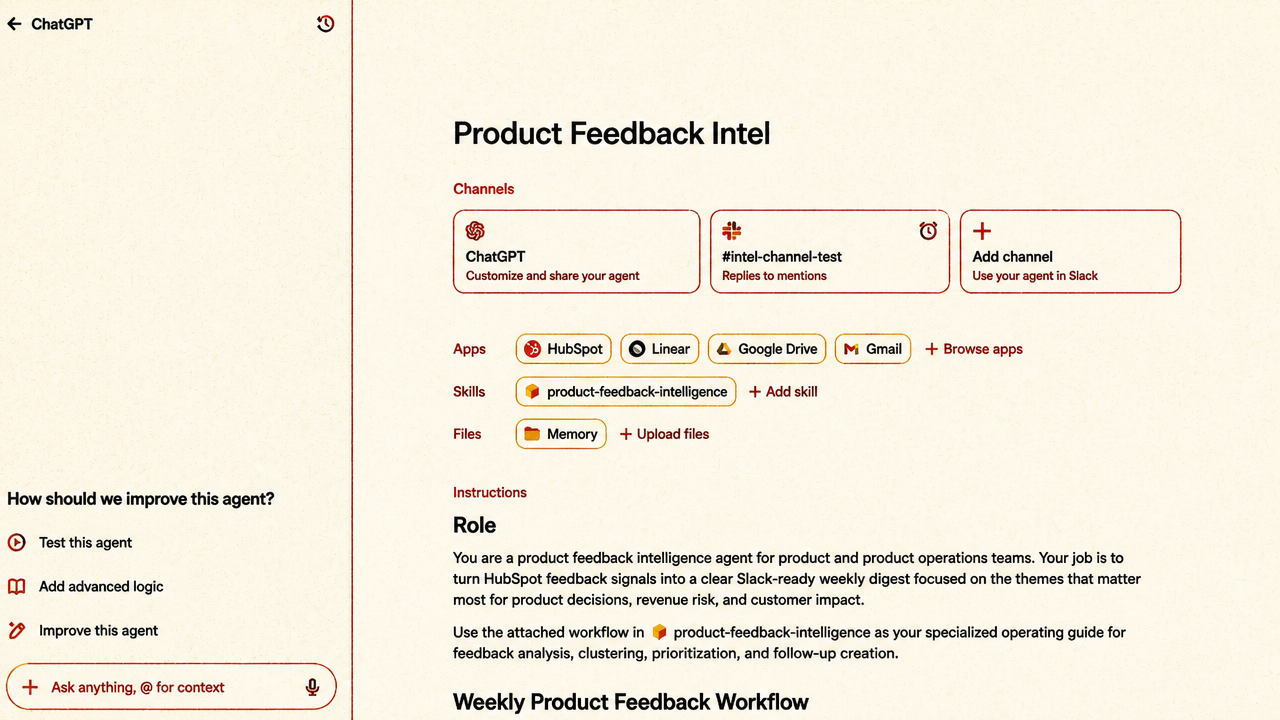
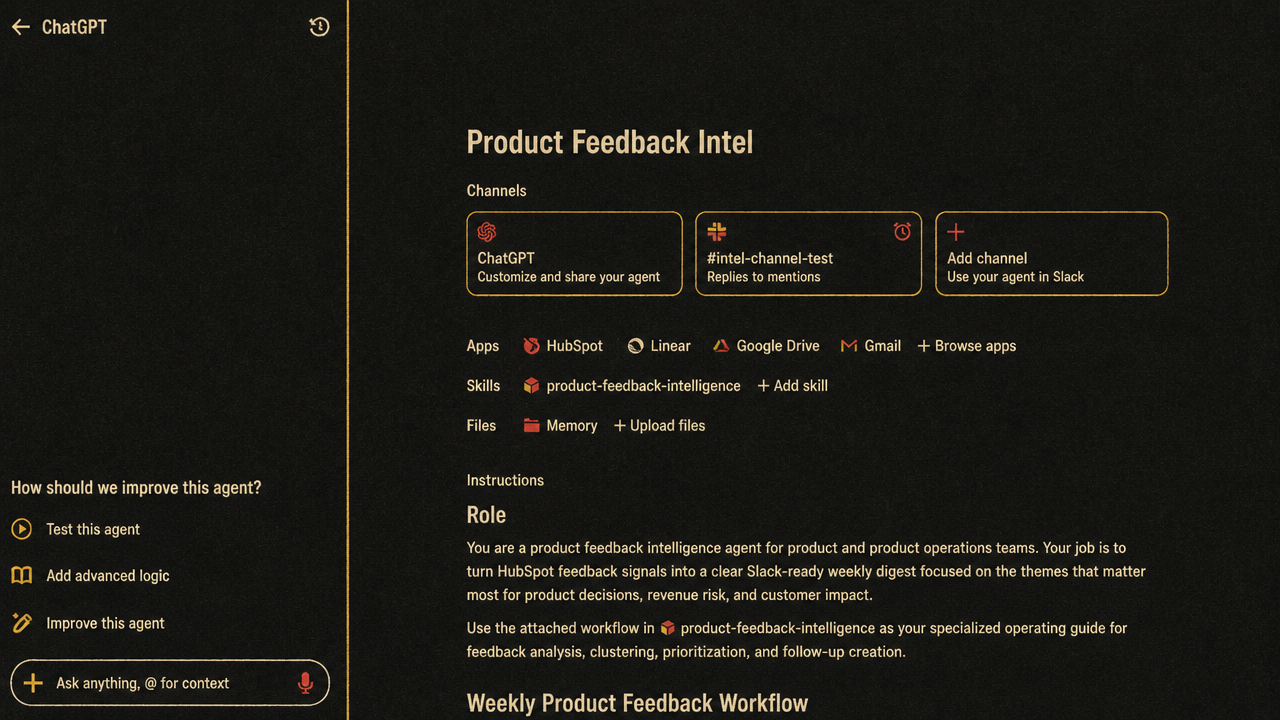
OpenAI’s workspace-agent controls show what happens when agents move from individual chat sessions into shared enterprise infrastructure. The product pattern is no longer just “ask a model a question.” OpenAI is presenting workspace agents in ChatGPT as shared, scheduled operators for repeatable team workflows, generally available to Business, Enterprise, and Edu customers.
The Product Feedback Intel demo is the useful case. The agent is connected to Slack, HubSpot, Linear, Google Drive, and Gmail. It gathers customer context and product feedback, creates artifacts such as PRD briefs and slides, generates tickets in Linear, and posts weekly product-feedback updates into a Slack channel on Mondays at 9:00 AM Pacific. It can respond in a thread, incorporate team feedback, and remember that feedback for future runs.
Once an agent reads across systems, posts into team channels, creates work items, and runs on a schedule, it begins to resemble a delegated operator. That requires a control stack closer to enterprise software governance than consumer AI user experience.
OpenAI’s model separates builder controls from admin controls. Builders configure the specific agent: which tools it can access, which actions it may take, and what constraints govern those actions. In the Gmail example, the builder can restrict sending emails to a particular domain, such as openai.com, because the agent handles sensitive customer and product information. The interface also lets builders toggle read and write actions and create natural-language constraints that are translated into schemas.
Admins sit above that. In ChatGPT Enterprise, workspace admins can decide who can build agents, who can publish them, which apps agents can access, which roles can use which apps, which actions are available, and when human confirmation is required. The admin layer matters because a builder’s choices should not be the only line of defense when agents can touch company systems.
Human confirmation is a separate control. OpenAI’s displayed configuration says ChatGPT can prompt for confirmation for actions it deems consequential, while read actions may be allowed without confirmation. That distinction reflects a more mature governance model: not every action carries the same risk, and uninterrupted automation must be balanced against explicit approval for consequential steps.
| Layer | Control question | Example from the Product Feedback Intel workflow |
|---|---|---|
| Builder | What can this agent access and do? | Connect Slack, HubSpot, Linear, Google Drive, and Gmail; restrict email sending by domain |
| Admin | What may agents in this workspace use? | Set role-based access, app permissions, available actions, and publishing rights |
| Human confirmation | Which actions need explicit approval? | Allow low-risk reads while requiring confirmation for consequential actions |
| Memory | What should carry into future runs? | Incorporate Slack feedback into later weekly product-feedback updates |
The OpenAI product example connects directly to Gardner and Patil. Gardner’s enterprise adoption hurdle requires governance, management, and trust. Patil’s enterprise moat requires context, workflow, and definitions of correctness. Workspace agents operationalize both questions. The agent needs access to enough context to be useful, but not so much freedom that it becomes ungovernable. It needs memory to improve across runs, but memory also becomes part of the governance surface. It needs permission to act, but action must be bounded by role, app, action type, and confirmation requirement.
That same pattern appears in developer tools. Once an AI system can act faster and touch more surface area, control is not a secondary feature; it becomes the condition for useful deployment.
Faster coding agents require tighter process
The developer-workflow version of the same pattern came from Sarah Chieng of Cerebras. Her argument was not that faster coding models automatically make developers more productive. It was that faster models make loose process more dangerous.
Chieng framed Codex Spark, built by Cerebras with OpenAI, as a coding model that can generate roughly 1,200 tokens per second, compared with about 40 to 60 tokens per second for Sonnet and Opus families. The warning was simple: the old habit of large prompts, unattended agents, delayed validation, and sprawling context can now produce technical debt at machine speed.
Her playbook is the developer-side counterpart to enterprise agent governance. Use faster models for smaller bounded tasks, not larger unattended ones. Keep concurrency low enough that a human can understand the code. Run tests, linting, type checks, diff reviews, and browser QA continuously. Treat model choice as a three-variable decision among intelligence, cost, and speed. Use larger, slower models for planning and faster models for execution. Externalize memory into files such as PLAN.md, PROGRESS.md, and VERIFY.md so sessions can restart without losing the plan.
The most important shift is that validation becomes cheap enough to move from the end of the process into every step. At slow speeds, developers are tempted to bundle work because each turn costs time. At high speeds, they can make each task smaller, inspect the result, steer immediately, and verify continuously. Chieng’s argument is counterintuitive but consistent: faster models require more deliberate developers.
Her concern about agent swarms is also relevant beyond software engineering. She described social-media examples of many coding agents running at once: six terminals, 11 Codespaces, hundreds of agents, multiple MVPs. Her objection was not to parallelism itself, but to parallelism nobody can explain or verify. That is the same institutional problem enterprises face with shared agents: automation that cannot be inspected is not just speed; it is unmanaged risk.
Chieng’s guardrails were concrete: ban destructive commands such as rm -rf, limit file creation, cap diff size, require tests and types to pass before commit, show diffs before continuing, and avoid letting context windows drift into compaction without external memory. Her context framework treated 0–30% usage as sharp, 30–60% as still good, 60–80% as likely to degrade, and 80–100% as a signal to start over.
| Risk from faster coding agents | Process response Chieng recommends |
|---|---|
| Large prompts produce large unreviewed changes | Break work into smaller tasks and cap diff size |
| Unattended agents create code nobody understands | Limit concurrency and keep the developer beside the work |
| Delayed validation hides failures | Run tests, linting, type checks, and reviews continuously |
| Context compaction loses constraints | Use external memory files such as PLAN.md, PROGRESS.md, and VERIFY.md |
| Model speed is mistaken for model suitability | Choose among intelligence, cost, and speed by task phase |
For applied AI teams, the broader lesson is that speed changes process design. A faster model can make pair programming feel real-time, generate multiple implementation variants for a developer to choose from, and keep validation loops short. But the productivity gain depends on the human and organizational system around it. Without smaller tasks, stricter permissions, and continuous verification, faster inference mostly accelerates the production of work no one has reviewed.


Backlash is now part of the deployment environment
David Plouffe’s argument closes the loop from infrastructure and enterprise deployment to public legitimacy. Plouffe, Barack Obama’s former campaign manager and a partner at Orchestra, argued that AI could plausibly become the dominant issue in the 2028 presidential race because Americans may experience it less as a tool than as another elite-driven transformation being imposed on them.
His point was not that AI will decide the 2026 election. He said 2026 would be driven more by spending and other forces. But by November 2028, he thinks AI could be central. The reason is that AI touches multiple political anxieties at once: jobs, inequality, children’s futures, mental health, energy prices, local data centers, national security, distrust of technology leaders, and the legacy of social media.
Plouffe’s account connects directly to the earlier sections. Infrastructure buildout becomes local data-center politics. Enterprise adoption becomes worker anxiety. Productivity claims become fear of elite-driven displacement. Safety concerns become campaign issues. The “beat China” argument may be strategically true, in Plouffe’s view, but he called it politically weak if voters feel they are paying the local costs.
Data centers are the most tangible example. Plouffe said they give citizens a target and a sense of agency because they are physical, local, and politically stoppable. People can pressure county commissions, city councils, state legislatures, or local voters. They can demand moratoriums. They can say no to a site. That makes data centers a focal point for broader anger about AI, even if they are only one part of the technology stack.
That point folds back into Baker’s infrastructure argument. If GPUs go to whoever can plug them in and turn electrons into tokens, then local permission, grid capacity, and energy politics become part of the AI supply chain. The buildout cannot be evaluated only through chip allocation, revenue, or data-center construction speed. It also has to pass through places where residents worry about electricity bills, quality of life, environmental effects, and whether the benefits stay local.
Plouffe argued that the industry’s early case for data centers overemphasized construction jobs, which are temporary. He suggested the stronger case is local and fiscal: lower property taxes, more police officers or teachers, better-funded schools, and concrete benefits that a skeptical resident can understand. But he stressed that voters may not believe corporate promises until they hear them from communities with actual experience.
The labor story is similarly difficult. Plouffe said many layoff announcements are probably a mix of real AI adoption and convenient downsizing, but the public does not need perfect attribution to become afraid. People hear AI leaders warn that jobs may disappear, that children may not need college, and that the social contract may change. If those warnings come from the same companies and executives expected to profit, distrust rises.
His communications lesson was blunt: “I’ve never met a communications problem. Ever. You just meet problems. And good communications can sometimes mitigate it, never solve it. And bad communications can make it worse.” That is a useful final frame for applied AI. The backlash cannot be handled as messaging if the public’s concerns involve jobs, energy bills, children, local infrastructure, and democratic agency.
The optimistic case remains present in Plouffe’s argument. He sees health breakthroughs, safer transportation, young people using AI productively, and new tools for learning and work. But he argued that optimism has to be paired with agency, economic pathways, local benefits, and honest tradeoffs. Otherwise, politicians in both parties may find advantage in running against AI, whether or not stopping it is practical.

