Applied AI’s Bottleneck Moves From Output To Verification
Cranmer, Hong, Finkbeiner, Gil, Voss, Microsoft, Abridge, and Cerebras each point to the same applied-AI constraint: systems are becoming useful only where their outputs can be checked, traced, governed, and acted on in time. The shift shows up in scientific workflows, agent infrastructure, healthcare operations, and inference markets, where validation, latency, privacy, and cost now determine whether AI can enter real institutional loops.

AI’s bottleneck is moving from generation to validation
AI-for-science gives the cleanest version of applied AI’s current turn. The question is no longer whether models can propose hypotheses, write code, summarize papers, search large spaces, or generate candidate answers. Kyle Cranmer, Carina Hong, and Douglas Finkbeiner each described a different scientific setting in which AI can do useful work only if the surrounding workflow has a way to check it.
Cranmer’s framing is the most portable: AI enters science at many points, including hypothesis formation, prediction, inference, experiment design, data collection, instrument control, and execution. But the value of the system depends on the contract under which its outputs are trusted. In symbolic theoretical physics and formal mathematics, the contract can be clean: a model proposes a candidate derivation or proof, and a verifier accepts or rejects it. Hong described Lean-based theorem proving in those terms. If a formal proof compiles, the score is not a vague “seems right”; it is accepted as a proof of the statement as formalized.
That is a favorable case for AI because correctness lives outside the model. Cranmer’s line that “we don’t need the model to be correct, it just needs to be good at guessing” applies when a separate mechanism can cheaply reject bad guesses. The same pattern appears in drug and materials discovery, where the model proposes molecules or materials that still have to be synthesized and tested.
Many scientific settings are less clean. Cranmer’s examples from lattice QCD and simulation-based inference put AI inside statistical and computational machinery where learned approximations must be calibrated, corrected, and wrapped in uncertainty estimates. A generative model that samples quantum field configurations does not need to be perfect if the mismatch from the target distribution can be evaluated and corrected. That produces a different kind of trust from a proof assistant: not formal certainty, but applied-mathematical guarantees about bias and uncertainty.
Lattice QCD shows why the validation burden rises with scientific ambition. Cranmer’s example of quantum-field generation involved roughly 100 billion degrees of freedom, far beyond the scale of ordinary image generation. When AI enters that kind of scientific pipeline, the error surface is not merely a bad answer in a chat window; it can become a false physical claim.
Finkbeiner’s astronomy examples show a different verification regime. At the project layer, machine learning has already become infrastructure: alert classification, survey pipelines, simulation-based cosmological inference, strong-lensing detection, active telescope operations, and literature tools. At the desk layer, the newer disruption is the AI collaborator helping graduate students with code, plots, fitting, writing, and exploration. Finkbeiner’s reported productivity paradox is important: in his hallway, AI has not necessarily produced vastly more papers, but it has made the same papers more polished, more thoroughly explored, or better visualized.
That does not remove the need for scientific judgment. Finkbeiner warned about hallucinated references, equations, and results, and about scientists becoming dependent on systems they no longer interrogate. His suggested validation rule was familiar rather than exotic: treat AI results the way an adviser treats work from a graduate student. Ask what checks were run, whether the limits make sense, whether the claim survives alternative tests, and whether the reasoning can be defended.
Dario Gil’s Department of Energy argument takes the same problem from the laboratory to the national scale. Gil said scientific advantage is moving from access to instruments and computation toward throughput through integrated discovery systems: data, models, high-performance computing, experimental facilities, robotics, and domain experts operating in tighter loops. The DOE’s Genesis initiative is his architecture for that shift.
Gil’s strongest claim is not that AI will produce more scientific text. It is that analysis can move into the experiment itself. At DOE facilities, he described AI interpreting data during beamline operations, guiding ultra-fast experimental environments, optimizing beams, screening materials, and reconstructing imaging results fast enough to change what researchers do while experiments are underway. His language of “continuous science” is the institutional counterpart to Cranmer’s workflow framing.
The metric caveat matters. Gil explicitly rejected doubling or tripling paper counts as the goal. Productivity, in his account, should mean moving a major scientific or engineering target earlier in time, reducing its cost, increasing sample-preparation throughput, shortening analysis time, or improving operational speed inside a workflow. He described Genesis applicants being asked to define how they would measure productivity and impact, making evaluation part of project design rather than a retrospective audit.
| Setting | What AI accelerates | Where trust enters |
|---|---|---|
| Formal physics and mathematics | Candidate formulas, derivations, or proofs | Proof assistants or formal verification |
| Lattice QCD and simulation-based inference | Sampling, surrogate modeling, and inference over complex simulators | Calibration, correction, robustness, and uncertainty estimates |
| Astronomy desk work | Coding, visualization, fitting, literature work, and exploration | Expert interrogation, reproducibility, and scientific judgment |
| DOE integrated discovery systems | Experiment-analysis cycles and national-scale workflows | Operational productivity metrics, closed-loop validation, and domain-expert governance |
The shared point is not that AI has solved discovery. Cranmer, Hong, Finkbeiner, and Gil each describe AI increasing the rate at which science can produce artifacts: candidate proofs, simulated samples, analyses, visualizations, experiments, and operational decisions. The unresolved question is whether verification can keep up with production. In some cases, the checker is mechanical. In others, it is statistical. In others, it is institutional and social.




Evaluation is becoming the applied AI discipline
The evaluation problem extends well beyond physics and mathematics. In a Stanford AI+Science lightning-talk session, Aishwarya Mandyam, Amar Venugopal, Steven Dillmann, and Alda Elfarsdóttir treated AI output as a claim that must be tested against a domain-specific standard. Their projects grouped into four evaluation problems: pre-deployment safety, causal validity, executable agent benchmarks, and empirical outcome testing.
Mandyam’s clinical reinforcement-learning work starts with a deployment question: before a learned clinical policy is used in a hospital, how can anyone estimate whether it will help or harm patients? Her focus on off-policy evaluation is a reminder that “the model learned a policy” is not enough. The evaluator has to estimate how the policy would perform using historical data collected under different behavior, while handling the fact that real clinical data may not cover actions the new policy would take.
Venugopal’s text-causal work makes a parallel point about generated counterfactuals. If an AI system changes a political or civic text to test whether “insults using ‘you’” affect perceived civility, the modified text may also change agreement, tone, specificity, or other attributes. Text generation can create a treatment, but causal inference still has to ask whether the treatment changed the intended thing.
Dillmann’s Terminal-Bench Science proposal moves the same logic into agents. The benchmark is meant to evaluate scientific agents on executable workflows rather than open-ended aspirations such as “do research” or “generate hypotheses.” The constraints are telling: tasks must be scientifically grounded, objectively verifiable, and difficult. The benchmark avoids activities that are too ambiguous to score cleanly. Scientific-agent progress, in that account, depends on building tasks where success and failure can be observed.
Elfarsdóttir’s climate-disclosure work treats corporate language as a signal to be tested against later emissions. Her team used language models to extract features from disclosures, but the claim becomes meaningful only because those features are linked to three-year emissions outcomes with controls and fixed effects. “It’s not what firms say, it’s how they say it” is not a slogan about language-model capability; it is an empirical claim about whether specific kinds of language correlate with later behavior.
Laurie Voss’s Arize workshop gives the applied-engineering version of the same discipline. Voss’s central warning is that evals are not a decorative dashboard added after an AI feature is built. They are the engineering loop that lets a team know what the system did, where it failed, and whether a change improved the behavior that actually matters.
His workflow begins with traces. For an agent, the final answer is often the least informative artifact. The useful evidence is in the path: the model calls, tool calls, inputs, outputs, timing, token counts, and intermediate decisions. A financial-analysis agent that produces a polished report may have searched the wrong company, written to disk instead of returning an answer, omitted the requested ticker, hallucinated a financial figure, or summarized facts without giving an investment recommendation. Those failures require different fixes.
Voss’s most memorable example is the difference between correctness and faithfulness. On the same 13 financial-agent traces, a built-in correctness evaluator scored 0 out of 13. Voss’s diagnosis was not that all 13 reports were necessarily wrong. The judge was asking a question it could not answer: whether current or forward-looking financial claims were factually correct, without having the relevant up-to-date context. When the question changed to faithfulness — whether the final report stayed grounded in the research context the agent had gathered — the same 13 traces passed.
That contrast is the practical version of the science sections’ conceptual point. The first issue is not whether the judge model is strong enough. It is whether the evaluation is measuring the right property. Correctness, faithfulness, actionability, groundedness, tool-call accuracy, policy compliance, causal isolation, clinical safety, and reproducibility are not interchangeable. An eval that is misaligned with the workflow can produce precise nonsense.
That is the strategic implication of Voss’s workshop: as AI systems enter production workflows, eval design becomes part of product design, risk management, and competitive advantage.
Voss’s recommended loop is recognizable software engineering adapted to probabilistic systems: instrument the agent, read traces, define observable requirements, categorize failures by root cause, write deterministic checks where possible, use LLM judges for semantic dimensions, validate those judges against human labels, and run controlled experiments on the same inputs before accepting a prompt or model change as an improvement.
That is why evaluation is becoming a discipline in applied AI rather than a narrow ML scoring task. In clinical policy, it determines whether a system is safe to deploy. In causal text experiments, it determines whether the treatment means what researchers say it means. In scientific-agent benchmarks, it determines whether an agent can execute a real workflow. In financial-agent development, it determines whether a team is improving a capability or only improving the appearance of competence.




Agents make observability and pre-action verification unavoidable
Agents intensify the validation problem because they do not merely answer. They choose tools, call APIs, modify state, retrieve data, coordinate sub-agents, and sometimes act before a human sees a final output. That makes observability a control system, not just a monitoring screen.
Amy Boyd and Nitya Narasimhan of Microsoft framed the problem as a widening gap between requirements and behavior. The requirements are the platform. The agent is the train. Models, prompts, tools, user behavior, and environments keep changing, so the gap can open without the developer noticing. Evaluation asks whether the agent still meets the requirement. Tracing shows how it got there. Monitoring watches the system over time. Optimization changes the system and compares versions. Red teaming asks whether an adversary can push it outside its allowed behavior.
The important phrase in Microsoft’s account is “trace-linked evaluations.” A score alone says something failed. A linked trace can show whether the wrong tool was selected, the right tool was called with bad input, the tool output was ignored, a sub-agent failed, or the final response violated the task. That matters because agent failures are path-dependent. A final answer may be bad because the agent misunderstood intent at the first step, retrieved the wrong data in the middle, or failed to use a correct tool result at the end.
The Foundry observe-skill demonstration showed where the platform story is heading. Starting from a Contoso travel agent with no existing evaluation dataset, the skill inspected the agent, generated a dataset, selected evaluators, ran batch tests, found two task-adherence failures, optimized the prompt, redeployed a new version, compared results, and eventually rolled back to the best-scoring version after later prompt variants regressed.
- BaselineThe Contoso travel agent scored 8/10 on task adherence while other shown metrics passed.
- Prompt optimizationA new version with mandatory web-search rules improved task adherence to 9/10.
- Further iterationLater prompt variants regressed to 6/10 and 8/10.
- SelectionThe observe skill identified the 9/10 version as the best-performing version shown.
The lesson is not that prompt optimization should be fully delegated. Narasimhan stressed the human in the loop. The useful shift is that parts of the observability cycle — dataset generation, evaluator setup, batch runs, failure clustering, prompt changes, version comparison, and rollback recommendations — can be automated. The developer still has to decide which failures matter, which evals are valid, and which tradeoffs are acceptable.
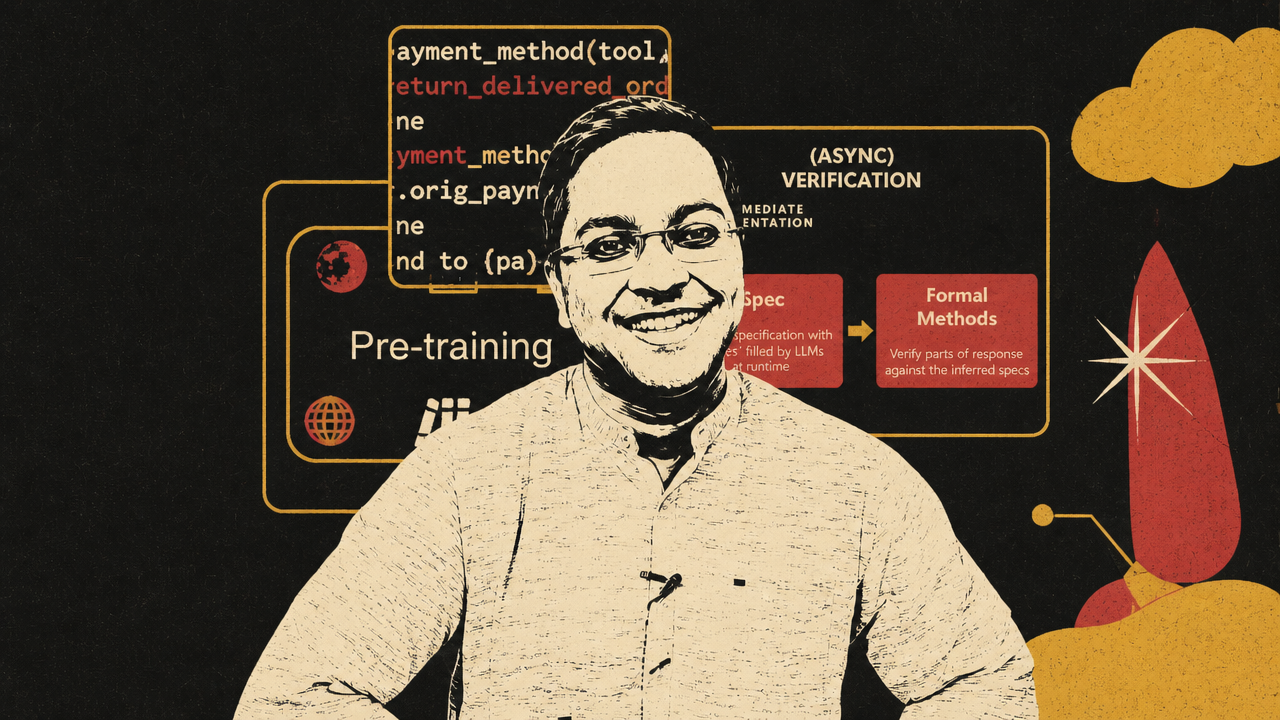
Interwhen, presented by Microsoft Research’s Amit Sharma, sharpens the safety case. If an agent sends an email, changes a database, issues a refund, books travel, or controls a robot, final-output review may arrive too late. Verification has to move inside the agent’s work, before irreversible actions occur.
Interwhen’s design separates interpretation from enforcement. LLMs project natural-language tasks, policies, and partial responses into smaller verifiable properties. Symbolic or model-based verifiers then check those properties against tool calls and intermediate behavior. In Sharma’s retail-agent example, a natural-language policy says refunds must go to the original payment method or to a gift card. Interwhen turns that into verifier logic. When an agent attempts to refund an order to a credit card even though the original payment method was PayPal, the verifier interrupts and returns a diagnostic: refund to credit card not allowed.
This is a different safety posture from post-hoc judgment. The verifier does not merely grade a transcript after the fact. It runs asynchronously while the agent acts and interrupts only when a violation is found. Sharma calls the design “fork-and-verify”: the agent can continue normally when checks pass, but execution stops when the verifier detects a policy violation.
| Layer | What it catches | Why final-output review is insufficient |
|---|---|---|
| Tracing | The path the agent took through model calls, tools, and sub-agents | A polished answer can hide the step where the failure began. |
| Trace-linked evals | Whether behavior met requirements and where it failed | A score without execution context does not show what to fix. |
| Optimization loops | Whether a change improves or regresses behavior | Manual prompt edits can improve one case while breaking others. |
| Pre-action verification | Tool calls or intermediate actions that violate policy | A refund, email, database write, or physical action may be irreversible by the time the final answer is reviewed. |
Foundry and Interwhen approach the problem from different levels. Foundry describes the operating loop for building, monitoring, evaluating, optimizing, and red-teaming agents across versions and workflows. Interwhen focuses on verified execution at the moment an agent is about to act. Together they show why agent infrastructure is moving from passive dashboards toward active control loops.



Healthcare shows what happens when the workflow cannot tolerate AI slop
Abridge is a domain case study in the same maturation story. Janie Lee and Chaitanya “Chai” Asawa do not present the company as only an ambient scribe. They describe the clinical conversation as healthcare’s intelligence layer: the event where care is given, documentation begins, claims are formed, payments are justified, follow-up is planned, and downstream workflows take shape.
That framing explains why Abridge wants to move from documentation into clinical decision support, prior authorization, billing, and broader clinical workflows. The documentation burden is the wedge. Lee said clinicians spend 10 to 20 hours a week on documentation, including after-hours “pajama time.” Reducing that burden creates immediate user value. But the larger bet is that the conversation, combined with EHR data, payer rules, medical literature, local guidelines, and clinician preferences, can support action before delays and errors cascade through the system.
The prior-authorization example makes the validation problem concrete. A doctor orders an MRI for knee pain. Weeks later, the patient is told the MRI was not approved and must return. In Abridge’s target workflow, the system would know that the patient’s Aetna plan in California requires six criteria. Four are already satisfied from context. Two are missing: physical therapy and pain lasting more than six weeks. If the doctor asks those questions while the patient is still in the room, authorization can move faster.
That is not simply a generation problem. The system has to identify the correct payer policy, parse unstructured rules, match them to the patient and plan, retrieve relevant EHR context, know what has already been established, surface only the missing information, and do it while the clinician can still act. It also has to avoid becoming another alert that clinicians ignore. Lee estimated that more than 90% of healthcare alerts are ignored and said Abridge wants the product to feel like “air conditioning”: present in the background, improving the environment, and interrupting only when timing and clinical risk justify it.
Healthcare collapses several AI tradeoffs into one workflow. Quality matters because a wrong recommendation can harm a patient. Latency matters because prior authorization and clinical action happen on real schedules. Cost matters because a product used millions of times a week cannot simply route everything through the most expensive model. Privacy matters because the raw material is protected health information. Personalization matters because notes and workflows differ by clinician, specialty, and health system. Evaluation matters because the long tail is not optional.
Asawa described Abridge’s AI problem through three product KPIs: quality, latency, and cost. The company uses a constellation of models, sometimes routing across faster and slower systems. It also has a large corpus of medical conversations, which Asawa described at the scale of roughly 100 million, though the discussion gave varying formulations around that figure. He called those conversations the trace where debugging happens in healthcare. But the data advantage is bounded by privacy: Abridge has to de-identify data, validate the de-identification models, and operate under customer contracts that govern PHI access, retention, and use.
Lee’s description of evals is especially aligned with the broader applied-AI theme. Abridge starts new product work by asking, “What does good look like?” The answer is not just model score. It includes clinical safety, completeness, style, billability, documentation that supports the work delivered, and whether the system is useful inside a specialty and health-system workflow. The company uses internal clinicians, LLM judges calibrated against annotated data, third-party evaluators, and progressive rollout. Lee described “clinician scientist” roles: people with clinical backgrounds who are also technical enough to help define evaluation criteria and product behavior.
This is why Asawa’s phrase “AI slop” is useful. He defines slop as AI without context. In healthcare, generic fluency is not merely low value; it can be dangerous. The useful system has to know the patient, the clinician’s preferences, the specialty, the local guideline, the EHR record, the payer requirement, the privacy boundary, and the timing of the visit. If it is late, care is delayed. If it interrupts too often, clinicians ignore it. If it is wrong, patients can be harmed. If it uses data too freely, trust and compliance break.
Abridge’s leaders therefore describe an AI product that looks less like a chatbot and more like institutional infrastructure. It listens, retrieves, reasons, writes, suggests, and sometimes prompts, but always inside a workflow where humans remain accountable and where evaluation is clinical, operational, and technical at once.


Infrastructure markets are pricing the same shift
Cerebras’s IPO put a market price on a narrower but related constraint: fast inference. John Coogan and Jordi Hays framed the listing not just as an AI-chip event, but as evidence that low-latency inference is becoming a product category of its own. Andrew Feldman’s strongest claim is that speed changes workflows and eventually consumes demand for slow AI responses. Doug O’Laughlin’s critique is that Cerebras’s wafer-scale SRAM architecture may be extremely fast for certain workloads while facing real memory-scaling and model-size constraints.
The first-day numbers made the debate public. Coogan said Cerebras priced at $185 per share after an IPO range that had already moved up. The stock opened at $350 and later traded around the $300–$320 range while still far above the IPO price. Hays said the company was sitting around a $64 billion market cap during the discussion. That market reaction matters only insofar as it reveals what investors are willing to underwrite: not generic “AI chips,” but the possibility that a valuable slice of inference demand will pay for speed.
Coogan’s user-experience argument is straightforward. A slow LLM response still feels like watching someone type. A fast response feels more like a page load: the content appears, and the user can act. In coding workflows, he argued, the preference is even clearer. Users do not want theatrical typing; they want the code. Hays compared speed to labor productivity: if two workers have the same capability but one is five times faster, the faster worker creates more value.
Feldman turned that into a market thesis. Once AI becomes real-time, he argued, users do more things, stay longer, attempt harder problems, and build new products around the new response profile. His analogy was Netflix: faster internet did not simply make DVD delivery more efficient; it enabled streaming and changed the company’s business. In his formulation, the market for slow inference eventually resembles the market for dial-up internet.
O’Laughlin supplied the necessary technical limit. Cerebras’s architecture relies heavily on SRAM on the wafer. SRAM is fast, but he argued that SRAM scaling is “dead” in the sense that it is not shrinking fast enough to give Cerebras a simple memory-growth path. Coogan noted that Cerebras’s WSE-2 had 40 gigabytes of memory and WSE-3 had 44 gigabytes, a modest increase. Because the wafer has fixed area, more memory can mean less compute area. As frontier models, context windows, and agentic workloads grow, memory capacity and movement become central constraints.
That does not make the Cerebras opportunity trivial or false. O’Laughlin’s revised view was that Cerebras may have a viable role in a disaggregated inference stack, such as specialized prefill or attention/feed-forward configurations, and that even a small share of a very large AI compute market can be valuable. His line that “1% of a very large market works” is the skeptical bull case: Cerebras does not have to replace the GPU to matter.
The infrastructure point connects directly back to science, healthcare, and agents. Latency and capacity are not backend details once AI is inside operational loops. A clinical assistant that surfaces a prior-authorization question after the patient leaves has missed the moment. An agent that has to verify tool calls before irreversible action needs the verification and response loop to fit within the workflow. A scientific experiment that can adjust while data is being produced needs inference and analysis fast enough to affect the run. A coding agent that can test, observe, and repair in tight loops becomes a different product from one that returns minutes later.
The Cerebras debate is therefore not separate from validation. It is one of the enabling conditions for validation to operate in real time. Fast inference is useful because applied AI is moving from isolated outputs into systems that retrieve, reason, verify, act, observe, and revise under time constraints. The open question is which workloads fit specialized hardware such as Cerebras, which require larger GPU or TPU systems, and how much of the AI economy will pay a premium for low latency.

