Choosing The Right Eval Matters More Than Tuning The Judge

Laurie Voss of Arize argues that agentic applications need the same engineering discipline as other production software: instrumentation, inspectable traces, targeted evals, and controlled experiments, not a handful of prompts that “look right.” In a hands-on workshop using a financial analysis agent, Voss shows how teams should read traces before writing evals, classify failures by root cause, and combine deterministic checks, LLM judges, custom rubrics, and human-labeled meta-evaluation. His central warning is that the choice of eval can dominate the result: the same agent scored 0 out of 13 on a correctness eval and 13 out of 13 on a faithfulness eval because the first judge was asking the wrong question.
The first eval is reading the traces
Laurie Voss frames evals in deliberately ordinary engineering terms: traces are logs for AI systems, and evals are tests for AI systems. A trace records what the AI application did at runtime: each agent call, tool call, LLM invocation, input, output, timing field, token count, and related metadata. The building blocks are spans. An LLM call is a span, a tool call is a span, and an agent turn is a span that can contain other spans.
That mental model matters because evals are often explained in machine-learning jargon when AI engineers need a testing workflow. The workflow demonstrated here is not “pick a benchmark and run it.” It begins with instrumentation, then trace inspection, then failure categorization, then eval design.
The agent under test is intentionally simple: a financial analysis chatbot built with the Claude Agent SDK. It takes stock tickers and a focus area, runs a research turn using web search, then runs a writing turn that compiles the research into a concise report. The Claude SDK client maintains context between the turns, so the writing step has access to the research step’s findings. Voss uses Claude Haiku for the agent because, in his words, it is “reliably dumb”: cheap, fast, and likely to make enough mistakes to produce useful failures.
The tracing setup is similarly minimal. The notebook installs the Claude Agent SDK, OpenInference instrumentation for the Claude Agent SDK, Arize Phoenix, and Anthropic. Then it imports phoenix.otel, calls register, assigns a project name, and enables auto_instrument=True. Voss describes those two lines as “the magic” because the instrumentation package already knows how to hook into the framework and emit the relevant OpenInference-on-OpenTelemetry spans. He also wraps the two-turn financial_report function in a custom OpenTelemetry span so that the research and writing turns appear as one top-level agent trace rather than separate traces.
The resulting trace is the first serious artifact. For a Tesla query focused on “financial performance and growth outlook,” the agent produces a report that looks credible: an executive summary, Q4 2025 highlights, a 2026 outlook, growth drivers, and risks. But Voss repeatedly draws the distinction between “looks pretty legit” and “good enough to ship.” Phoenix reveals that the agent conducted multiple web searches before writing, including queries about financial performance, 2026 growth outlook, quarterly revenue and margins, and Cybertruck production and Roadster demand.
That visibility is the point. A single input-output pair does not explain an agent’s behavior. The trace shows the decisions the agent made on the way to its answer, and for agents those intermediate decisions are often where the failure starts. A top-level financial_report span expands into nested Claude SDK response spans and multiple WebSearch spans, while the attributes panel exposes fields such as model name, cost, prompt tokens, completion tokens, total token count, input, and output. The UI is not merely a dashboard; it is the place where the agent’s hidden path becomes inspectable.
The vibe is good, but we want to be doing better than vibes.


The common alternative is what Voss calls the “vibes problem”: teams run a few prompts, decide the output looks right, ship, and only discover later that the feature fails on edge cases, adversarial inputs, or ordinary users using unexpected vocabulary. Conventional unit tests do not map cleanly onto LLM output because the same prompt can produce different text on every run, and many different texts may all be correct. Human review does not scale, does not catch regressions reliably, and does not run in CI.
Without evals, a team cannot safely change a system prompt to fix tone, because that change can affect every kind of input the agent handles. The tone may improve while the bot starts hallucinating product features. A team also cannot safely switch models. New models arrive frequently, and they are not merely “better”; they are different. A prompt that worked for one version of Sonnet may not work for the next. With evals, a model upgrade becomes a regression run. Without them, it becomes weeks of manual testing.
Agents fail through paths, not just answers
The reason tracing is prerequisite rather than garnish is that agents introduce cascading failure modes. A single LLM call is input to output. An agent may go from input to tool call, tool result, reasoning step, another tool call, another result, and only then final output. Each step can be right or wrong, and each step conditions the next.
Voss’s example is deliberately blunt: ask an agent for a report on Tesla, and the research step might decide the user means Nikola Tesla. The writing step could then produce a polished investment case based on the wrong entity. The user sees a confident, coherent response, which is worse than an obvious failure because it invites trust.
The opposite problem also matters: agents can be correct in ways the evaluator did not anticipate. Voss warns against writing evals that require a particular path, such as “call tool A, then tool B, then make decision C.” An upgraded model may solve the same problem in fewer steps or find a better path. If the evaluator is too prescriptive about the route, it will fail correct behavior.
This is why the distinction between testing the output and testing the path matters. The path matters for diagnosis, but evals that gate correctness should usually measure what the agent produced, not whether it followed the engineer’s imagined sequence. In the financial agent, there is no stable number of web searches that constitutes success. One run may need four searches; another may need more or fewer. The test cannot be “did it search exactly four times?”
Voss also separates capability evals from regression evals. A capability eval is a hill to climb: a task the agent currently does badly and should improve on. Once the agent reaches consistent success, that eval becomes a regression eval. The suite should then preserve that ability while a new capability eval becomes the next hill.
That distinction becomes important later when cost enters the workflow. Regression suites can often be compressed to representative samples; capability evals are where spending more may be justified, because they measure the behavior currently being improved.
Before writing evals, define what “works” means
Laurie Voss’s strongest procedural claim is that teams should read traces before writing evals. A financial report cannot be judged against “thorough” or “in depth” as requirements because those words do not define observable success. For this agent, a good report must be actionable: it should help decide whether to buy, sell, or hold. It should distinguish forward-looking analysis from historical summary. It should provide recommendations, not just facts.
Defining success is cross-functional work. Engineers may look at a report and say it seems legitimate; domain experts or actual users may say it is useless. Product managers, customer success teams, salespeople, and users can all contribute to the definition of “good,” including to deterministic code evals when they can specify required fields or required content.
The workshop uses 13 top-level traces: the first Tesla run plus 12 test queries. The set includes single-ticker analyses for AAPL, NVDA, AMZN, GOOGL, MSFT, META, TSLA, RIVN, KO, and others; multiple focus areas such as revenue growth, AI chip demand, AWS performance, advertising revenue, metaverse investments, dividend stability, vehicle deliveries, and profitability trends; and one comparative AAPL/MSFT analysis. This variety is meant to show why test data has to resemble production data. A suite that only tests Apple and Nvidia may create false confidence because those are large tech companies with abundant public information.
Edge cases matter for the same reason: non-existent tickers, multipart questions, jailbreak attempts, adversarial inputs, and less common user phrasings. Before production, synthetic LLM-generated queries are acceptable. After production, real user traces are better. Voss gives three versions of the same intent: “Research Tesla financial performance,” “What’s going on with Tesla stock?”, and “Yo, is Tesla a buy right now?” The agent should handle all of them, but their surface forms differ enough that outcomes may differ.
The trace review surfaces concrete failures that a generic eval would not have found cleanly. In one Apple-related trace, the agent does research and then tries to write the report to disk because it appears to treat “write a report” as “create a markdown file.” The notebook environment does not have the expected write permissions, so the tool call fails. Voss says he did not anticipate this failure when building the demo. It came from a vague requirement: write a report, but not explicitly “write a report to the output.”
Another report is thorough but not actionable: it describes Apple and Microsoft’s market positions and financial performance but does not say whether to buy. A Nvidia report similarly provides detailed research but no investment directive. An Amazon report focuses on AWS and fails to mention Amazon as a company. A Rivian report gives suspiciously specific figures that Voss says he cannot verify from his own knowledge and therefore treats as a possible hallucination or unverifiable data problem.
The important move is not merely labeling these as “bad.” The root cause matters. Did the agent retrieve bad sources? Did it attempt the wrong tool? Did it have the right data but draw no conclusion? Did it invent a stock price? Each answer implies a different fix.
Voss manually categorizes the 13 traces. The rough distribution is:
| Root cause category | Count |
|---|---|
| Looks good | 5 |
| Possible hallucination | 4 |
| Reasoning gap | 2 |
| Unverifiable data | 1 |
| Missing recommendation | 1 |
That yields a failure rate of roughly 61.5% in the toy dataset, but prioritization cannot be based on frequency alone. Severity matters. A rare failure in which the agent goes completely off the rails may deserve more attention than a frequent awkward sentence. The prioritization rule is frequency times severity: fix the expensive frequent failures first.
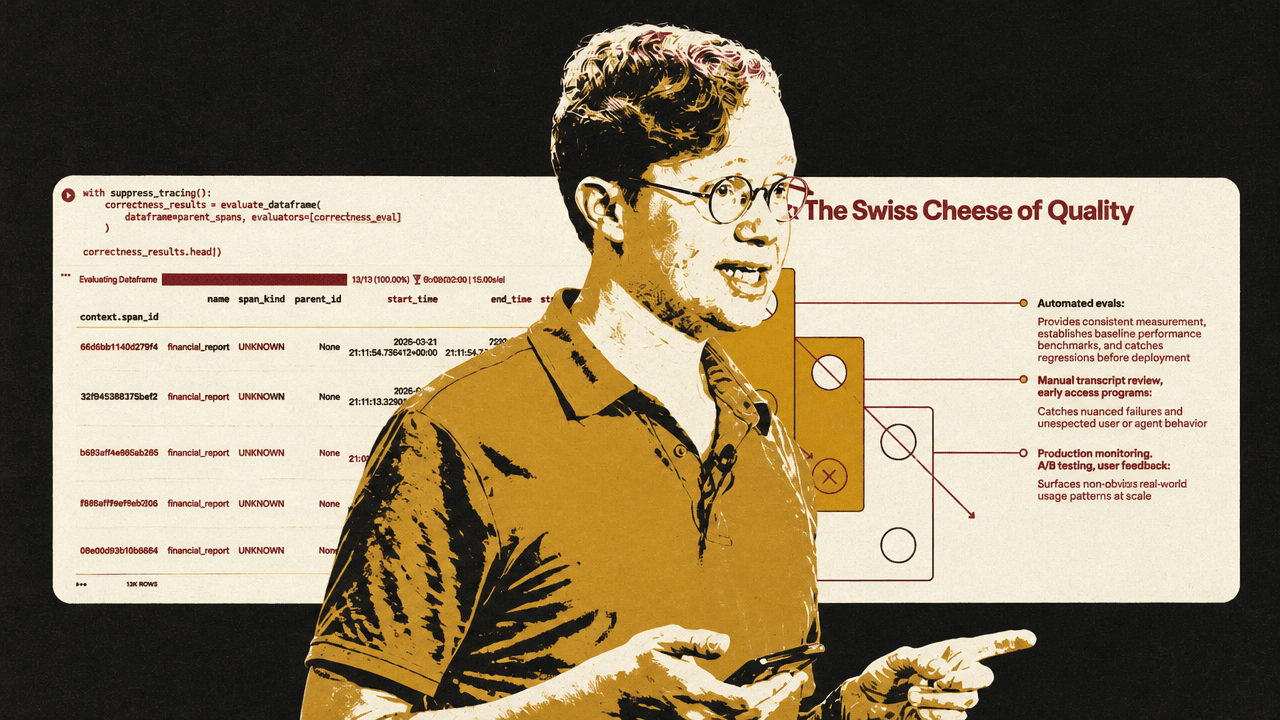
This is where Voss introduces the Swiss cheese model, borrowed from safety engineering and shown as layered quality defenses. No eval layer is perfect. Code evals catch basic deterministic problems. LLM judges catch semantic and reasoning gaps but may miss subtle hallucinations. Human review catches issues that automated layers miss but cannot scale. Layering these defenses reduces the chance that the same failure passes through every hole.
A cheap code eval catches real failures
The first eval is intentionally simple: check whether the output mentions the ticker requested in the input. Because the agent is supposed to analyze stock tickers, failing to mention the ticker is a basic red flag. No LLM is needed. The evaluator extracts uppercase tokens that look like ticker symbols, filters out common non-ticker uppercase strings such as AI, US, CEO, CFO, IPO, ETF, AWS, and ESG, and checks whether the likely ticker appears in the output.
The code eval uses Phoenix’s create_evaluator decorator with kind="code", then runs against the parent spans using evaluate_dataframe. Tracing is suppressed during eval execution because otherwise Phoenix would capture traces of the evaluator’s own calls, which would confuse the dataset.
The result is not trivial: 11 of 13 reports pass, and two fail. The missing tickers are TSLA and AMZN.
The Tesla failure corresponds to the earlier write-to-disk behavior. The Amazon failure is more interesting: the agent writes the report about AWS and never mentions Amazon. A simple string check reveals a real product issue, not merely a toy problem.
Code evals are appropriate for format, structure, and constraints: valid JSON, length limits, forbidden phrases like “as an AI language model,” required fields, or required terms. A deterministic evaluator can also query a database, call an API, or check a price if the grading answer is stable. Code evals are fast, cheap, reproducible, and should be used wherever the condition is deterministic.
The caveat is brittleness. Code evals should allow for equivalent outputs when equivalence is real. If an agent is asked for a duration, “2 hours,” “120 minutes,” and a corresponding number of seconds may all be valid. If the eval only accepts one surface form, it will punish correct answers.
The right eval matters more than the built-in label
Laurie Voss’s most consequential demonstration is that a plausible built-in evaluator can be entirely wrong for the job. A financial report sounds like it should be tested for correctness. But when the report concerns current or forward-looking financial data, a judge model without the relevant up-to-date context cannot reliably fact-check it from its own training data.
Voss runs Phoenix’s built-in correctness evaluator using Claude Sonnet as the judge. The evaluator is designed to assess whether each response is factually accurate, complete, and logically consistent. LLM-as-a-judge evals have separate pieces: the judge model, the prompt template or rubric, the criteria, and the data being evaluated. Keeping those separate allows teams to test the same rubric with different models or the same model with different rubrics.
The result is stark: all 13 traces receive a correctness score of zero.
That result is not treated as proof that every report is factually wrong. The explanations matter. The judge complains about highly specific 2026 financial figures and says they are fabricated. Voss’s diagnosis is that the judge model does not know the relevant future or current financial data. It was trained before the period being discussed and is trying to fact-check forward-looking financial reports against stale model knowledge.
The correctness eval is therefore “complete garbage” for this use case, in Voss’s phrasing. It asks the wrong question. If the application were answering general knowledge questions that the judge could evaluate from its training distribution, correctness might be useful. For real-time or future-looking financial analysis, a judge without current context cannot determine factual correctness from its own knowledge.
The right question is faithfulness: did the final report stick to the source material the agent actually found? Because the financial agent was split into a research turn and a writing turn, the evaluator can use the research turn’s output as context and judge whether the final report is grounded in that context. This requires reshaping the trace data into the columns the faithfulness evaluator expects: input, output, and context. The context is specifically the output of the research turn, not the final report.
With that context, the faithfulness evaluator passes all 13 traces.
The contrast is the sharpest lesson in the source: two built-in evals, run on the same traces, produce opposite signals. Correctness gives 0 out of 13; faithfulness gives 13 out of 13. The narrower point is important: faithfulness does not prove the financial reports are true. It says the reports stayed grounded in the research context supplied to the judge. Correctness failed because it tried to answer a different question with insufficient temporal context.
Choosing the right eval can matter more than tuning the eval. Some evaluators will be useless for a given task because they measure the wrong thing. Others will align closely with the actual failure mode.
Phoenix then becomes a workbench for filtering and drilling into the annotations. A user can filter traces by expressions such as annotations['correctness'].label == 'incorrect', sort by scores, and inspect explanations. On 13 traces this is convenient; on 1,000 traces it becomes essential because it lets teams focus only on failures.
A custom rubric needs one observable dimension
Built-in evals are starting points. The custom eval targets the requirement discovered during trace review: actionability. Phoenix does not have a built-in evaluator for “is this an actionable financial report,” so Voss builds one.
The operational rule is to measure one dimension clearly. If the business requirement is actionability, the rubric should define actionability in observable terms and judge that dimension directly. It should not become a single “God evaluator” that also tries to decide accuracy, tone, completeness, policy compliance, formatting, and every other quality attribute at once.
A good eval prompt, in Voss’s structure, has five parts:
| Rubric part | Purpose |
|---|---|
| Define the judge’s role | Tell the judge the domain and what kind of output it is evaluating. |
| Explicit correct / incorrect criteria | Make success and failure observable rather than aspirational. |
| Present the data clearly | Separate the user query from the financial report with clear boundaries. |
| Add labeled examples | Show the judge what actionable and not actionable outputs look like. |
| Constrain the output labels | Force a small set of labels such as actionable / not actionable. |
For role definition, the prompt says the judge is an expert financial analyst evaluator whose task is to decide whether a report provides actionable investment guidance, not just raw data. The “you are an expert” pattern may help a little, according to Voss, but the actual instructions matter much more.
The criteria are where many teams under-invest. “A good response is helpful and accurate” is not enough because “helpful” and “accurate” are not operational definitions. The actionability rubric defines an actionable report as one that contains specific buy/sell/hold guidance or equivalent, identifies concrete risks with supporting data, includes forward-looking analysis rather than only historical data, and explains why the recommendation is made. A not-actionable report merely summarizes public data, lacks specific recommendations or next steps, presents risks without supporting evidence, or stays backward-looking.
These criteria come directly from observed traces. The Apple/Microsoft and Nvidia outputs were not necessarily wrong, but they lacked the specific investment directive the agent was supposed to provide.
Data presentation is equally explicit. The prompt uses blocks such as [BEGIN DATA], labels the user query and the financial report, then closes with [END DATA]. Claude is described as responding well to XML-style boundaries, but the general principle is to clearly mark what is input and what is output so the judge does not confuse them.
Examples are the part Voss most strongly recommends. The actionable example includes numeric growth, a risk, valuation context, and a specific recommendation: accumulate on pullbacks below a price. The not-actionable example says Nvidia is a major semiconductor player, has grown from AI demand, and investors should consider various factors. It is not false; it simply does not tell the user what to do.
Finally, the output is constrained. Binary labels are preferred where possible: actionable or not actionable. If more nuance is genuinely needed, three categories may be acceptable. But ratings from 1 to 10 are noisy unless every distinction is defined. The difference between a 6 and a 7 is not obvious to the model unless it has been specified.
Voss also recommends chain-of-thought-style reasoning for judges: ask the evaluator to explain its thinking before the final label because generating reasoning tokens can improve judgment quality. In the live notebook, an audience member notices that the displayed actionability prompt does not include that instruction. Voss acknowledges the omission: he had just told the room to do it and then left it out.
The evaluator itself is a Phoenix ClassificationEvaluator. It takes a name, the prompt template, the LLM judge, and choices mapping labels to scores: actionable as 1.0 and not actionable as 0.0. On the source data, it produces a mixed result: some reports are actionable and some are not. Voss treats this as a proper capability eval because the agent has headroom to improve. A trace explanation for a failure says the report lacks a concrete buy/sell/hold recommendation; another says the report has strong financial data and forward-looking analysis but lacks an explicit investment directive.
Two design constraints follow from this.
First, treat eval prompts like code. Version them. Test them against known answers. If changing a word in an agent prompt can change behavior, changing a word in a judge prompt can change scores. An unvalidated eval, Voss says, is “just a fancy way of being wrong at scale.”
Second, avoid the God evaluator. Do not build one LLM judge that tries to assess accuracy, tone, completeness, policy compliance, formatting, and business quality all at once. It is hard to calibrate, and if it fails, the team does not know why. Use one evaluator per dimension. Some evals are guardrails and should block shipment, such as hallucinating a stock price in this financial agent. Others are north-star or nice-to-have metrics, such as consistently recommending complementary investments. Teams need to know which is which.
The Q&A refines this point. One attendee asks whether the four actionability criteria and four non-actionability criteria should be split into eight separate checks. Voss answers that it depends on what stakeholders actually care about. If the requirement is specifically “must mention price-earnings ratios,” then that deserves its own eval. If a PE ratio merely contributes to the broader goal of making a buy/sell/hold recommendation, then actionability can remain the dimension being judged. The key distinction is between the actual definition of correct and a contributor to correct.
Meta-evaluation is testing the test
Laurie Voss describes an LLM judge as a classifier. It predicts pass or fail, actionable or not actionable. Those predictions can be compared against ground truth, which in this context means human labels. Meta-evaluation is checking the judge’s homework.
In Phoenix, a user can manually add annotations to traces, such as human_actionable, or do so programmatically. The point is to build a golden dataset: examples with known labels that reflect the judgment of domain experts. Humans should not label arbitrarily either. They should use the same clear criteria given to the LLM judge, with examples and minimized ambiguity, otherwise the human labels will have the same vagueness problem as the model.
The golden dataset should grow over time. Production failures become tomorrow’s test cases. It should also be split into development and test portions because an eval rubric can overfit the examples it has seen. Voss suggests a split such as 75/25: iterate on one portion, then test changes against held-out examples the rubric has not been tuned against.
In the toy meta-evaluation, the actionability judge is compared to a small set of human labels and disagrees on two of six examples. This is not evidence about the quality of the actionability judge. Voss explicitly says the human labels in the demo were assigned more or less at random to create data for illustration, and six examples are far too few for real measurement. A real labeled set might be 20, 50, 100, or 200 examples.
The metrics introduced are precision and recall. Precision answers: when the judge says “fail,” is it right? Recall answers: of all real failures, how many did it catch? In the demo’s tiny confusion matrix, precision is shown as 100% and recall as 33%, but those numbers are illustrative only because the labels are toy labels and the sample is too small. The conceptual point is still important: most eval scenarios should prioritize recall, because a false positive sends a trace to human review, while a missed real failure reaches users. But the right tradeoff depends on the application.
Known LLM-judge biases complicate this. Position bias means a judge may favor the first or last option when comparing outputs. Length bias means longer responses may score better. Confidence bias means a judge can be fooled by confidently wrong text. Self-preference means the same model family may rate its own outputs more favorably. One mitigation for self-preference is to use a different provider for judging than for generation, such as using Claude for the agent and OpenAI for evals.
The benchmark is not perfection. Voss says human inter-rater reliability can be low, with Cohen’s kappa often around 0.2 or 0.3. Two experts may disagree even with the same rubric and the same output. If an LLM judge is more consistent with human labels than humans are with each other, that may be a win.
Failures should also “seem fair.” If a failing trace looks correct to a human, the issue may be the eval. Voss cites Anthropic’s CORE-Bench experience: Claude Opus initially scored 42% on a benchmark, but inspection found problems with the eval itself, including exactness failures such as expecting 96.12 when Claude returned 96.124991. After fixing the eval, the score jumped to 95%. The lesson is that evals should be inspected, not blindly trusted.
Experiments turn prompt changes into controlled comparisons
Once failures are identified and evals are in place, the workflow moves from measurement to improvement. The problem with a one-off prompt fix is that it can return the team to vibes: change the prompt, run a few examples, decide it looks better. Experiments are the structure that prevents that.
The workflow is to save failing traces as a dataset, update the agent based on eval explanations, and run the same inputs through the new version using the same evaluator. In Phoenix, Voss adds the six traces that failed the actionability eval to a dataset named for the financial-agent failures. He does not rerun all 13 traces, and in production he would not necessarily rerun thousands on every small prompt change. He tests the specific failures he is trying to improve.
The prompt changes map directly to observed failures. The research prompt now explicitly asks for specific financial ratios, recent news, and current price data. The writing prompt explicitly demands a buy/sell/hold recommendation. Voss emphasizes that he is not randomly prompt-tweaking; the changes come from explanations produced by the evals.
He calls this data-driven prompt engineering: use traces and judge explanations to identify failure modes, then feed those findings back into the agent. The experiment runs an improved financial_report task over the failure dataset using the same actionability evaluator. In the demo, the revised agent turns all six previous actionability failures into passes.
That result is deliberately workshop-sized, not a claim that the agent is now generally solved. In production, a prompt change would usually produce marginal improvement across a larger dataset, not a one-shot jump. Sometimes a change makes scores worse, and the team should revert and try something else. That is another reason to version prompts and treat them like code.
A Phoenix experiment, as Voss describes it, does not care what the task does. It can run the full agent, or it can run only a cheaper subcomponent. If the failure is tool selection, the experiment can target tool calling rather than the entire agent. That can make iteration cheaper and faster.
The core experimental control is simple: same inputs, same evaluator, different agent version. The only intended variable is the change. Non-determinism still matters; ideally, teams would run examples multiple times to account for variation. Voss later connects this to pass@k and pass^k. But even a single run per example can give directional signal in a workshop-scale setting.
For sample sizing, Voss gives concrete guidance. Twelve to 20 examples are enough for directional workshop-style signal. Shipping decisions should use roughly 200 to 400 samples. He illustrates why with confidence intervals: at a 3% defect rate, 200 samples produce a 95% confidence interval from 0.6% to 5.4%, which may still exceed a 5% threshold. Doubling to 400 samples tightens that interval to 1.3% to 4.7%, but doubling samples doubles labeling and evaluation effort. Halving margin of error requires four times the samples, so teams must make cost-benefit decisions.
The highest-impact fixes are usually not hyperparameters
Laurie Voss’s impact hierarchy is blunt: fix data quality first, then prompts, then model choice, then hyperparameters.
If an agent searches the wrong sources or relies on stale data, no amount of prompt engineering will make it reliable. Once the data is good, prompting improvements such as explicit instructions, constraints, and few-shot examples often have the highest return. Model selection comes next: a more capable model may solve problems that prompting cannot, but it costs more. Hyperparameter tuning — temperature, top-p, and similar settings — is at the bottom because Voss says it rarely changes outcomes meaningfully compared with the others.
This hierarchy connects to eval-driven development. A team can write the eval before building a capability. If a customer-support agent must verify identity before issuing a refund, write the eval for that behavior first, then give the agent a hill to climb. Voss compares this to test-driven development: widely praised, less often practiced.
He says Claude Code evolved this way at Anthropic: capability evals came before capabilities, so when new models arrived, Anthropic could immediately see which bets had paid off. The same structure lets teams adopt new models faster. With a comprehensive regression suite, a new model can be evaluated quickly. Without it, switching models means weeks of manual testing.
The data flywheel is the longer-term version of the same idea: log, sample, review, improve, repeat. Each production failure becomes a test case. Each expert label grows the golden dataset. Voss argues that this becomes a competitive advantage because no competitor has exactly the same production traces, labels, and failure catalog.
Cost and reliability determine how the loop runs in production
Production evaluation changes the question from “can this evaluator find a failure?” to “how much signal can the team afford to collect, and where does that signal matter?” Voss’s answer is not to run every eval everywhere. It is to attach cost, reliability, and monitoring choices back to the same trace-eval-experiment loop.
Production monitoring means running evals on sampled live traffic and alerting on sustained score drops rather than individual failures. This can catch model quality drops, adversarial attacks, and drift as product usage changes. Failures found in production should be routed back into the test suite, turning live incidents into future regression cases.
Cost-aware evaluation recognizes that not every query needs the same model. “What are your hours?” should not require the same horsepower as a comparative analysis of five semiconductor companies. Voss introduces cost-normalized accuracy as accuracy divided by cost. An agent that is 92% accurate at $0.02 per query may be better value than one that is 95% accurate at $0.15 per query. Evals make that tradeoff measurable rather than speculative.
Pairwise evaluation is another alternative to unreliable scoring. Rather than ask a judge to rate an output from 1 to 10, ask whether output A is better than output B. Voss says LLMs handle comparative judgments better because they have concrete examples. To control for position bias, run the comparison twice with order swapped.
Reliability scoring separates two notions that are often conflated. Pass@k asks whether at least one of k attempts succeeds. Pass^k asks whether all k attempts succeed. As k grows, pass@k approaches 100% while pass^k approaches zero. A coding assistant may be acceptable if it eventually gets the answer right after retries; a customer-support assistant that fails every fifth attempt is not acceptable, because any single bad answer may reach a customer.
The Q&A adds a practical cost boundary. One attendee asks how much evaluation is enough when live-trace evals can cost more than the feature itself. Voss answers through the distinction between regression and capability evals. If a team has 100 regression evals and one capability eval, it may not need all 100 regressions on every run. Regression suites can be shrunk, downgraded, or sampled. Capability evals are where he would spend more, because that is where the agent is actively improving. On live traces, he says there is no point running capability evals if the capability is not changing; live monitoring is mainly for regression.
Another attendee asks whether evals should be introduced in phases because failures can come from many places: the agent prompt, the rubric, or unreliable human annotations. Voss agrees and recommends iterative construction. Start with a code eval and ensure it works. Then add one LLM judge and validate it. Avoid introducing multiple new eval prompts at once, because then a change can affect several moving pieces simultaneously.
A related question asks whether changing a rubric requires rerunning an entire 500-example dataset. Experiments are meant to avoid that. Use a smaller failure set to hill-climb quickly. Once improvement seems to plateau or a shipment decision approaches, run against the entire dataset to check for regressions or overfitting.
The same logic applies to more automated futures. One attendee describes using repeated Claude Code runs to scope architectural compliance checks and measuring consistency as a proxy for problem complexity. Voss connects that to meta-evaluation and multi-agent configurations: an LLM can judge possible agent configurations, and a closed loop could generate prompt variations, test them against evals, and choose the version that improves. He treats closed-loop, self-improving software as visible on the horizon but still difficult to make work reliably today.