Inference Turns AI’s Bottleneck Into A Stack-Wide Constraint
Today’s applied AI sources traced the same constraint from model serving to public markets, data centers, venture strategy, and workplace agents. Stanford’s inference lecture framed the technical root: generation is sequential, often memory-bound, and increasingly defined by KV-cache movement, while the rest of the brief showed how that bottleneck is being translated into hardware valuations, powered-shell construction, policy fights, orchestration layers, and trust problems inside companies.

The new AI bottleneck is inference, not just training
The most useful technical claim in today’s source set came from Stanford’s CS336 inference lecture: serving a language model is not a smaller version of training. It is a different systems problem.
Training is expensive, but it happens in bounded runs. Inference happens every time a user asks for a response, every time a coding agent explores a branch, every time an enterprise workflow calls a model, every time a system evaluates outputs, and every time a reinforcement-learning loop generates rollouts. Percy Liang’s lecture framed that distinction with token volume: estimated OpenAI inference was described at roughly 8.6 trillion tokens per day, while DeepSeek V4 was trained on 32 trillion tokens. The point was not that a day of inference is literally equivalent to a training run. It was that live serving has become large enough to demand its own engineering and economic model.
The bottleneck is especially sharp because autoregressive generation is sequential. During training, a Transformer can process all tokens in a sequence in parallel. During generation, the model emits one token at a time, and each next token depends on the tokens already generated. Liang and Tatsunori Hashimoto separated inference into two phases that matter for the rest of today’s market stories. In prefill, the model processes the user’s prompt and populates the key-value cache. In generation, it repeatedly reads from and extends that cache as it produces tokens.
The lecture’s core claim was that generation-time attention is often memory-bound, not compute-bound. The model is not simply doing dense matrix multiplication at full accelerator utilization. It is repeatedly moving key-value cache data through memory. The KV cache is useful because it avoids recomputing all previous attention states from scratch. But at serving time, that cache becomes the object everyone is trying to shrink, page, quantize, share, or avoid.
KV cache movement matters because each request has its own history. Batching can help amortize shared model weights across many requests, especially for MLP layers. It does not make generation-time attention efficient in the same way, because the relevant cache data is not shared across unrelated users. Larger batches can improve throughput, but they also add latency and memory pressure.
| Inference phase | What the system is doing | Why it matters |
|---|---|---|
| Prefill | Processing the prompt and filling the KV cache | More parallelizable and easier to make compute-bound |
| Generation | Producing tokens one at a time while reading and extending the KV cache | Sequential and often memory-bound |
| Batching | Serving multiple requests together | Improves throughput but can worsen latency and memory demand |
| Cache reduction | Shrinking or sharing what must be stored and moved | Targets the core serving bottleneck |
That mental model explains why so many techniques that look unrelated are actually answers to the same question. Grouped-query attention reduces the number of key-value heads stored. Multi-head latent attention stores a compressed latent representation rather than full key and value vectors. Quantization reduces the bytes moved. Pruning and distillation try to make smaller models preserve enough behavior. Speculative decoding uses a smaller draft model to propose tokens and a larger model to check them faster than it could generate them serially. Continuous batching and PagedAttention borrow from systems scheduling and operating-system memory management to handle live traffic with uneven request lengths and shared prefixes.
The market relevance is direct. “AI demand” is not an abstract desire for larger models. Increasingly, it means serving intelligent work repeatedly, with acceptable latency, at a cost that does not make the product uneconomic. That is why inference shows up downstream in chip valuations, cloud commitments, data-center construction, enterprise orchestration, and agent feasibility. If the live workload is memory-bound and dynamic, then the companies that move fewer bytes, reuse more cache, manage live traffic better, or route work to cheaper adequate models have a real claim on the bottleneck.
The money is chasing inference because the hard problem has become serving intelligent work repeatedly, quickly, and cheaply. The Stanford lecture supplies the systems reason: generation is sequential, attention is memory-bound, and KV-cache movement is now central to the economics of serving models.


Cerebras is the public-market test of the inference story
Cerebras turns that systems argument into a public-market test. Alex Wilhelm and Jason Calacanis treated the company’s raised IPO range as a clean question: are investors buying current revenue, or are they buying the possibility that inference demand turns today’s revenue into a small base?
According to Wilhelm, Cerebras lifted its IPO range from $115–$125 per share to $150–$160. At the top of that range, he said the company could be valued at $34.4 billion on a simple basis, or $48.8 billion fully diluted. The most recent quarterly revenue discussed was $171.4 million. Annualized, that is a $686 million run rate. Wilhelm calculated roughly 50 times run-rate revenue on the simple valuation and about 71 times on a fully diluted basis. Calacanis stressed that those are revenue multiples, not earnings multiples.
That price is easier to understand if the buyer believes inference is now structurally scarce. Wilhelm pointed to a 750 megawatt OpenAI deal, a Mistral deal, an AWS collaboration to place Cerebras chips in AWS data centers, and work with Cognition. In his framing, Cerebras is not merely another chip company. It is a levered bet that agentic AI and enterprise inference workloads need faster serving hardware, not only training GPUs.
The unresolved part is contract quality. Calacanis focused on the OpenAI commitment. The headline number was discussed as roughly $10 billion over several years, but he asked what the contract actually requires: guaranteed purchase, optional capacity, deferrable obligation, or something that stretches if the buyer’s revenue does not arrive on schedule. That question matters across the infrastructure stack. If AI labs make enormous commitments to chip vendors, data-center operators, and cloud providers, the legal form of those commitments determines whether the revenue is bankable or only aspirational. Wilhelm and Calacanis treated those terms as uncertain, not settled.
The same article also introduced a counterweight from AI21’s Ori Goshen: even if inference demand explodes, enterprise demand may not map cleanly to one model provider or one chip architecture. Goshen described AI21’s Maestro as an orchestration layer that learns the cost, latency, and accuracy behavior of different models, tools, prompts, and inference strategies. Its purpose is not to choose one model once. It is to route each task to the right combination of models and techniques as the portfolio changes.
That point complicates the hardware story without negating it. If enterprise AI is moving from experimentation to cost discipline, customers may increasingly ask not just “Which model is best?” but “Which model, tool, retrieval method, and inference strategy solves this workflow at the right price and latency?” In that world, some demand still flows to fast inference infrastructure. But the enterprise customer may be buying an optimization layer as much as raw model output.
| Question | Cerebras framing | Enterprise orchestration framing |
|---|---|---|
| What is scarce? | Fast inference capacity for AI labs and agentic products | Reliable routing across models, tools, and inference strategies |
| What validates the bet? | Large contracts, cloud deployments, and persistent capacity shortage | Measurable cost, latency, and accuracy gains inside workflows |
| What is the risk? | Revenue multiples assume rapid growth and durable demand | Demand may fragment across model portfolios rather than crown one provider |
| What must be proven? | That commitments become revenue on expected timelines | That orchestration captures value rather than becoming a feature |
The useful tension is not whether Cerebras addresses a real bottleneck. The source material makes clear why fast inference is a real bottleneck. The tension is whether the valuation has already capitalized too much of the future, and whether AI-lab commitments will convert into durable revenue at the speed public investors are being asked to assume.


Compute demand is becoming a power, construction, and policy problem
Once the bottleneck moves from model training to live inference capacity, the stack below the chip becomes strategic. The TBPN discussion made that visible through Giga Energy, whose path into AI data centers came from a different infrastructure market: Bitcoin mining on stranded and flared natural gas.
Matt Lohstroh described Giga as a company that learned to build modular data-center infrastructure because Bitcoin sites needed fast, rugged, power-adjacent deployment. It began with a 50-kilowatt modular data center in Southeast Texas connected to a natural-gas generator at the wellhead. Over time, Giga shifted from mining to selling the “boxes” and electrical infrastructure. It sold roughly 1.2 gigawatts of modular data centers over four years, then moved into broader electrical distribution, transformers, switchgear, and commercial customers.
AI pulled the company into a larger version of the same problem. Lohstroh said Giga now focuses on getting powered shells online quickly. Its value proposition stops at the rack level: the chips still come from elsewhere, but they need a ready physical environment. He said Giga can bring 50 to 100 megawatts of IT capacity online in nine months by building and commissioning more in the factory rather than in the field. In Bitcoin, he said, sites could go from bare dirt to energized racks in roughly 60 days. In AI, modular prefabrication was said to reduce onsite labor needs by about 95%.
This is the “powered shell” problem. A company can have chips on order and still not have a place with sufficient electricity, cooling, transformers, fiber, permitting, and local acceptance to run them. The segment connected that to the concern that chips may arrive before the physical shells are ready to use. In that framing, the bottleneck is no longer just Nvidia allocation. It is construction sequence, electrical equipment, interconnection, and the ability to win permission to build.
The local politics are not incidental. Lohstroh described town halls where companies have to explain water use, noise, project appearance, and electricity pricing. Noise can comply with a local threshold and still become intolerable to residents as a low hum. Water, heat, and power demand become proxies for a broader question: why should a community accept the costs of infrastructure whose benefits may accrue to distant AI companies?
The TBPN segment also showed how quickly the debate can become distorted. A discussed Utah data-center controversy included claims about gigawatts of demand and “atomic bombs” of thermal load, followed by counterclaims that the heat comparison was misleading. The hosts treated the argument as evidence that data-center politics will be fought with strange metrics and competing narratives, not only with engineering documents.
- Early GigaThe company builds modular Bitcoin-mining sites near stranded gas and learns to sell the infrastructure.
- Bitcoin drawdownSelling data-center boxes and electrical equipment becomes more attractive than mining directly.
- 2024Giga expands into renewables, transformers, switchgear, and commercial electrical distribution.
- AI demand surgeLarge AI data-center requests pull Giga toward powered-shell deployment for inference capacity.
The broader implication is that AI infrastructure has become a policy and community problem. If municipalities can slow or block capacity, and if national competitiveness arguments intensify, deployment may become federalized or politicized. Lohstroh said random municipalities blocking AI inference from coming online is not practical for what the country is trying to build. That is a claim from an infrastructure builder, not an adjudicated policy conclusion. But it shows where the pressure is moving: the right to build has joined the AI supply chain.


Venture’s bottleneck map has changed too
Ben Horowitz’s Stanford lecture supplied the strategy layer. His broader claim was that venture capital is a systems business whose constraints keep moving. In 2009, he said Andreessen Horowitz was built around a different diagnosis of the venture bottleneck: the industry was organized to place capital into a small number of breakout companies, while entrepreneurs needed a better product than money alone. The firm responded by building a network of relationships, a briefing-center model, centralized control, and smaller investment groups.
The AI-era update is that the constraints are moving again. Horowitz said that for most of his career, throwing money at a software problem did not work. A competitor with a two-year lead could not be caught by hiring a thousand engineers, because software work did not parallelize cleanly and communication overhead would dominate. In AI, he argued, capital can matter more directly. GPUs, data, power, and compute access can change what a company is able to do.
That view aligns with the Cerebras and data-center material, but from the investor’s side. Venture firms are no longer only funding software teams that need hiring help, enterprise introductions, and go-to-market support. They are funding a systems race in which the binding constraint may be electricity, GPU access, export controls, data-center permitting, or customer workflow integration.
Horowitz’s SaaS-apocalypse comments were more nuanced than a simple “software is dead” line. He accepted that code and UI alone are weaker moats in an AI world. But he argued many software companies are defended by distribution, supply-chain relationships, workflow integration, domain-specific buyer channels, and relationships that an AI model does not automatically recreate. His example was Navan: a corporate travel platform depends on airline and hotel supply relationships, internal HR integrations, and a channel to travel managers. In his view, a frontier lab could generate software for that market, but it would not necessarily prioritize building the supplier network and customer channel.
This is the same bottleneck question in investor language. If models can write code, the question becomes where the non-code constraint sits. It may be distribution. It may be trust. It may be compliance. It may be a supply chain. It may be proprietary data or workflow position. The answer differs by market.
Policy also enters the operating model. Horowitz argued that GPU access, AI policy, crypto policy, energy policy, and data-center regulation are now part of the environment venture firms must influence. His characterization of specific Biden administration policy was his own account, not independently established in the article, but the strategic point was clear: when compute and power shape who can build, Washington is not a distant regulator. It becomes a bottleneck layer.
| Older software-era constraint | AI-era constraint Horowitz emphasized | Why it changes venture |
|---|---|---|
| Software engineering talent | Compute, GPUs, data, and capital | Money can matter more directly when it buys scarce infrastructure |
| Code and UI as moats | Distribution, workflow, supply chains, and buyer channels | Defensibility shifts toward embedded market position |
| Founder support and recruiting | Power, policy, and physical infrastructure | Venture support expands beyond classic startup services |
| Public-market readiness later | Large private companies needing public-company capabilities earlier | Private companies can scale before public markets impose discipline |
His conclusion was not that every AI company should become an infrastructure company. It was that every startup and investor now has to identify which constraint actually matters. If the constraint is compute, capital helps. If it is workflow integration, a model demo is insufficient. If it is policy, technical strength alone may not be enough. If it is culture, the company may fail even with money and talent.


The deployment bottleneck moves inside the workplace
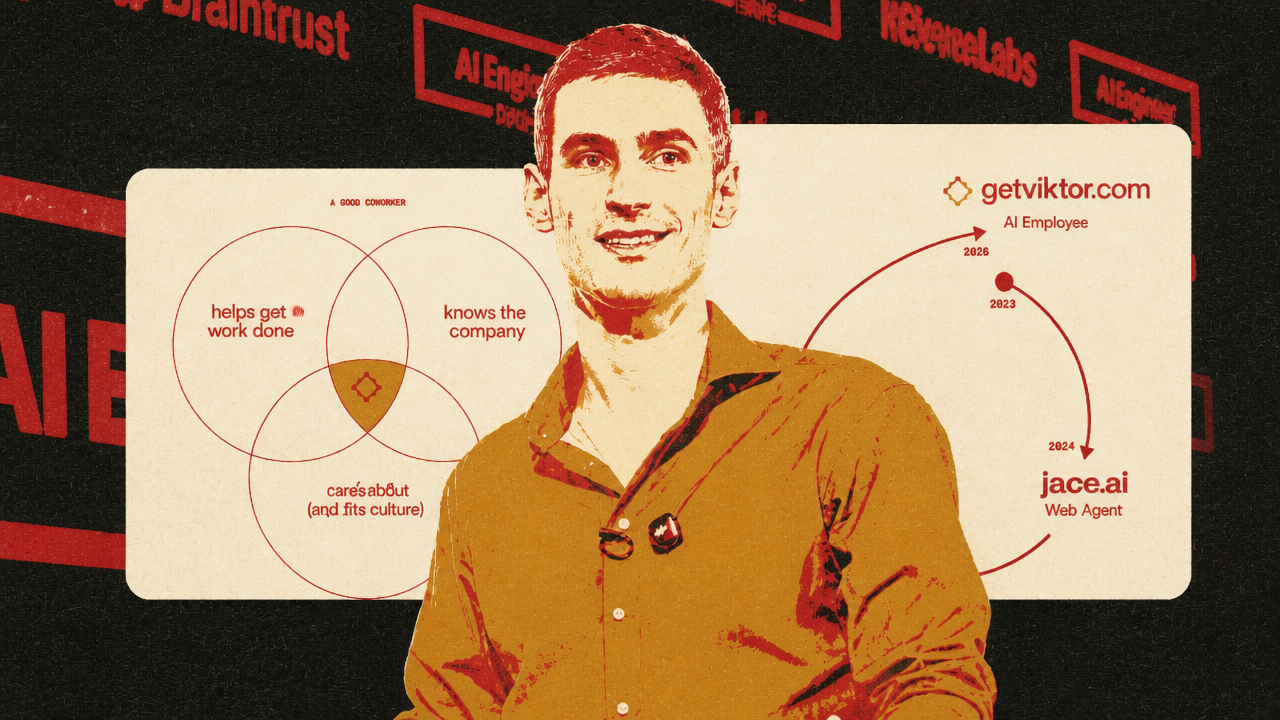
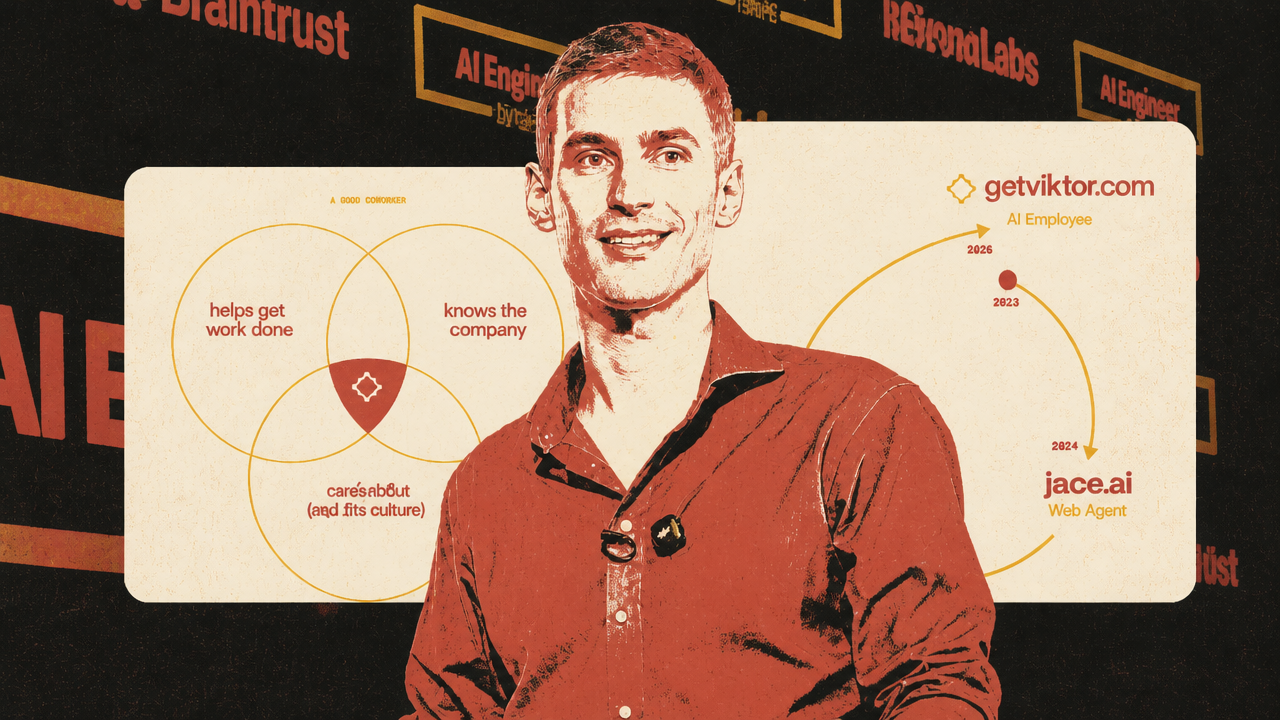
The product-layer version of the same shift appeared in Fryderyk Wiatrowski’s discussion of Viktor, a Slack-native “AI employee.” His central point was that a company-level agent is not a personal assistant with more seats. It is a different product category because the value comes from shared context and shared integrations, and those features create new risks.
Viktor lives in Slack rather than a separate web app. Wiatrowski’s premise is that a coworker should be reachable where work already happens: channels, DMs, threads, replies, reactions, edits, and deleted messages. That lets the agent participate in the communication layer instead of waiting for a user to open a new interface. It also changes how latency feels. If a web app takes 10 minutes to answer, the user experiences delay. If a Slack coworker returns a deliverable 10 minutes after being asked, the same elapsed time can feel fast.
But Slack is messy in ways a controlled app is not. A user may ask something in a thread, continue later in a DM, edit the instruction, delete part of the conversation, or react with an emoji that changes the implied state of the task. A human coworker can often infer what changed. An agent has to turn that fragmented stream into a coherent task history.
Memory and permissions are the deeper bottleneck. A personal assistant can keep one user’s context. A company agent serves many people, teams, channels, and hierarchies. Wiatrowski described a case where a team admin connected a personal Gmail account in a team context, after which other team members asked Viktor about that person’s emails. The resulting complaint was framed as data leakage, but Wiatrowski’s interpretation was that the integration had been connected with the wrong sharing expectation. The product response was integration scoping: some connections can be personal rather than shared across the team.
integration scoping is not a minor settings problem. It is the product version of organizational trust. A useful company agent needs enough context to help across functions. It must also avoid moving Growth-channel context into Engineering, Executive-channel context into Support, or private DM context into a public answer. The more valuable the shared memory, the more dangerous the mis-scope.
Proactivity has the same dual nature. Wiatrowski described Viktor intervening in a growth discussion by checking analytics and pointing out that an apparent A/B test result was not statistically significant. That is the upside of an agent inside the workflow: it can act at the moment a decision is forming. But if a newly installed agent starts DMing people and commenting across the workspace immediately, it can feel like surveillance. The article’s principle was that proactivity has to be earned with a small group before it expands.
Tone also becomes part of deployment. Wiatrowski said Viktor’s users reacted strongly when the team tested GPT-4o as a replacement for Opus. Even where tool calling and code generation were strong, users preferred the Opus-based personality and noticed the difference. In a Slack-native agent, model choice is not only about benchmark performance or cost. The agent is socially evaluated because it appears as a coworker.
This connects back to AI21’s orchestration argument from the Cerebras section, but at a different layer. AI21 routes across models, tools, prompts, and inference strategies to optimize cost, latency, and quality. A Viktor-like product has to route across people, permissions, conversations, and integrations to optimize usefulness and trust. Both are deployment problems after capability.
Real gains are powering unproven narratives
The day’s caution came from Alex Kantrowitz and Ranjan Roy: real AI progress is being used to support larger stories that are not yet fully proven. Their discussion was not skeptical in the sense of denying progress. It was skeptical of the extrapolations built on top of progress.
Anthropic’s SpaceX compute deal was their clearest example. The agreement was described as giving Anthropic 300 megawatts of new computing capacity, using more than 220,000 Nvidia GPUs, at SpaceX’s Colossus 1 data center. Anthropic also tied the announcement to immediate product changes: higher Claude Code rate limits, removal of certain peak-hours reductions, and higher Claude Opus API limits. Kantrowitz read that as real capacity relief for a company whose visible constraint has been serving demand.
Roy’s caution was that major AI infrastructure announcements are also “market theater.” By that he meant they support valuation narratives, IPO preparation, financing stories, and customer confidence. He did not argue the capacity was fake. He argued that real operational need can coexist with incentives to make the compute shortage sound permanent and exponential.
The same disagreement appeared around demand. Kantrowitz cited Anthropic claims that the company had planned for roughly 10x growth and had reached a rate that could imply 80x. His point was that demand that large cannot all be dismissed as waste. Roy asked whether that growth reflects a durable curve or a period of weak cost discipline, heavy experimentation, and “token maxing” inside enterprises. If teams are spending on agentic AI because budgets are loose and the technology is new, the next phase may include more scrutiny over return on token spend.
Their Mythos discussion followed the same pattern. Mozilla reportedly saw a sharp rise in Firefox security bug fixes after using Anthropic’s security system, including high-severity bugs and older dormant vulnerabilities. Kantrowitz treated that as meaningful evidence that AI systems can improve vulnerability discovery. Roy questioned whether it proved a magical model leap. The distinction, borrowed from Ethan Mollick’s framing, was that Mythos may be overhyped for insiders if it is presented as a step-change in model ability, while still underappreciated by outsiders if they assume it cannot really find zero-days.
Layoffs were the labor version of the same ambiguity. Coinbase and Block were discussed as companies explaining cuts partly through AI. Roy’s answer was “both”: companies may be using AI as a cleaner story for cost-cutting, while also preparing for a workplace where AI changes the size and shape of teams. Kantrowitz raised a harder counterpoint from a Meta engineer’s argument summarized by The Pragmatic Engineer: if AI were already delivering organizational productivity, companies might keep people and produce more. If they are cutting workers while increasing AI spend, the cuts may reflect the fact that the payoff has not yet arrived at the organizational level.
| Domain | What looks real | What remains contested |
|---|---|---|
| Compute | Anthropic has visible capacity constraints and SpaceX capacity could ease them | Whether current demand growth justifies permanent exponential buildout assumptions |
| Security | AI systems may be finding useful vulnerabilities in real codebases | Whether this proves a new model regime rather than better workflow application |
| Labor | AI is changing how some teams work, especially in coding | Whether layoffs reflect realized productivity, cost pressure, or preparation for future productivity |
| Financing | Infrastructure commitments are large and operationally meaningful | Whether announcements are also being used to support IPO and valuation narratives |
That closing caution fits the rest of the Brief. The bottlenecks are real: KV cache movement, inference speed, powered shells, electricity, policy, enterprise routing, memory, permissions, and workplace trust. The spending is real too. So are some product gains. What remains under test is the translation from bottleneck to valuation, from capacity to durable demand, from demo to organizational productivity, and from individual tool gains to labor-market outcomes.

