Applied AI Moves From Model Calls To Operating Loops
Today’s sources frame applied AI less as a one-shot integration and more as a discipline of owning workflows, preserving state, managing context, and tracing behavior. From Long Lake’s take-private thesis for Amex GBT to Trigger.dev, Arize, and Granola’s production lessons, the emphasis is on the systems and feedback loops around the model.
The end of one-shot AI
Applied AI is starting to look less like a software integration problem and more like an operating model. The day’s sources come from different levels of the stack — a private-equity buyer of services businesses, an agent infrastructure company, an AI observability team, and a meeting-notes product company — but they are all pushing against the same shallow assumption: that deployment mostly means putting a model call into an existing process.
Long Lake Management’s announced $6.3 billion take-private of American Express Global Business Travel is the broadest version of the argument. In Elad Gil’s framing, the deal may be an “AI take-private”: not a startup adding a feature, but a buyer taking control of a century-old services company and trying to change the operating economics with AI. Alexander Taubman, Long Lake’s co-founder and CEO, presents the firm’s model as buying trusted services businesses, embedding engineers and a horizontal AI platform called Nexus into daily work, and using productivity gains to improve growth, customer service, and employee retention rather than simply cutting headcount.
That is the useful starting point because it moves the AI discussion out of the demo frame. Long Lake’s thesis, as Taubman describes it, is not that services companies need a thin software layer. It is that AI transformation works differently when the owner controls the workflow, the customer relationship, the employee tools, the data cleanup, and the change management. Nexus sits between models on one side and company data sources, skills, and workflows on the other. Taubman said roughly 80% of Long Lake’s infrastructure is shared across verticals, while the rest is deployment: mapping how work is actually done, integrating systems, and building around the business’s pain points.
The same idea reappears in the technical articles, only at smaller scales. Trigger.dev’s Eric Allam argues that durable agents are not just transactions that can be replayed; they are sessions that accumulate state. Arize’s Sally-Ann DeLucia argues that context management is not a matter of making prompts bigger; it is an operating discipline for deciding what the model sees and what survives elsewhere. Granola’s Mehedi Hassan argues that product teams cannot “one-shot” production AI features; they need traces, testing loops, and ways for non-engineers to inspect behavior.
The common thread is not a single architecture. It is a move from asking what a model can do once to asking what systems, organizations, and feedback loops can keep doing reliably. In these accounts, the hard work sits around the model: owning the workflow, preserving state, selecting context, observing behavior, and changing the system when real users expose failure modes.
Long Lake makes that claim at boardroom scale. The wager behind the Amex GBT deal is that AI changes services businesses when productivity gain becomes operating leverage: employees have more capacity, customer experience improves, growth becomes less tied to proportional hiring, and the company can compound those advantages over time. Taubman’s claim is explicitly positive-sum: more productive people should mean wanting more of them, not fewer. The Brief does not need to endorse that outcome to see why it matters. It is the same operational question the software sources face in code: once AI is embedded in real work, what has to be owned, measured, remembered, and changed for the system to keep improving?


Owning the workflow changes the economics
Long Lake’s argument turns on ownership as a feedback loop. Gil asked why the firm buys companies instead of selling AI software to them. Taubman’s answer was alignment: a vendor can help, but it does not have the same relationship to the business outcome as an owner that controls the workflow and customer relationship.
That distinction matters because the hardest deployment work is not model selection. Taubman described Long Lake engineers treating field employees as their customers, sitting with teams across architecture, HOA management, HR services, specialty tax, and other businesses to observe pain points and build tools inside Nexus. Gil connected this to one of the central blockers in enterprise AI adoption: changing processes and organizational design. A software vendor can influence those changes indirectly. An owner can impose, fund, and iterate through them.
The economic claim follows from that operating claim. Taubman said most services businesses historically scale by hiring roughly in proportion to revenue. If 20% growth requires 20% more people, growth is constrained by recruiting, training, management capacity, and marginal labor cost. In his telling, AI changes the psychology of growth if existing teams can become 30% or 40% more efficient and serve more customers with better response times and fewer errors.
Long Lake’s example from homeowners association management is illustrative, not conclusive. Taubman said businesses the firm invested in were typically growing 0% to 5% annually in volume, while Long Lake’s HOA company is now growing organically at more than 20% a year. He attributed that to extra employee capacity, better customer acquisition economics, and better products and services.
| Layer | What the source says has to change | Why it matters |
|---|---|---|
| Services business | Own workflows, employee tools, customer relationships, and change management | Productivity gains can be directed toward growth, service quality, retention, or cost reduction |
| Agent infrastructure | Separate durable context from durable execution state | Long-running agents accumulate state that cannot be treated as a short replayable transaction |
| Agent quality | Select, truncate, store, and retrieve context deliberately | The model-visible window determines whether follow-ups and evidence-based reasoning survive |
| Product organization | Trace behavior and test variants across teams | AI features need observable, adaptable feedback loops after they reach users |
The claim also explains why Long Lake’s model is not just financial engineering with AI language attached, at least as Taubman presents it. He rejects the quick-flip private equity pattern and argues for long holding periods, permanent capital, and compounding operating advantage. The seller pitch is similarly operational: Long Lake offers not only capital, but applied AI engineers who may live in the office for extended periods, work with employees, and build against real workflow constraints.
Amex GBT gives that thesis a larger stage. Gil called it the world’s largest corporate travel platform and a 110-year-old business; Taubman described a 111-year-old company that began in 1915 and later acquired Carlson Wagonlit, whose predecessor dated to 1876. For Taubman, the history is part of the attraction: trusted services franchises have survived prior technology transitions, and Long Lake says it wants to double down on Amex GBT’s existing AI transformation strategy. The phrase he used for the target customer experience was “your travel counselor with AI superpowers”: faster response times, faster disruption resolution, and better outcomes.
That formulation is important because it keeps the worker inside the workflow. Nexus is not described as replacing the service organization from outside. It is meant to increase the capacity of the people already serving customers. Whether that produces the positive-sum outcome Taubman predicts is an open strategic and empirical question. But the operating premise is clear: AI transformation is not just installing software; it is redesigning how the work is done and who gets to change it.
Durable agents need durable state
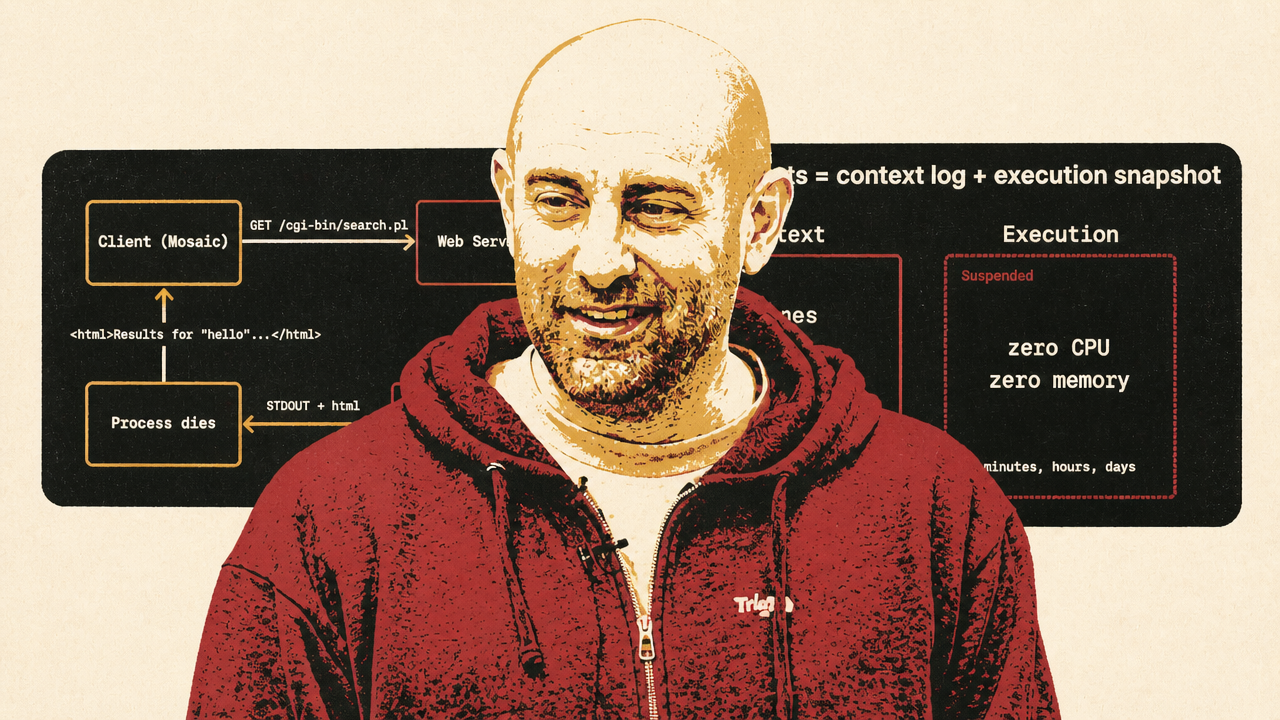
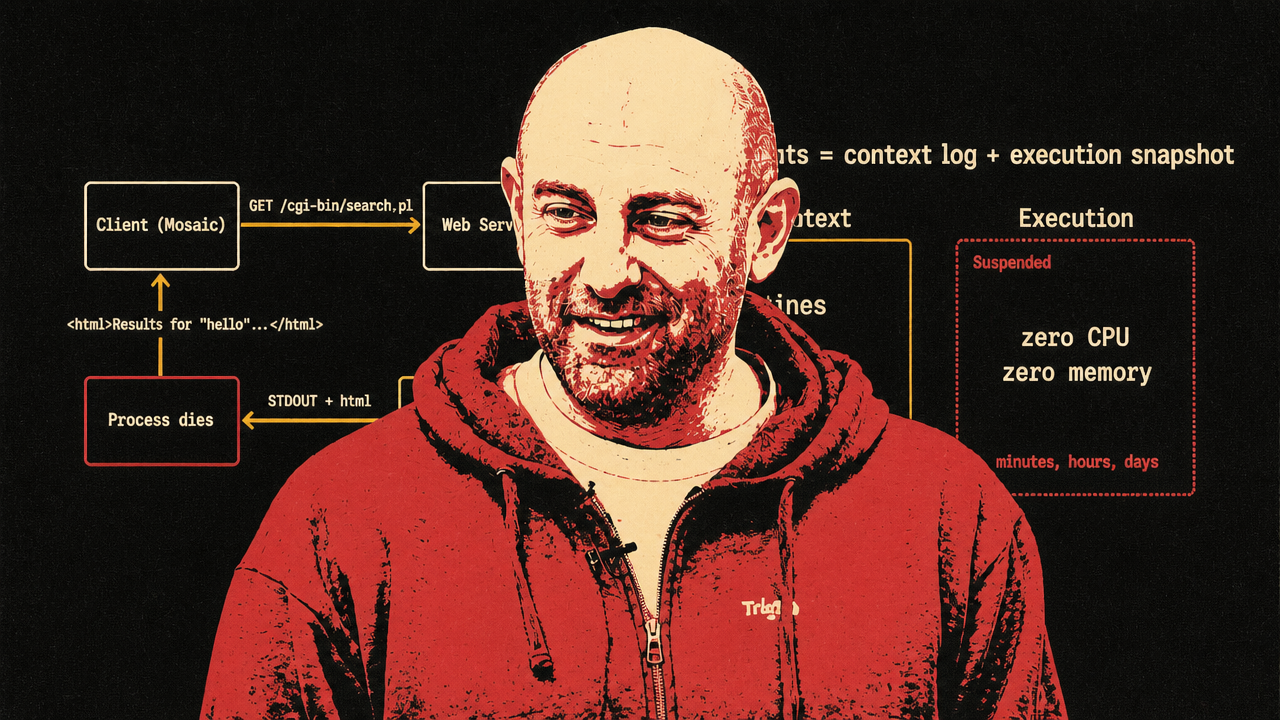
Trigger.dev’s article supplies the technical vocabulary for the same shift. Allam separates agent durability into two problems: context durability and execution durability. The context — system messages, user messages, assistant responses, tool calls, tool results, and LLM turns — fits naturally as an append-only log. The execution environment — files, memory, subprocesses, cloned repositories, installed packages, local datasets, dev servers, open handles — may need to be snapshotted at the machine level and restored later.
This is a sharper distinction than “make the job retryable.” Allam does not dismiss replay-based durable execution. He presents it as the right solution for transaction-like backend work: if an order-processing function charges a card and then fails while sending a receipt, replay can avoid charging the card twice by recording completed side-effecting steps. That model made sense for workflows that start, run through a defined sequence, wait when needed, and finish.
Agents stretch the model because the unit of work increasingly looks like a session. A user may leave and return. The agent may wait minutes, hours, or days between turns. It may have cloned a repo, installed packages, started a server, or loaded data into memory. Treating every LLM call, tool call, and wait as entries in one replay history means the durability mechanism grows with the whole life of the session.
Replay still has a role, in Allam’s account. But the agent workload adds state that replay was not designed to preserve. His formulation is compact: durable agents equal context log plus execution snapshot.
That split echoes Long Lake’s business-level argument. Once AI is embedded in real workflows, state accumulates. A company cannot simply rerun the transformation from the beginning every time an employee changes a process or a customer need appears. Likewise, an agent cannot always rebuild meaningful local state from a clean start without cost, brittleness, or awkward developer constraints.
Trigger.dev’s Firecracker work is presented as evidence that this is becoming operationally plausible, not just conceptually neat. The idea is to snapshot a microVM when an agent reaches a wait point, shut it down so it consumes no CPU or memory while idle, and restore it when the user returns or a retry is possible. That preserves the execution environment without keeping the machine alive through idle time.
The numbers in the article are there to support plausibility. Allam said Trigger.dev can reduce a 512 MB memory snapshot to about 14 MB compressed using seekable compression, lazy restore, and layering techniques. He also cited snapshot times slightly under a second and restores in the couple-hundred-millisecond range; in a demo of fcrun, creating a snapshot took 377 milliseconds total with a 3 millisecond pause, and a time-to-interactivity benchmark reported p50 total of 19 milliseconds and p95 total of 26 milliseconds.
The exact implementation is less important than the category shift. For decades, backend infrastructure favored stateless compute: request plus database equals response. Agents are putting pressure on that bargain. If they are expected to do long-running, meaningful work, keep local working state, and survive user pauses or infrastructure failures, then production systems need primitives for pausing, storing, restoring, and resuming the compute environment itself.
Context is now an operating discipline
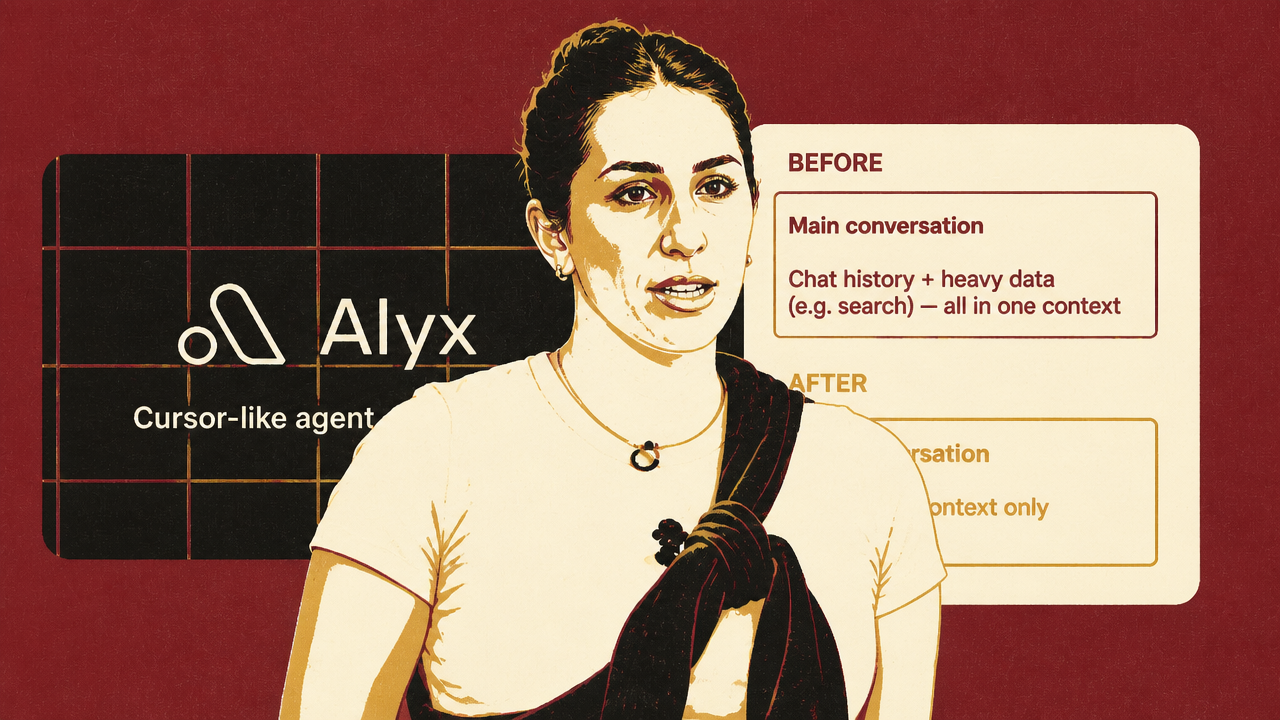
Arize’s Alyx case narrows the state problem from the machine to the model-visible window. DeLucia’s point is that context engineering has become an operating discipline because agent performance depends on choosing what the model should see, not simply increasing how much it can see.
Alyx sits on top of Arize’s observability platform and analyzes the data AI systems generate while running: traces, spans, prompts, user inputs, outputs, metadata, and conversation history. That makes context pressure unusually direct. A single trace can contain long system prompts, few-shot examples, user context, app inputs, outputs, and multiple prompts. When a user asks Alyx to find patterns across traces, the amount of relevant material expands quickly. Alyx also analyzes systems like itself, so retries and failures can add more span data to the same context problem.
DeLucia’s account is useful because it shows why “more context” is not a strategy. Arize first tried naive truncation. It kept the system under token limits, but it broke follow-up reasoning. A user could ask for common inputs, receive an answer, and then ask about “input B”; Alyx no longer had enough retained state to know what “input B” referred to. The conversation stayed within budget by discarding the relationships that made the next turn coherent.
LLM summarization was the next obvious answer, and DeLucia says it also failed as a primary compression mechanism. It shortened the context, but it gave the model too much control over what mattered. The summary might omit an identifier, intermediate result, prior conversational detail, or tool output that mattered only later.
Arize’s working pattern was head-tail truncation plus memory. Alyx preserves a small beginning and end of the context, removes the middle from the active window, stores the removed portion by ID, and lets the agent retrieve it when needed. The active context keeps setup and recency; the middle is not lost, but it is not forced into every model call. The team also removes duplicate messages and tool calls, keeps the latest result, avoids resetting the system prompt, and truncates the middle rather than discarding the end.
| State type | Where the sources place it | Production risk if mishandled |
|---|---|---|
| Machine state | Trigger.dev’s execution snapshots | The agent loses files, subprocesses, memory, servers, or local working state across waits and failures |
| Conversation and tool history | Trigger.dev’s append-only context log; Arize’s active context and memory store | The agent cannot resume coherently or audit what happened |
| Retrieved evidence | Arize’s ID-addressable memory and sub-agents | The model either forgets key evidence or bloats the prompt with irrelevant material |
| Product behavior | Granola’s internal traces and preview workflows | Teams cannot tell why an answer failed or test whether a change improves the user experience |
This is where the Trigger.dev and Arize pieces complement rather than duplicate each other. Trigger.dev is about durable execution state and context logs. Arize is about context selection and retrieval quality inside the agent’s reasoning loop. Both use the language of state, but they are solving different failure modes. One asks how to suspend and resume the environment. The other asks which evidence, conversation, and tool outputs should be visible to the model now, retrievable later, or moved out of the main agent entirely.
Arize’s sub-agent pattern makes that last point concrete. Search over trace data can involve hundreds of spans and multiple intermediate queries. Arize concluded that heavy search context did not belong in the user-facing conversation. The main agent now delegates bulky data work to sub-agents, receives the result back, and avoids absorbing all the intermediate context that produced it.
Long-session evals then become the testing counterpart to context design. DeLucia said users increasingly stay in one chat across pages and workflows, pushing conversations beyond the short interactions where context strategies can appear healthy. Arize’s method is to load 10 turns and test the 11th, so bugs that previously appeared only after many turns become testable. That is another sign that context is no longer a prompt-writing detail. It is reliability work.

Production AI needs loops, not faith
Granola brings the same operating discipline to the product layer. Hassan’s central distinction is between getting a model to work once and making AI behavior reliable, inspectable, and adaptable in production. A generic chat interface is easy to demo. The problems appear when real users ask for to-dos, follow-up emails, coaching, meeting retrieval, or role-specific summaries that match how they actually work.
Granola’s examples are deliberately ordinary. Web search looks like a one-line provider tool until it creates cost, latency, context, and provider-quality problems. Hassan said complex web-search queries can expand token usage enough to push the cost of a single chat to “like 10 pence,” which becomes material at scale. He also described an overnight provider update that degraded web-search quality, forcing Granola to switch providers because a core product behavior had changed outside its control.
Meeting summaries create a different version of the same issue. Sales, engineering, and HR users do not necessarily want the same notes. Sales may care about deal context, next steps, and objections; engineering may care about decisions, blockers, action items, or Linear tickets. A one-size-fits-all prompt does not absorb those differences by itself. Hassan described LLMs as “stubborn,” with consistent output quality taking months.
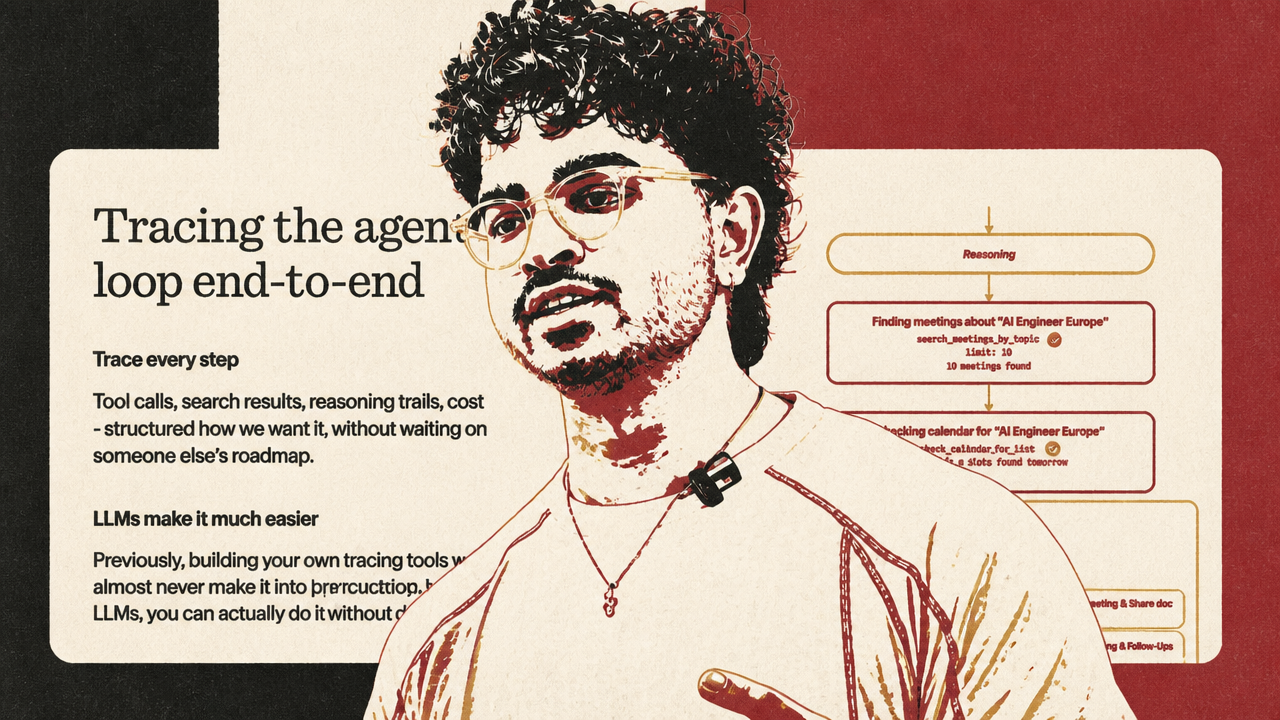
Granola’s answer was internal tracing: not just logs for engineers, but a way for product, data, customer experience, founders, and others to inspect the agent loop. The tracing UI exposes tool calls, search results, reasoning trails, and cost in a form employees can use without digging through CloudWatch. Hassan said Granola’s founder can follow the agent loop “front to back” to understand exactly what went wrong.
That is the product-organization analogue to Long Lake’s embedded engineers and Arize’s observability discipline. In all three cases, the answer is not “trust the model.” It is to make behavior visible to the people responsible for the outcome, shorten the path from failure to diagnosis, and create a way to change the system.
Granola’s frontend workflow extends the same principle beyond model traces. Because AI increases the number of product variants teams want to test, the product surface itself has to be easier to preview. Granola’s desktop app made that hard; the Electron setup allowed only one local instance, and colleagues had to pull the repo and run the app to test changes. The team turned the renderer into a web shell so CI can deploy a preview link for each pull request. That lets people experience variants directly, collect feedback, and iterate faster.
- Business layerLong Lake argues that owning the workflow gives AI deployment a tighter loop between engineers, employees, customers, and operating results.
- Infrastructure layerTrigger.dev separates durable agents into context logs and execution snapshots so long-running sessions can resume without replaying everything.
- Agent-quality layerArize stabilizes Alyx with head-tail truncation, retrievable memory, sub-agents, and long-session evals.
- Product layerGranola builds traces and preview workflows so AI behavior can be inspected and product variants can be tested before release.
Hassan does not reject one-shotting entirely. He says LLMs make it useful to generate scaffolding and internal tools, including the tracing systems that make production AI more observable. His objection is to treating one-shot output as a substitute for product conviction. The durable work is the feedback loop: seeing what happened, understanding why it happened, testing variants, and deciding what to ship.
That closes the loop with the other sources. Long Lake’s embedded engineers are a feedback loop inside services companies. Trigger.dev’s context logs and execution snapshots are durability primitives for preserving and resuming long-running agent state. Arize’s long-session evals, retrievable memory, and sub-agents make model-visible context testable and adjustable. Granola’s traces and preview links make product behavior easier to inspect and change.