Durable Agents Need Context Logs and Execution Snapshots

Eric Allam of Trigger.dev argues that durable agents need more than the replay-based workflow model used for durable transactions. In his talk, he separates agent durability into two problems: the LLM context, which fits naturally as an append-only log, and the execution environment — files, memory, subprocesses and local state — which he says should be preserved through OS-level snapshot and restore. Allam uses Trigger.dev’s Firecracker work to make the case that long-running agents are becoming session-like workloads, not just replayable transactions.
Durable agents need two durability primitives
A durable agent cannot be treated only as a replayable transaction. Eric Allam’s core architecture is a split one: keep the LLM context in a durable append-only log, and preserve the execution environment with machine-level snapshot and restore. Replay remains useful, but if every LLM call, tool call, and wait becomes part of one ever-growing journal, a long-running agent session eventually stops looking like the workflow systems replay was built to serve.
Allam starts from a simple TypeScript agent loop: a bounded turn loop, a message history, an LLM call, tool handling, and a wait for the next user message. It is the kind of loop that “works well enough” on a developer’s machine. The production problem is what happens when that loop is expected to do “long-running, meaningful work,” survive across user turns and code versions, and recover when something fails.
The durability problem has two different kinds of state. One is context: system messages, user messages, assistant responses, tool calls, tool results, and LLM turns. That state is naturally an append-only log. The other is execution: files, memory, running processes, subprocesses, open handles, cloned repositories, installed packages, in-memory datasets, dev servers, and sandboxes. The first belongs in durable storage. The second should not be forced into a replay journal.
Replay gave us durable transactions. But an agent isn't like a transaction, it's like a session.


Replay-based durable execution is not dismissed. Allam presents it as the right answer to a real backend problem: multi-step side effects where retrying the whole function would repeat actions that must not be repeated. But agents stretch that model past the shape it was designed for. Their logs grow with every LLM turn and tool call. Their sessions can last minutes, hours, days, or as long as the user keeps returning. Their useful state increasingly lives inside the compute layer itself.
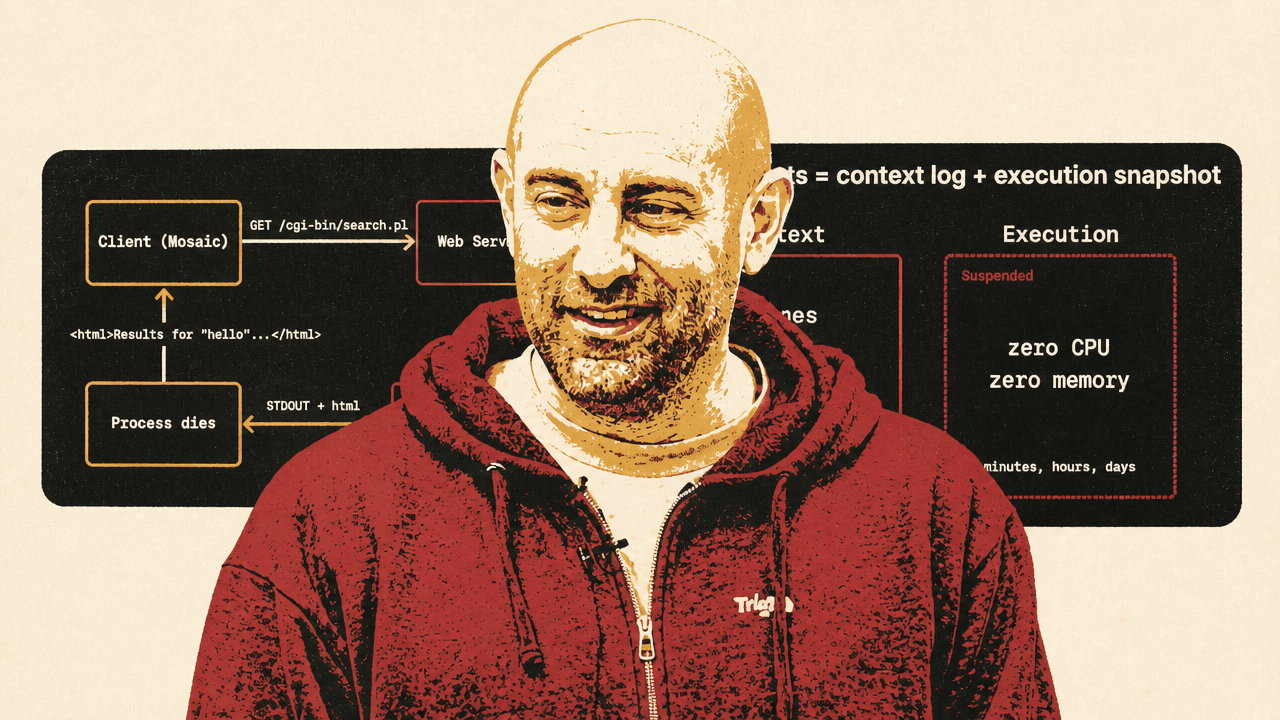
The durable-agent architecture he proposes is therefore: “Durable agents = context log + execution snapshot.”
Replay solved transactions by constraining how code runs
Replay exists because stateless compute made ordinary backend work easy, but made multi-step side effects dangerous to retry.
Allam’s compressed backend history starts with CGI in 1993. An HTTP request arrived, the server forked a new process, request data went in, the process wrote a response to standard output, and the process died. PHP and the LAMP stack reused the PHP process, but kept the same core assumption: a request, plus state read from the database, produced a response. The next request could do the same work again.
He summarizes the dominant pattern as “Request + DB = Response,” the shared-nothing architecture: compute is stateless, and meaningful state lives in the database. Ruby on Rails, Node.js, and serverless all follow the same general paradigm in his telling. The programming models changed, but the infrastructure bargain remained: the compute layer should be replaceable, restartable, and largely free of durable state.
Side effects complicated that bargain. Web applications began doing work outside the request-response lifecycle: sending email, charging a credit card, resizing an image. Those tasks became multi-step operations. Allam uses an order-processing function as the representative example: fetch the order, charge the card, send the receipt.
The failure mode is straightforward. If sending the receipt fails, retrying the whole function can charge the card again. Workflow and durable-execution engines address that by wrapping every effectful operation in a named step. The engine caches completed steps in an execution history. If the workflow restarts, it does not re-run the completed charge-card step; it replays past results and resumes at the failed receipt step.
This is what Allam calls the replay model. It builds durable execution on top of stateless compute. The replay journal becomes an audit trail of what happened. Resuming to a known point in execution lets the system recover from failure. It also allows a workflow to wait for an external event, such as a human action, without keeping the whole process alive.
But the model imposes structure. All side effects must be wrapped in steps. Code outside steps has to be deterministic, because it may be re-executed during replay. Versioning the replay journal gets tricky when new code is deployed against old histories. Replay works by requiring developers to write code in a shape the replay engine can safely re-run.
Agents turn replay history into an open-ended session log
Eric Allam frames the 2023 starting point this way: when LLMs first appeared in production applications, they fit neatly into the workflow era. A model call could simply be another step. Code still orchestrated the LLM.
Tool calling changed the direction of control. Once the LLM began choosing which tools to call and when, the application was no longer simply code orchestrating a model. Allam defines an AI agent as “a system that uses an LLM to decide the control flow of an application.” In that setting, replay has to journal every LLM call, every tool call, and the waits between turns. On resume, the function re-executes from the top and replays all of that history.
That can work for a short interaction. But as the agent continues, the log grows turn by turn. The system can run into fundamental limits: too many entries, entries that become too large, or a replay system limit reached by the accumulation of history. The structure that solved durable transactions becomes awkward when the unit of work is an open-ended agent session.
Allam points to a measure of how long agents can do meaningful work and says it is apparently doubling every four to seven months. He characterizes the current horizon as “a few hours,” with multiple-day meaningful runs not far away. The METR data shown in the source framed agent runtime as rising from 0.05 hours in 2023 to 32 hours in H1 2027.
| Period | Runtime shown |
|---|---|
| 2023 | 0.05 hours |
| 2024 | 0.17 hours |
| H1 2025 | 0.83 hours |
| H2 2025 | 4.8 hours |
| H1 2026 | 8.7 hours |
| H2 2026 | 16 hours |
| H1 2027 | 32 hours |
The significance of that curve is architectural. A workflow is usually a transaction-like unit: it starts, executes a defined series of steps, and ends. An agent session can remain alive as long as the user wants it to. It may wait between turns for minutes, hours, or days. It may accumulate local machine state while it works. Treating every action as a replayable step means the durability mechanism expands with the entire history of the session.
The alternative is to separate what must be replayable from what must be resumable.
The context is a log; the execution state is a machine
For Eric Allam, the context half of an agent is the first and most important durability target. It includes messages, tool calls, tool results, and LLM turns — everything that went into and came out of the LLM. It is naturally an append-only log, and it can be made durable using existing primitives: a database, object storage, a distributed file system, or newer technologies specialized for durable logs.
That context log provides durability across versions of code. The harness can be upgraded while preserving the same context. If one machine crashes, another can read the context log and continue. Append-only logs, he notes, scale well.
Execution state is different. If an agent has cloned a GitHub repository, installed packages, loaded data into memory, started a dev server, or launched a subprocess, that state is not naturally represented as a sequence of logical workflow steps. A log can record what happened in the interaction, but it is not the right primitive for preserving the filesystem, memory, processes, and open handles inside the compute layer.
The execution-side problem becomes clearest at a wait point. An agent has done work, accumulated machine state, and is now waiting for the next user message. Keeping the machine running through the wait would preserve state, but Allam says it is too expensive. Throwing the machine away and rebuilding its state from a replay log is the wrong abstraction.
The proposed primitive is snapshot and restore. When the agent reaches a wait, the system snapshots the machine, shuts it down, and saves the snapshot to disk. While suspended, it consumes “zero CPU” and “zero memory.” When the user returns, the system restores the machine and resumes execution where it left off.
That gives durability across turns without paying live compute cost during idle time. It also preserves the agent’s working state rather than forcing developers to encode that state into deterministic replay steps. Durable agents combine “context durability” and “execution durability”: a durable context log plus an execution snapshot.
The same split also shapes error recovery. If the downstream issue is external — for example, the LLM is unavailable or asks the caller to wait 15 minutes before retrying — the agent should not sit in memory. It can snapshot, suspend, and restore when retrying is possible. If the machine itself is bad because of a crash, a bug, or some other compute-layer failure, the durable context log remains the recovery path.
The broader infrastructure claim follows from that split. For decades, backend infrastructure was organized around stateless compute. Agents are forcing a move toward stateful compute, with snapshot and restore as the capability at the center.
Checkpointing is old; the target has changed
Eric Allam explicitly frames snapshot and restore as an old idea returning under new pressure. He points to IBM mainframes in 1966, where checkpoint and restore existed because long-running jobs were expensive. If a job ran for hours and failed, operators could not afford to restart from zero, so checkpoints were inserted into the code.
He then turns to CRIU, Checkpoint/Restore In Userspace, developed in 2011. CRIU could suspend and restore a process from user space. Allam describes it as injecting a process with a “parasite,” forcing the process to dump everything to memory, and then removing traces of the parasite. “It actually worked,” he says.
Trigger.dev shipped CRIU-based snapshot restore in 2024 and, according to Allam, has done millions of snapshot restores with it. Its benefits were that it was transparent to the process and compatible with container runtimes.
But the limitations mattered. CRIU checkpointed a process, not a whole machine. If the workload involved FFmpeg, headless Chrome, or other subprocess-heavy execution, “it sort of doesn’t work,” in Allam’s phrasing. It only captured open files, so filesystem state that was not open at the time of snapshot was not captured. And although container compatibility was useful, OCI container image workflows brought registries, push and pull, and slowness.
Those constraints led Trigger.dev to move to Firecracker microVMs. With Firecracker, Trigger.dev can snapshot the entire machine rather than a single process. The point is not just that more state is included; it is that the process no longer has to cooperate with the snapshot mechanism. Whatever is happening inside the VM can be paused, snapshotted, and restored so it “picked up right where it left off.”
The naive version is too expensive. If the VM has 512 megabytes of memory, the memory snapshot is 512 megabytes on disk. That creates storage and network-transfer costs, and much of the memory may not actually be in use.
Trigger.dev reduced this with seekable compression, lazy restore, and snapshot layering. Allam says they use seekable zstd so restore does not have to decompress all memory pages at once. Instead, pages are decompressed as they are needed. Combined with other layering techniques, he says they can reduce a 512 MB memory snapshot to about 14 MB compressed, with compression level functioning as a performance knob.
After that work, snapshot times are slightly under a second and restores take a couple hundred milliseconds. In Allam’s comparison, Firecracker snapshot and restore times were much smaller than the earlier CRIU timings on the same 0-to-10-second scale.
The Firecracker numbers were meant to show operational plausibility
The performance figures matter because Eric Allam is not only describing a conceptual split. He is arguing that machine-level snapshotting can be cheap and fast enough to serve as the compute substrate for durable agents.
He introduced a tool called fcrun, described as a Docker-like CLI for running containers inside Firecracker VMs and snapshotting or restoring them. It is intended as a drop-in-style replacement for the Docker command in this context, and Allam says it will be open source “very soon.”
The concrete timings were small enough to be part of the argument. Running Alpine to echo “hello” completed in 0.126 seconds. Creating a snapshot named agent took 377 milliseconds total, with a 3 millisecond pause. Forking a VM took 0.100 seconds. A time-to-interactivity benchmark over 50 runs at parallelism 6 reported a p50 total of 19 milliseconds, a p95 total of 26 milliseconds, and 15,280 startups per minute.
| Operation | Timing |
|---|---|
| Run Alpine echo command | 0.126s real time |
| Create snapshot | 377ms total, 3ms pause |
| Fork VM | 0.100s real time |
| Benchmark throughput | 15,280 startups/min |
| TTI benchmark p50 total | 19ms |
| TTI benchmark p95 total | 26ms |
For Trigger.dev, this work will power a future compute layer. The broader claim is that VM-level snapshotting makes long-lived, stateful agent sessions operationally plausible without keeping machines alive during idle periods.
Replay remains useful, but not for everything an agent becomes
The architecture Eric Allam lands on is deliberately two-part. Context durability remains a log problem: the context log records messages, tool calls, tool results, and LLM turns, and it survives code changes and machine changes. Execution durability is a machine-state problem: the filesystem, memory, processes, and open handles belong to the compute layer.
That distinction narrows replay rather than discarding it. Replay remains a fit for durable transactions and for state that can be cleanly represented as deterministic code plus recorded side effects. The claim is that durable agents add a session-like workload where the user can disappear and return, the agent can hold meaningful local state, and the infrastructure must suspend and resume that state cheaply.
In Allam’s final formulation, durable agents are “context log + execution snapshots.” That combination is meant to provide durability across code versions, across user turns, and across failures. It also marks the infrastructure shift he wants backend engineers to recognize: agents are pushing production systems away from purely stateless compute and toward stateful compute that can be paused, stored, restored, and resumed.