Production AI Features Need Feedback Loops, Not One-Shot Prompts

Mehedi Hassan, a product engineer at Granola, argues that the hard part of shipping AI features is not getting a model to work once in a demo, but making its behavior reliable and inspectable in production. Using Granola’s meeting-notes app as the case, he says web search, chat, and prompt personalization quickly expose costs, context limits, provider instability, and role-specific user expectations that a single prompt cannot absorb. Granola’s response, in his account, was to build feedback loops: internal tracing, broadly usable debugging tools, and faster ways to test product variants before shipping.
The production problem is not whether the model can answer once
Mehedi Hassan framed Granola’s AI work as a product-engineering problem rather than an LLM-engineering problem: the difficult part is not getting a feature to work once, but making it reliable, inspectable, and adaptable once real users start pushing on it.
Granola is a meeting-notes app that sits on the user’s dock rather than joining calls as a bot. It has access to system audio and microphone audio, produces real-time transcription, and generates notes after a meeting. Hassan’s demo showed the product recording a previous talk, capturing a live transcript, and letting the user write notes on top of that transcript. Those user notes are not decorative: when he wrote down “20% overlap,” the generated summary emphasized that idea in its output.
That product philosophy matters because Granola’s claim is not just “good notes.” Hassan described the intended experience as best-in-class meeting notes “no matter what role you’re in” and, just as importantly, software that “doesn’t get in your way.” The difficulty begins when that standard is applied to AI features beyond summarization.
A generic chat interface is easy to build and easy to put into a demo. Granola’s chat feature lets a user ask questions about a meeting, across meetings, or across shared context, and Granola tries to answer. In a fake version of the app, Hassan said, one could “one-shot” the chat system quickly.
The first contact with production is different. Users ask for a list of to-dos. Web search is too slow. Follow-up emails do not sound like the user. A request for coaching about meetings can retrieve meetings about a football coach. Hassan presented these not as exotic failures but as the normal consequences of shipping a generic chatbot into a specific product.
“The answer isn’t to one-shot better,” Hassan said. The rest of his argument was about what has to exist instead.
Web search looks like a tool call until it becomes a product dependency
The clean abstraction around web search is misleading, in Hassan’s account. Most LLM providers make it look like “a line of code”: add the web-search tool and expect it to work. The labs want developers to believe it is that simple, he said, but the operational reality is messier.
The first problem is cost and context. Complex queries can cause token usage to “bubble up quite a lot,” blow up the context, and push the cost of a single chat to “like 10 pence.” Hassan used millions of users as the scale example at which that becomes infeasible.
The second problem is control. During Granola’s development, Hassan said, the team used one model for a sustained period, only to see an overnight provider update degrade web-search quality. The failure was outside Granola’s control, and the team did not have a clear explanation beyond switching providers. That was not acceptable because the behavior directly affected the user experience.
The broader point was blunt: “billion-dollar companies” exist just to solve web search. That fact alone, Hassan argued, should make teams skeptical of the idea that adding web search to an LLM pipeline is a solved one-line feature.
Output quality has the same hidden complexity. Granola’s summary output may look good to one user, but the “right” summary depends on who is reading. Hassan gave the role split plainly: sales may want deal focus, next steps, and objections; engineering may want decisions, blockers, action items, or Linear tickets; HR may want something else entirely. One prompt, in his view, generally cannot serve all of those expectations.
The problem is not just writing a better generic instruction. Hassan described LLMs as “stubborn,” with consistent output quality taking months. If a product promises that it works for different roles without getting in the way, prompt design becomes only one part of the system. The rest is instrumentation and iteration.
Granola’s response was to make model behavior inspectable by the whole company
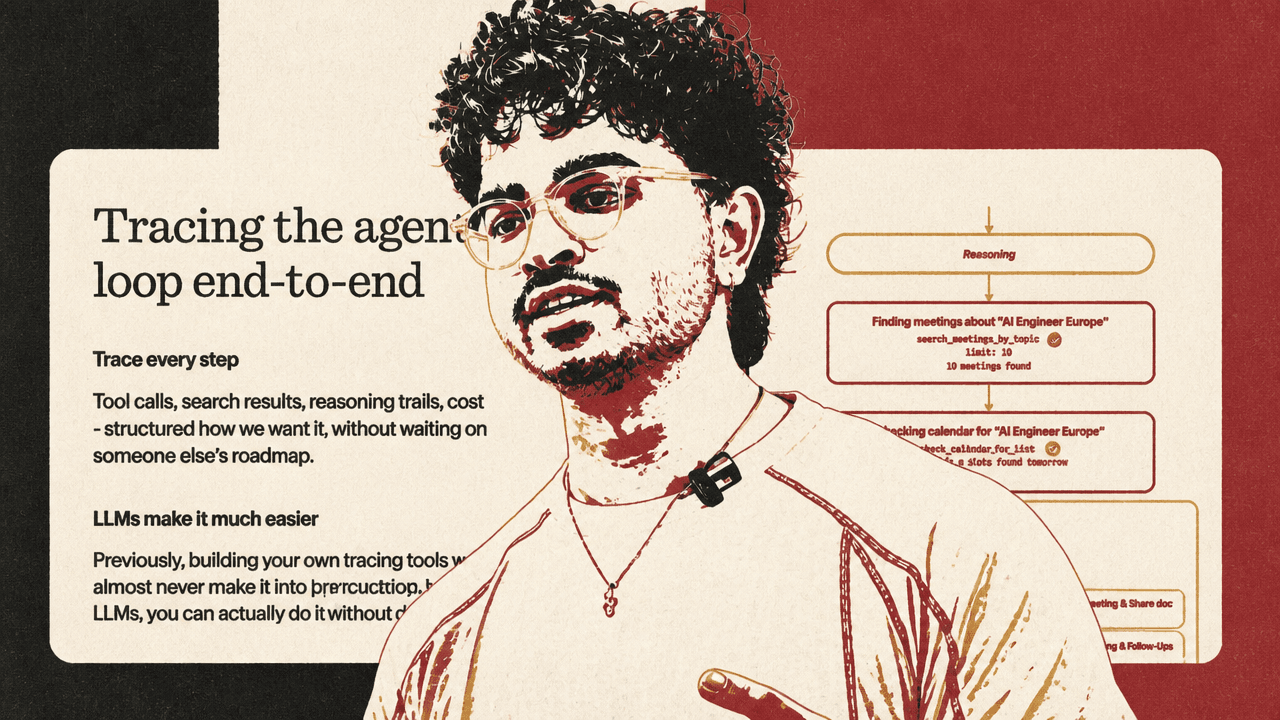
Granola’s answer to the “black box” problem was internal tracing. The company built tooling to see the agentic loop end to end: tool calls, search results, reasoning trails, and cost, structured in the way the company wanted. Hassan noted that LLMs make this kind of internal tooling easier to build; previously, a custom tracing system might never have made it onto the roadmap, or the company might have defaulted to a SaaS provider.
The important detail is not just that traces exist. It is who can use them inside Granola. Hassan said the tracing UI is built for employees internally, not only engineers: product, data, customer experience, “and everyone.” People do not need to enter CloudWatch and run complex queries to understand why something failed. Granola’s founder, he said, follows the agent loop “front to back” to understand exactly what went wrong.
The implementation was intentionally basic: a persistence layer such as a database or CloudWatch, wrappers around the AI SDK, and a frontend for exploration and querying. The slide code showed a streamed text result with handlers for reasoning-delta, text-delta, tool-call, and tool-result, each turning model activity into structured events the team could inspect. In the visual example, an agent searching for meetings about “AI Engineer Europe” exposed the call to search_calendar_by_topic, the keywords "AI Engineer Europe", the fact that 16 meetings were found, and the resulting meeting records rather than hiding the sequence behind a final answer.
Tracing turns “the output feels off” into something “specific and fixable.” That is the feedback loop Hassan cares about: not merely collecting logs, but giving Granola a way to identify edge cases, understand why the model took an action, and decide what to change.
The frontend had to become easier to test because AI creates more variants
LLM behavior is only part of the product problem. How users interact with the feature, and how the feature feels in practice, matters just as much. That becomes more acute because LLMs make it easier to generate and test variants: different features, different flows, or the same feature presented differently to different users.
Granola’s friction came from being a desktop app. Its Electron setup meant the team could only run one instance of the app at a time, and testing new features or variants required local work: pulling the repo, installing dependencies, running Electron, and then asking coworkers to do the same if they needed to try it. Hassan said Granola did not have the same luxuries as web apps.
The fix was to turn the frontend of the Electron app into a web shell. Granola’s CI now deploys a preview link whenever someone opens a pull request. People can open the link, test the change, put it in front of others, collect feedback, and iterate faster.
Hassan added a second-order benefit in Granola’s workflow: because LLMs can now self-verify using browser skills and computer use, Cursor goes and tests a PR after it is opened, then uploads a screenshot into the PR. In his account, that speeds up testing and reduces manual work.
The implementation depended on separating Electron-specific APIs from the renderer. Electron has a main process that works with system APIs and a renderer process that is essentially the frontend. Granola abstracted its IPC APIs so they fall back to web standards in the web environment. The slide showed a window.electron polyfill for the web shell, fake IPC backed by in-memory stores, and React components using an agnostic router so the same UI could work in Electron and in the web shell. Granola did similar abstraction work for React APIs such as routers, session handling, and the query layer. The result is that the renderer is agnostic to Electron and can run as a single-page web app.
That web shell let the team experience product variants rather than only inspect them in Figma. Hassan said Granola could test one feature in multiple versions and understand whether the end product “feels super good” in actual use.
One-shotting is useful for tools, not a substitute for conviction
Hassan did not reject one-shotting outright. He explicitly said LLMs make it possible to one-shot more things, and that this is useful for building internal tools like tracing systems. The distinction is between generating scaffolding and shipping a product experience.
For customer-facing AI, the durable work is the feedback loop: observing the model, exposing failures, testing variants, and shortening the path from “this feels wrong” to a concrete fix. Hassan compared the process to “playing a tennis game with the LLM.” The goal is not to hope that a black-box feature works for customers, but to build enough iteration machinery that the team has conviction before shipping.
The same pragmatism came through in the brief question about whether Granola had considered moving from Electron to Tauri. Hassan said the team had discussed and tried Tauri, but had not seen the “massive performance gains” they cared about most, so they had not shipped it.