Head-Tail Truncation and Memory Stabilized Arize’s Trace-Analyzing Agent

Sally-Ann DeLucia argues that agent performance depends on context management as an operating discipline, not on larger prompts or simple compression. Drawing on Arize’s work building Alyx, an agent that analyzes trace data from AI systems including its own, she says naive truncation broke follow-up reasoning and LLM summarization gave the model too much control over what mattered. Arize’s more durable pattern was to preserve the head and tail of context, store the middle for retrieval, test long sessions explicitly, and move heavy workloads into sub-agents.
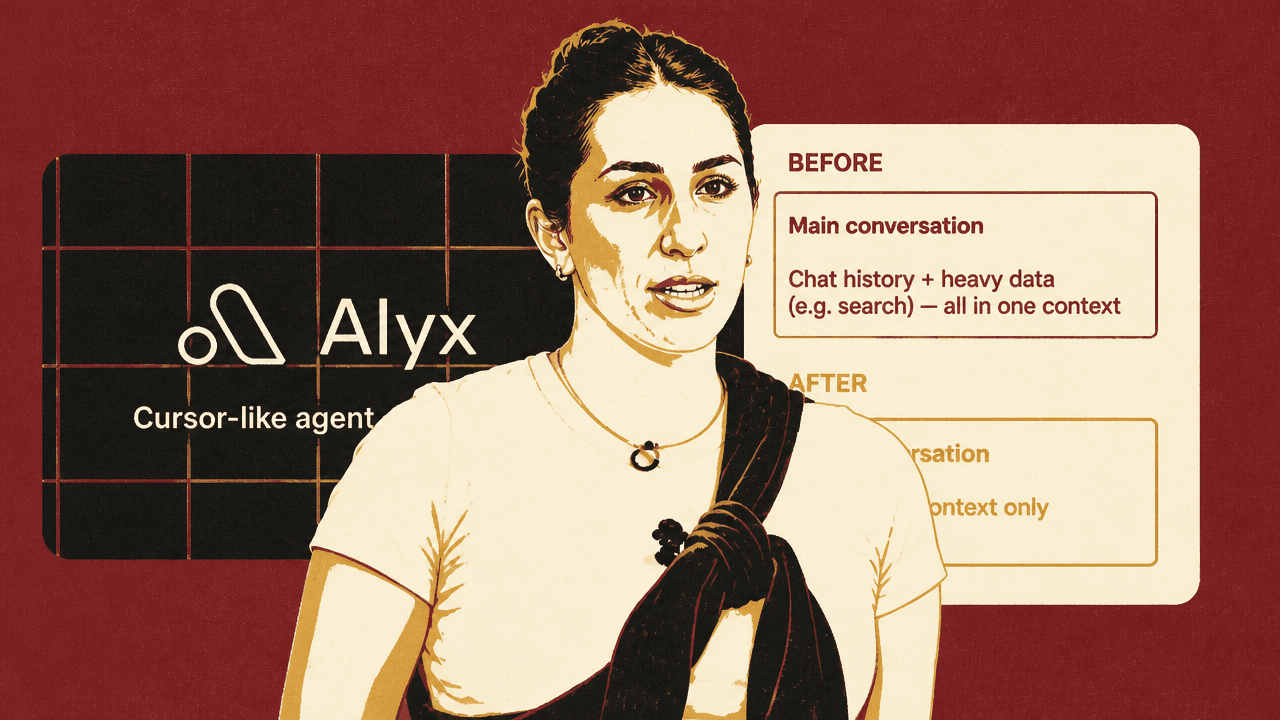
The constraint was not the prompt; it was the data the agent had to reason over
Sally-Ann DeLucia’s central claim is that context engineering has become the operating problem for agent builders because performance depends less on fitting “as much as possible” into a context window than on choosing what the model should see. In Arize’s case, that became unavoidable while building Alyx, an AI agent used to help build AI applications.
Alyx sits on top of Arize’s observability platform. It works with the data AI systems generate while running: traces, spans, prompts, user inputs, application outputs, metadata, and conversation history. One trace can already contain long system prompts, few-shot examples, user context, app inputs, app outputs, and multiple prompts. When a user asks Alyx to look for patterns across many traces, the volume multiplies.
That architecture made context management non-negotiable. Alyx was not just an agent with a chat history. It was an agent analyzing traces and spans produced by agentic applications, including its own. As DeLucia puts it, the system analyzing the data was constrained by the data.
DeLucia frames context management as a product and UX problem as much as an engineering problem. If an agent lacks the right data, it gives bad answers; if it gives bad answers, the product becomes unusable. The user does not experience a token-budget implementation detail. The user experiences an agent that forgot what was said, failed to connect a follow-up, or could not inspect the evidence needed to answer.
The shift she describes is away from prompt engineering as the main focus and toward context engineering: deciding strategically what the model sees. She cites Andrej Karpathy’s framing of “context engineering” over “prompt engineering”: too little context, or context in the wrong form, and the model lacks what it needs; too much or too irrelevant context, and costs rise while performance can fall. DeLucia’s version is more operational: the best context strategy lets an agent remember what matters and forget what does not.
Context decides what the model sees. Memory decides what survives.


Alyx exposed the failure mode sharply because Arize tried to build Alyx using Alyx. The loop was simple and destructive: Alyx would run on trace and span data; the spans would grow; the context limit would be hit; Alyx would fail; the span still contained the previous data; another run would add still more data. Each retry enlarged the very context that had caused the failure. Without a better strategy, the agent could not reliably analyze the data it was producing and consuming.
Truncation preserved the budget and destroyed the reasoning
The first strategy Arize tried was naive truncation. Given a long context blob, Alyx would keep the beginning — DeLucia describes the first 100 characters — and drop the rest. For simple cases, it appeared to work. But the success was brittle because the agent had not retained enough conversational or task state to reason across turns.
The failure showed up in follow-ups. A user might ask for the most common inputs, receive an answer, and then ask for more detail about “input B.” Alyx no longer understood what “input B” referred to. The follow-up looked like a new conversation because the information tying it to the previous answer had been removed.
Her conclusion from that attempt is direct: over-truncation breaks reasoning. It may keep the request under the token limit, but it can remove the relationships and prior references that make a conversation coherent. In an agentic workflow, especially one that involves tool calls and trace inspection, those relationships are often the task.
The next obvious option was LLM summarization as compression. Arize had a large context; an LLM could summarize it into fewer tokens; the shorter version could be passed forward. DeLucia says this sounded like the natural solution, and she was surprised it did not work.
The problem was control. Summarization handed the decision about what mattered to the model doing the summary. That made the result inconsistent and unreliable. Arize could not guarantee that the summary preserved the specific details Alyx would later need for analysis. The LLM might compress away an identifier, an intermediate result, a tool call, or a prior conversational detail that mattered only in a later step.
The narrower point from Arize’s experience is not that summarization is useless in every setting. It is that summarization was too uncontrolled as Alyx’s primary compression mechanism. It reduced length, but it also delegated importance ranking to a model in a situation where the application needed more predictable retention.
The working pattern kept the head and tail, and stored the middle for retrieval
The strategy Arize uses in Alyx today is “smart truncation plus memory.” It still truncates, but it does not simply cut everything after the beginning. Alyx keeps a small head and a small tail — DeLucia again describes 100 characters at the beginning and 100 at the end — removes the middle from the active context, and stores that removed portion in memory under an identifier. The middle is not gone; it becomes retrievable.
The active context contains the head, a truncated ID for the removed section, and the tail. Memory can retrieve the removed content by ID. Alyx also applies context hygiene: remove duplicate messages and tool calls, keep the latest result, avoid resetting the system prompt, and truncate the middle rather than discarding the end.
The design preserves setup and recency while avoiding a main context stuffed with repetitive or bulky material. Tool calls can be especially long in Alyx because the agent makes many of them. Keeping every tool call and intermediate result in the main context would bloat the conversation quickly; deleting them outright would remove evidence the agent might need. The memory store gives Alyx a path back to prior tool calls, earlier messages, or previous context without forcing all of it into every model invocation.
This is where DeLucia separates context from memory. Context is the material visible to the model on a particular step. Memory is what survives outside that immediate window and can be brought back. They are related, and in Alyx they are designed together, but they are not the same mechanism.
Arize has found this combination stable enough that DeLucia says the team had not needed to touch it for several months, though they were beginning to revisit the strategy as usage patterns changed. It worked better than naive truncation because the agent did not simply forget the middle. It worked better than free-form summarization because important removed content remained retrievable rather than being compressed according to an opaque importance judgment.
| Strategy | What Arize tried | Observed failure or result |
|---|---|---|
| Naive truncation | Keep the first 100 characters and drop the rest | Worked for simple cases, then made follow-ups look like new conversations |
| LLM summarization | Compress the full context into a shorter summary | Too inconsistent; the team had no control over what the model considered important |
| Smart truncation plus memory | Keep head and tail, store the middle by ID for retrieval | Became Alyx’s working strategy for context control |
Long sessions made context bugs appear after the agent seemed healthy
Even after smart truncation improved Alyx’s behavior, long conversations created a different testing problem. Users do not reliably restart chats. In Alyx, users tend to stay in one chat while moving across pages and workflows in the application, so sessions grow as the agent becomes more useful.
A context strategy can appear sound in short interactions and then break only after many turns, when the conversation has accumulated enough state, tool output, and references to stress the system. DeLucia describes failures emerging only when a user reported them or when she noticed in the data that Alyx had begun to forget things late in a conversation.
Arize’s response was to create long-session evals. The method she describes is simple: load 10 turns, then test the 11th. The point is to make context bugs testable. Instead of waiting for a live user to encounter a failure deep in a session, the team can simulate accumulated context and evaluate whether the next turn still works.
This matters because context management failures are often invisible at the beginning of a workflow. The problem appears when a later instruction depends on a detail from earlier in the session, a result from a prior tool call, or a reference that only makes sense inside the accumulated conversational state.
Long-session evals are not themselves a context-management strategy. In DeLucia’s framing, they are a signal for whether the strategy is working: a way to turn late, user-reported failures into something the team can test directly.
Some context should leave the main agent entirely
A major realization for Arize was that not all context belongs in the same agent. DeLucia uses search as the example. When Alyx searches over data in Arize, even a single trace stack can contain hundreds of spans. The agent may need multiple queries, large volumes of data, and step-by-step intermediate reasoning to decide what to inspect and how to interpret it.
Arize concluded that this heavy search context did not need to live in the main conversation. Previously, the main agent carried chat history, heavy data, and search context together. That meant the user-facing conversation accumulated not only what the user and agent had said, but also the large intermediate context required for data-intensive operations.
Arize’s before-and-after model was a shift from one agent carrying everything to a delegated design. Before, the main conversation held chat history and heavy search data in one context. After, the main conversation kept chat and light context only, delegated the search work to a sub-agent, and received the result back while the heavy data stayed with the sub-agent.
The revised design uses sub-agents. When a heavy task is required, the main agent delegates it. The sub-agent handles the bulky data and intermediate reasoning. Once the sub-agent has a result, the result is passed back to the main agent, and the user-facing conversation continues without absorbing all the context that produced it.
DeLucia calls this a game changer for Alyx. Arize has since rolled out many sub-agents for data-intensive operations. The pattern is straightforward: keep the main conversation small, move heavy work into specialized agents, and return only the result needed for the user interaction. The sub-agent can still use the memory store when it needs more context, but the main context does not have to carry everything.
This is also the pattern Arize keeps returning to for huge contexts that still break things. Very large prompts or inputs can still hit provider limits. Because Alyx is operating on agent data, customer system prompts, user messages, conversation histories, and application traces can themselves be the material Alyx is asked to understand. As those contexts grow, Alyx’s context problem grows with them. Arize’s current answer is to keep breaking work into pieces and let different parts handle different context loads.
The remaining gaps are long-term memory, context budgets, and better quality metrics
Arize’s current approach is working, but DeLucia is explicit that the team has not solved context management completely. Long memory remains hard. The memory Alyx uses today is not full long-term memory; it is a context-linked memory store that Alyx can use to retrieve removed content. It helps within the current context-management strategy, but it does not give Alyx durable understanding across chats.
Usage has made that gap more important. When Alyx started, DeLucia was seeing fewer than 10 turns per conversation. Now users push to 20-plus turns as they move across surfaces in the application. Longer workflows create more references and more expectation that Alyx will remember what has already been discussed.
The problem becomes sharper if a user starts a new chat. Users want to reference issues they previously discussed with Alyx, but Alyx does not automatically have that context. DeLucia says the team is in the process of adding real long-term memory and expects it to be a major improvement.
Context selection itself is also still heuristic. The current head-and-tail approach is basic: first 100, last 100, with the middle stored. Arize continues to ask whether it is keeping the right things. The team does not yet have a principled context budget or clear metrics for context quality. Evals are used to infer whether the selected context was right, but DeLucia suggests there is room for a more sophisticated approach.
She also notes that Arize looked at the Claude Code source release hoping to find a more decisive secret. What surprised the team was that Claude Code appeared to use a similar truncation and compression strategy. Her takeaway was not that Arize had found the final answer, but that even sophisticated systems seem to be working with comparable patterns rather than a solved theory of context quality.
During Q&A, an audience member asked about another lesson from the Claude Code release: the effort put into avoiding cache invalidation during context management. Arize had not gone deeply into cache strategy yet. Alyx currently saves removed context in a database with IDs. The agent has a tool that exposes the IDs, where in the conversation the content sits, how many messages are involved, and a small preview. It can use that to retrieve relevant material. DeLucia expects Arize will need a more sophisticated approach, but says the team is prioritizing long-term memory because that is where she is seeing the most user complaints.