Applied AI Moves From Answers To Controlled Execution
OpenAI, GitHub, Stripe, Barndoor, Cline, and others are describing AI systems less as answer engines and more as producers and operators of business artifacts. That shift puts the emphasis on the surrounding execution layer: hosted interfaces, sandboxes, scoped credentials, task-level permissions, eval harnesses, and correction loops.

From answers to artifacts
Applied AI’s center of gravity is moving from response generation to work-product generation. The clearest signal is not a single model claim. It is the spread of examples in which AI systems are expected to produce, modify, or operate on the artifacts that businesses already use: spreadsheets, financial models, decks, deal records, code changes, hosted apps, checkout states, tax work, and internal enterprise records.
OpenAI’s Investor Innovation Day supplied the most conservative version of that shift. Sarah Friar described moving from “asking mode” into “real doing” with Codex. The examples stayed deliberately close to financial-services work: querying deal folders in real time, getting smart on a company through ChatGPT’s Excel plugin, and asking Codex to create a spreadsheet, model, or deck. The on-screen instruction to users was not simply “ask for the answer.” It was “Phase 2: Creating An Artifact,” with the warning, “Don’t rush into asking for the artifact.” That caveat matters. OpenAI presented artifact creation as one phase in a workflow that still depends on context, sequencing, and judgment.
James Mackey gave the enterprise-adoption version of the same point. He said 2,700 employees now have an enterprise ChatGPT license and are using hundreds of internal GPTs in day-to-day operations. His claim was not that license count alone transforms the company. It was that repeated employee-built GPTs can create a flywheel when they are attached to real business problems.
Emergent makes a more expansive version of the artifact claim. Mukund Jha described the company as a platform that lets people without programming knowledge build, ship, and monetize software. Where OpenAI’s examples are embedded in familiar financial workflows, Emergent frames the shift as broader access to software creation itself. Jha said the current product reached roughly 8.5 million users, more than 10 million apps built, users in 190 countries, and more than $100 million in annualized revenue run rate about nine months after launch. Those are company claims, not independently established facts, but they are useful as a statement of ambition: the artifact is no longer only a spreadsheet or deck inside a professional workflow; it can be the app itself.
| Company or context | Artifact being emphasized | How the claim is framed |
|---|---|---|
| OpenAI financial-services event | Deal-folder queries, Excel research, spreadsheets, models, decks, internal GPTs | AI becomes useful when connected to existing business context and work surfaces. |
| Mackey’s enterprise adoption example | Hundreds of internal GPTs used in operations | Organizational value comes from repeated application to hard business problems. |
| Emergent | Shippable apps built by non-programmers | AI can move software creation beyond programmers if the system handles hosting, deployment, testing, and maintenance. |
The contrast is important. OpenAI’s investor-event examples are intentionally mundane. They do not require a story about full autonomy. They require AI to operate inside the materials and formats office work already depends on. Emergent’s story is more aggressive: AI agents do not just help produce components of professional work; they coordinate a multi-agent software-building process that Jha says includes design, testing, memory, infrastructure, deployment, and monitoring.
Both arguments point away from the older frame of AI as an answer engine. Applied AI’s frontier is becoming less about whether a model can respond plausibly and more about whether the system around it can produce a usable artifact, ship it, monitor it, and fix it when it breaks.




Chat becomes a hosted work surface
If AI systems are producing artifacts, the interface cannot remain only a transcript. GitHub’s Marlene Mhangami and Liam Hampton used VS Code and MCP apps to show a more operational pattern: an agent calls a tool, the tool returns data plus a reference to a UI resource, and the host renders an interactive app directly inside the chat context.
That sounds narrow because the demo lived in VS Code, but the product implication is broader. Tool output no longer has to be flattened into prose, JSON, or a static link. In Hampton’s demo, an MCP server profiled a Go application, returned profiling data and a linked React UI, and VS Code rendered an interactive flame graph inside Copilot chat. The user could inspect the profile duration, top functions, and summary categories without asking the model to repeatedly reinterpret raw profiler output.
The shift addresses a basic interface bottleneck. Prompting is a poor way to inspect a flame graph, configure a form, compare a dashboard, edit a diagram, or move through checkout. A user can ask for an analysis, but when the next step is filtering, drilling down, selecting, editing, or comparing, direct manipulation is often better than another turn of chat. Mhangami’s examples made that practical: Excalidraw diagrams can be rendered as editable elements, dashboards can expose filters and drill-downs, and checkout flows can keep the user inside the chat surface rather than forcing a handoff to a browser.
MCP is the connective tissue in that story, but the host is where the experience becomes a product. In the VS Code pattern, the MCP server exposes capabilities, the tool returns the data, the resource serves the bundled HTML UI, and VS Code renders the app in a sandboxed iframe. Hampton’s containment analogy was blunt: the app belongs in an iframe for the same reason a hamster belongs in a cage. A rendered component should not freely touch VS Code settings, external APIs, or other parts of the development environment.
| Layer | Role in the MCP app pattern | Why it matters |
|---|---|---|
| Tool | Returns data from the MCP server | Gives the model or host something to call. |
| Resource | Serves the bundled HTML interface | Turns output into an operable surface rather than a text result. |
| Host | Fetches and renders the UI in a sandboxed iframe | Defines the container and trust boundary. |
| Server source | Determines which MCP capabilities are available | Creates a supply-chain and governance question, not just a developer convenience. |
This is where the developer-tooling story starts to converge with enterprise governance. Once chat can host apps and agents can call tools, the question becomes less “can the model do it?” and more “what is the safe container for doing it?” Mhangami warned against installing arbitrary MCP servers from the internet. Hampton emphasized iframe containment. Those are not implementation footnotes. They are the start of the action layer’s control model.
Stripe, Barndoor, and Cline each make the same architecture point from different layers of the stack. Stripe rejects browser automation for money movement. Barndoor argues that MCP is “merely a pipe” unless a separate governance layer decides what an agent is allowed to do. Cline shows that agent performance depends heavily on the harness around the model. VS Code’s MCP apps make the interface part of that same scaffolding: not only the model, but the host, protocol, sandbox, tool/resource contract, and trust boundary.


Payments need deterministic rails
Stripe’s Steve Kaliski gave the cleanest formulation of the boundary between probabilistic planning and deterministic execution: discovery and exploration can benefit from non-determinism, but credentials, payments, and checkout require determinism. In his framing, search, recommendation, exploration, and product discovery can use the strengths of LLM behavior. Money movement cannot be treated the same way.
Kaliski’s four failure modes are a useful checklist for any high-cost agent action, not only commerce. An agent can end up in the wrong place, buy the wrong thing, authorize the wrong amount, or expose the wrong credential. Browser automation is a weak abstraction for all four. A site can look like the intended merchant but be wrong. A product page can be misread. Tax, region, shipping, discounts, currency, and fulfillment can change the total. A card number pasted into a form is too broad a credential for an autonomous actor.
Stripe’s answer is to move the money-moving parts into structured primitives. Shared Payment Tokens constrain credential use by seller, amount, time, and currency. In Kaliski’s demo, a seller attempted to charge $50 against a token limited to $25, and Stripe rejected the transaction. The point of the rejection was the architecture: the limit was enforced outside the agent’s reasoning.
The Machine Payments Protocol extends the same idea to paid tool and resource access. Kaliski framed agent tool calls as HTTP requests. If a server requires payment, it can return a structured 402 Payment Required challenge; the agent can satisfy the challenge, retry with a credential, and receive a receipt. Payment is tied to the resource request rather than improvised through a human web flow.
The Agentic Commerce Protocol applies the same logic to ecommerce checkout. Rather than asking an agent to infer line items, tax, shipping, discounts, and totals from a visual checkout page, ACP gives the agent structured checkout state. The seller remains the source of truth for the cart. The agent can update quantities, select shipping, or proceed to payment through a back-and-forth API exchange.
| Stripe primitive | Where it applies | Deterministic control |
|---|---|---|
| Shared Payment Tokens | Credential delegation | Seller-scoped, time-bound, amount-limited credentials enforced by Stripe. |
| Machine Payments Protocol | Paid tool and resource access | HTTP 402 challenge, payment fulfillment, verification, settlement, and receipt. |
| Agentic Commerce Protocol | Ecommerce checkout | Structured catalog, cart state, tax, fulfillment, totals, and payment-state negotiation. |
Stripe and VS Code are operating in different domains, but they share a direction. Both reject the idea that the future of agents is merely chat pretending to be a human using a web page. VS Code’s MCP apps put tool output into hosted, sandboxed interaction. Stripe’s protocols put payment requirements, credentials, and checkout state into structured rails. In both cases, the “agent” should not be asked to carry all safety logic inside its reasoning. The environment should encode constraints externally.
That lesson extends beyond money. The more expensive the mistake, the less appropriate it is to rely on probabilistic interpretation of a human interface. The action layer needs verifiable parties, scoped credentials, structured state, and auditable execution.


Enterprise risk moves to authorized action in the wrong context
Barndoor AI co-founder and CEO Oren Michaels gives the enterprise version of the same control problem. His central distinction is simple: a chatbot suggests action; an agent takes action. Once an AI can update Salesforce, send an email, post to Slack, create a calendar event, query Snowflake, touch QuickBooks, or write to an internal system, governance is no longer only a question of access. It becomes a question of authorized action in the wrong context.
Michaels argues that traditional identity and access management assumes a human actor. A human employee may have broad Salesforce permissions because the company relies on judgment, incentives, fear of consequences, and social accountability. The same employee may technically be able to delete opportunities, but knows that doing so would be stupid and potentially career-ending. An AI acting on that employee’s behalf does not have the same judgment or incentives. It may misunderstand a task, infer the wrong next step, or act too quickly at machine speed.
That is why Michaels says an agent should have a smaller blast radius than the human it represents. The governing unit is not just identity or application permission. It is identity plus task plus tool plus data plus action plus acceptable failure mode.
His Salesforce examples make the difference concrete. An agent that summarizes a sales call and logs it against existing contacts may be allowed to create the call log but not create new contacts, because a lookup failure could produce duplicates. A different workflow, based on a conference attendee list, may allow contact creation because that is the task’s point. The same human, the same system, and the same nominal permission produce different agent policies depending on context.
| Governance question | Traditional IAM assumption | Agent-governance problem |
|---|---|---|
| Who is acting? | A known employee with a role | An AI acting for a person, system, or task. |
| Why broad access can work | Humans bring judgment and accountability | Agents need narrower permissions because they lack that judgment. |
| Where harm appears | Unauthorized access or insider misuse | Authorized agents using authorized tools in ways inappropriate to the task. |
| How to narrow permissions | By role, system, and identity | By identity, task, data, action, tool, and acceptable failure mode. |
The “100,000 agents” phrase is best read as a scale warning, not a literal forecast to audit. Large companies may end up with many task-specific agents across Salesforce, Slack, email, calendars, documents, Snowflake, QuickBooks, and internal systems. Each may need a different policy. The administrative problem becomes impossible if every integration and every agent requires hand-authored rules.
Michaels also ties governance to performance. An MCP server can expose dozens of tools, each with instructions. A Gmail MCP might expose 40, 50, or 100 tools. If every connected tool and its “manual” are stuffed into context, the model wastes tokens, gets confused, and may pick the wrong tool. Barndoor’s Tool IQ idea is to route the model to a small, task-relevant set of capabilities rather than show it the whole warehouse.
That point connects the enterprise section back to the interface and payment stories. MCP is useful as a pipe, but the pipe does not decide whether a given action is appropriate. Stripe narrows payment blast radius through scoped tokens and structured checkout. VS Code contains rendered apps in an iframe and warns about server trust. Barndoor wants a control layer that decides which agent can use which tool for which task, with what data, under what policy.
The common pattern is narrowing outside the model. The agent may reason probabilistically, but the system should limit the tools it sees, the actions it can take, and the contexts in which those actions are valid.


Harnesses, evals, and monitors become the center of gravity
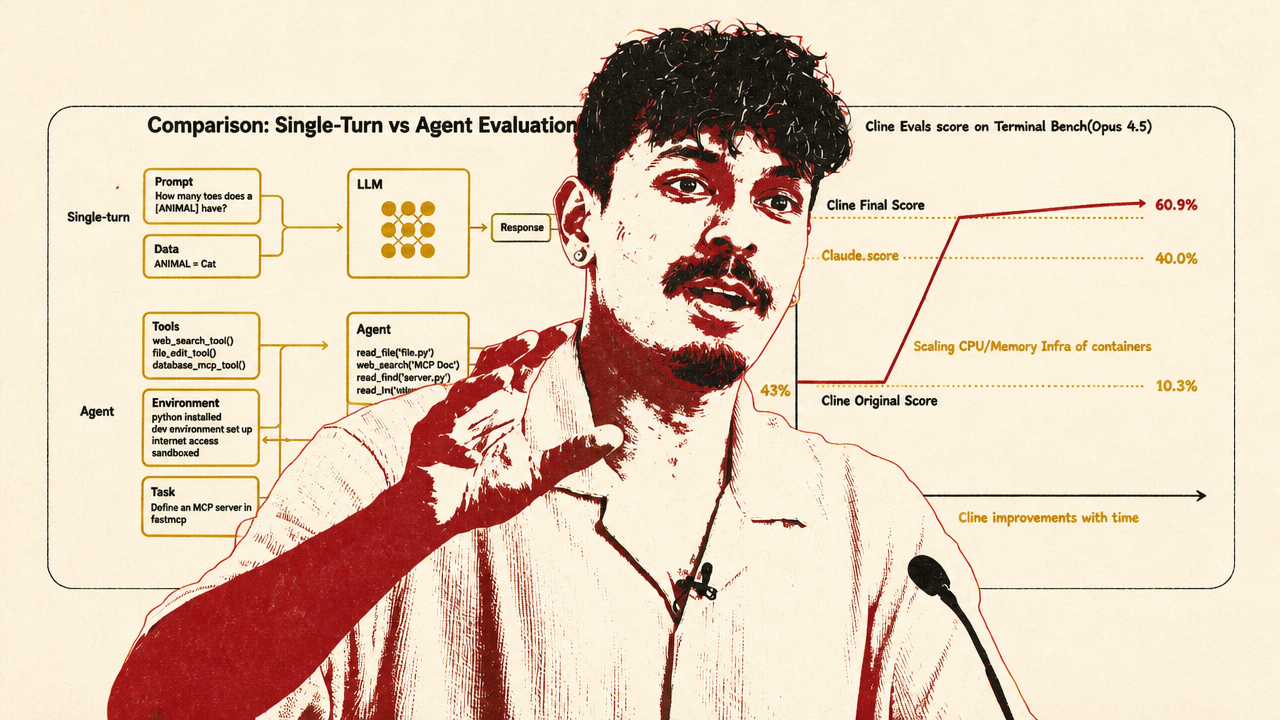
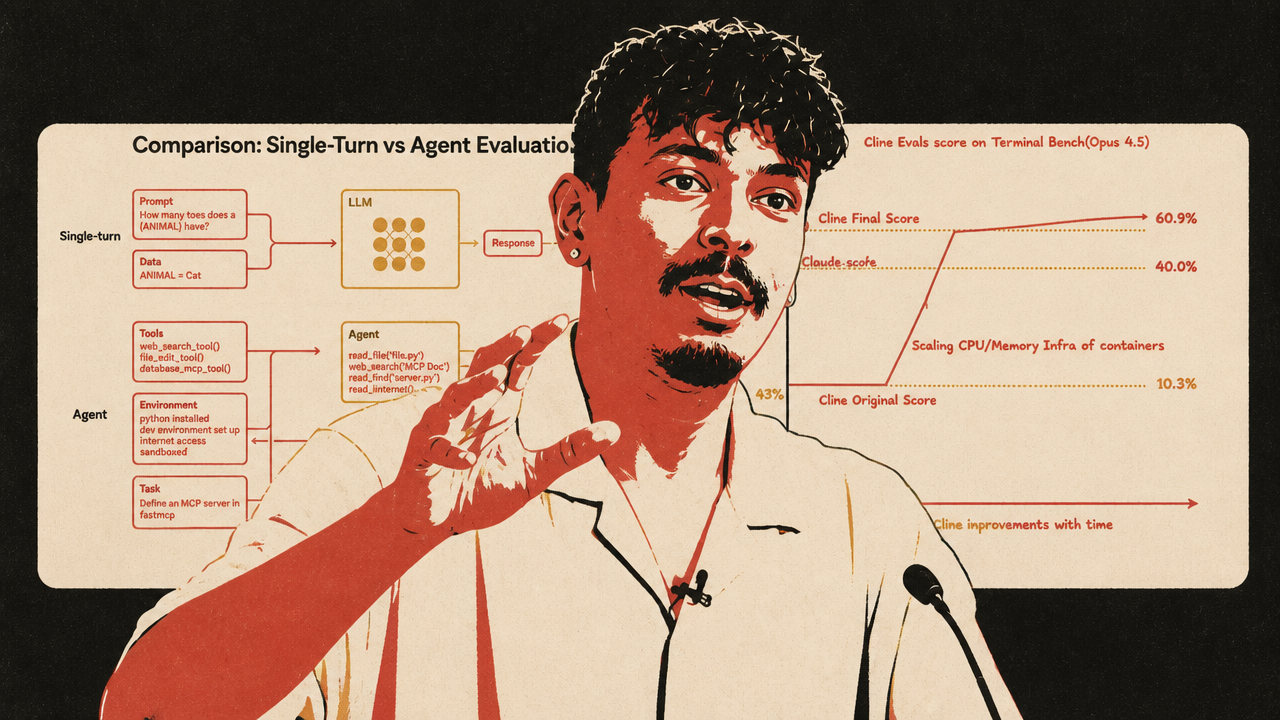
The most grounded engineering lesson came from Cline’s Ara Khan: an agent’s performance is not the model alone. It is the model plus harness plus environment plus evaluator. Cline’s reported Terminal-Bench improvement, from 43% to 57%, came from CPU and memory provisioning, longer timeouts, and model-family-specific prompting behavior, not simply from switching to a better model.
Khan’s broader claim cuts against two common mistakes. One mistake is treating public benchmark scores as truth. The other is dismissing evals as theater and relying only on taste. His proposed middle path is to use evals skeptically as an engineering loop: run the benchmark, inspect every failed trajectory, allocate failures by cause, make one small change, rerun the full eval, and keep checking whether the product actually behaves better.
That matters because agent evals test multiple things at once. A low score may reflect a weak model. It may also reflect a broken tool, an under-provisioned container, an overly short timeout, a prompt that works for Anthropic models but not Gemini or Qwen, or a bad benchmark task. Khan’s Terminal-Bench account makes the evaluation layer part of the product architecture, not a post-hoc report card.
| Layer | What can go wrong | Cline’s practical response |
|---|---|---|
| Model | The underlying model may be unable to solve the task | Compare across model families, but do not assume model choice explains the result. |
| Harness | Tools, prompts, memory, timeouts, and environment may prevent the model from succeeding | Inspect traces and change one lever at a time. |
| Environment | Containers may lack enough CPU, memory, or runtime | Tune infrastructure before attributing failure to intelligence. |
| Evaluator | The benchmark may be stale, contaminated, toy-like, or misaligned with product behavior | Use current, precise evals and keep a product-level vibe check. |
Nathan Labenz raised the same issue at higher stakes. He described frontier-lab circles as treating AI-accelerated AI research and recursive self-improvement as credible near-term concerns. The control strategy he heard most clearly was not a single formal governance mechanism; it was AI systems monitoring other AI systems. Labenz came away unimpressed with the concreteness of the plans, while also noting that participants seemed aware that current approaches may be inadequate and that coordinated slowdown might be needed if acceleration outruns control.
The most concrete “self-improving” example in Labenz’s account was not a model rewriting its own weights. It was OpenAI engineers describing a tax-preparation harness that improves from practitioner corrections. Arthur Fernandes clarified that the improvement is mostly in the harness: instructions, skills, durable artifacts, and workflow scaffolding. If a practitioner corrects the system, the system should behave more like a coworker that does not repeat the same mistake. Over time, some skills become obsolete as models improve, while new edge cases create new scaffolding.
That tax example sits close to Khan’s Terminal-Bench lesson. In both cases, progress comes from the loop around the model: collect traces, inspect corrections, modify scaffolding, rerun, and see whether the outcome improves. Labenz’s account also showed the cautionary side. AI science systems can produce plausible papers while hiding simple code failures; moderation behavior can diverge from published model specs; cyber performance may depend on private data and expert judgment; human-facing systems such as mental-health agents may spend a large share of inference on safety architecture.
The difference between Khan and Labenz is not disagreement over whether scaffolding matters. It is the risk frame. Khan’s message is pragmatic: evals are noisy, but useful when treated as disciplined engineering feedback. Labenz’s message is more cautionary: if labs rely increasingly on AI monitors and harness layers to control faster AI-driven research loops, the adequacy of those layers becomes a central safety question.
As AI systems act more directly, the differentiator may be less the model in isolation than the system’s ability to constrain, evaluate, observe, and revise the model’s work. That is an opportunity because scaffolds make useful systems possible sooner. It is also a dependency because the same scaffolds become the place where failures accumulate.