Cline’s Terminal-Bench Gains Came From Harness Tuning, Not Model Switching

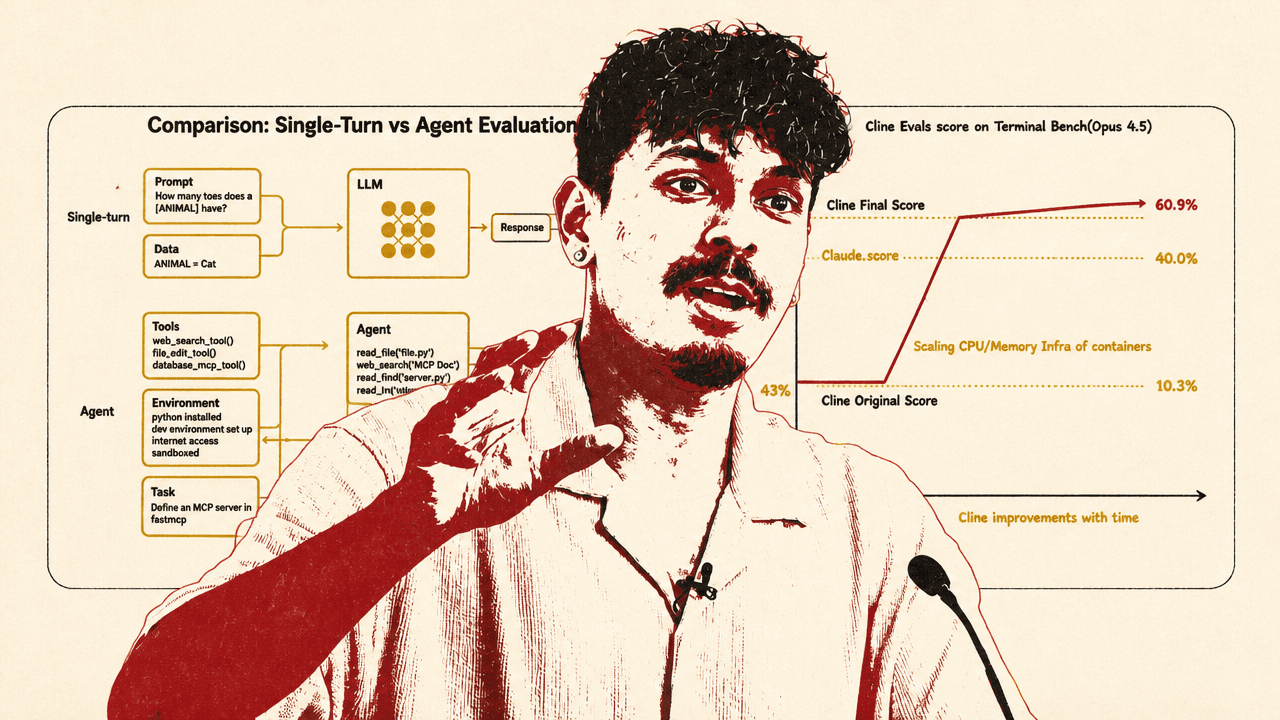
Ara Khan of Cline argues that AI evals are too noisy to treat as truth but too useful to replace with vibes. Using Cline’s Terminal-Bench work as the case study, he says the company’s jump from 43% to 57% came from harness changes — container CPU and memory, longer timeouts, and model-family-specific prompting — rather than a better model. His prescription is to run evals skeptically, inspect failed traces, allocate failures by cause, and improve only the levers that survive contact with product behavior.
Benchmark numbers are neither gospel nor useless
Ara Khan’s central claim is deliberately uncomfortable: most people are wrong about evals, but not in the same way. One camp treats public benchmark numbers as objective truth. The other treats taste, feel, and vibes as the only meaningful signal. Both positions fail.
The “objective metrics” mistake is to look at a leaderboard and infer too much from adjacent scores. An Artificial Analysis Intelligence Index chart served as the example: people read such dashboards as if two models with similar numbers are effectively the same. “Believe me, they’re not the same,” Khan said. At some point, he argued, model benchmark numbers can become so disconnected from practical use that, if treated literally, “the whole thing is a hoax.”
A contemporaneous François Chollet post sharpened the critique. Chollet described Meta’s new model as “already looking like a disappointment,” saying it appeared “overoptimized for public benchmark numbers at the detriment of everything else.” The broader claim in the post was that knowing how to evaluate models in a way that correlates with usefulness is a core competency for AI labs.
The warning was not only about Meta or any single lab. Khan’s first heuristic was blunt: when a model lab publishes an eval number, “just don’t believe them.” He softened that only slightly: treat the numbers as approximations. Sometimes they are useful; sometimes they are not.
The opposite failure mode is the “taste is king” camp. This is the group that reduces model choice to vibes, sometimes anthropomorphizing a model: asked why they like Opus, they might say, “I like talking to her.” That, too, is not enough. Taste can catch failures benchmarks miss, but taste alone does not give a team a repeatable engineering system.
Evals are not the end all and be all. Evals are also not completely useless.


The practical position Khan defended sits between those camps. Evals should be used, interpreted skeptically, and connected to real product behavior. The goal is not to worship benchmark scores or dismiss them, but to learn how to build with them, interpret them, use them in agentic flows, and improve systems through them.
Use outside evals carefully: current, precise, and not too early
Khan divided eval maturity into three levels: using evals from outside sources, using evals to improve one’s own agents, and building custom evals for specific use cases. He focused on the first two, because they are the levels he thought would be most immediately useful to the audience.
For outside evals, his second heuristic was to stay current without becoming the earliest adopter. He used the Epoch Capabilities Index, an aggregate score chart of model performance over time, to make the point that frontier models have been changing every few months. Even for someone working in the field full time, he said, preferences change quickly.
His advice was to let a new model or benchmark “set on fire for a couple weeks.” If it still looks strong after that, then consider switching or investing time in it. The people who need to try every model immediately are people like Khan, who work on this for a living. Most teams do not need to live permanently on the cutting edge.
The third heuristic was to look for evals that are both very new and very precise. Old standardized evals often stop measuring what people think they measure. Khan cited a screenshot from an OpenAI publication whose headline was: “Why SWE-bench Verified no longer measures frontier coding capabilities.” The same slide said: “SWE-bench Verified is increasingly contaminated. We recommend SWE-bench Pro.”
Khan said that to many AI researchers, it was already obvious that SWE-bench was no longer a good proxy for frontier coding ability. He characterized some older coding benchmark tasks as too toy-like — examples such as Fibonacci sequences or matrix multiplication — and said they do not apply well to real-world software engineering.
The standard, then, is not novelty by itself. A benchmark should be new enough to avoid saturation and contamination, precise enough to match the work being evaluated, and legitimate enough that optimizing for it does not pull the system away from real usefulness. Khan emphasized that this takes discernment.
Agent evals are harder because the search space is open
The core difficulty in evals for agents is that they are both an engineering problem and a philosophy problem, Khan argued. The engineering problem is implementation: harnesses, environments, graders, metrics, traces, and infrastructure. The philosophy problem is harder to pin down: the real task space is open-ended, and any eval is only an approximation of where a system can fail.
That is especially visible in coding agents. A single-turn LLM eval can ask a question with a compact answer and grade the response directly. Khan gave a deliberately simple example: ask how many toes a cat has, receive an answer, mark it right or wrong. The search space is limited.
An agent task is different. A user might say: “I have this new MCP server, it’s probably not working. How do you make it work for me?” The agent may read files, search documentation, install dependencies, set up an environment, run scripts, edit code, execute tests, and then decide whether the system works. The final answer is not enough. The system may appear to work while breaking something else. The grading has to account for the trajectory and the outcome.
Khan described Cline’s own shift on this question. Cline is an open-source coding agent company, and at an earlier stage, he said, the team’s view resembled that of other teams they had spoken with, including the Codex team: available evals were rudimentary, did not measure daily programming work, and could be ignored in favor of vibes. Over time, Cline changed its stance. If no one else had the evals they needed, Khan said, they would build them.
Cline’s own effort began with real user data from people who had opted in to share coding usage. Khan said the company offered users money, collected a large dataset of actual problems people were solving, parsed that data, produced a list of tasks, and then performed substantial manual cleanup to make the problems suitable for coding agents.
That work reflects the central tradeoff: an eval must be standardized enough to run repeatedly, but realistic enough that it measures something close to real agentic work. A benchmark made of toy tasks may be easy to score, but it will not necessarily tell a team whether its agent solves meaningful software problems.
Terminal-Bench gave Cline a concrete hill to climb
Khan described Terminal-Bench as an outside benchmark that approximated the kind of real agent work Cline cared about. In Khan’s description, it came from “very, very awesome smart bright people from Stanford University” and contained 89 coding problems designed as reasonable approximations of real-world programming tasks. Examples included race conditions, database issues, infrastructure problems, and similar terminal-based work.
Some tasks, Khan said, can take 30 to 40 minutes for an agent to run. For him, that duration is part of the benchmark’s credibility: the agent has to do many things, may run in circles, may fail unpredictably, and has to operate inside a realistic environment rather than answer a short prompt.
Khan framed an agent eval suite as a set of tasks, each with inputs, success criteria, graders, metrics, and an environment. The system records a trajectory: messages, tool calls, reasoning, and final state. Graders can then score different aspects of performance. The evaluation architecture he described included deterministic tests, LLM rubrics, state checks, and tool-call checks, along with tracked metrics such as number of turns, number of tool calls, tokens, and latency.
The environment matters. For a task like diagnosing a race condition in a repository, the eval needs an isolated virtual machine or container with the repository and required setup. The agent — Cline, Claude Code, Codex, or another CLI-based system — must be installed and run there. Khan said this is not exactly hard, but also not trivial.
He highlighted Harbor as software that, in his words, came from the Lott Institute and helps standardize and parallelize this process. Rather than running 89 tasks sequentially and manually setting up each one, Harbor can define a standardized configuration for each task: Linux machine, RAM, CPU, and isolation. Those tasks can then run in parallel on infrastructure such as Modal, Daytona, or sufficiently powerful local Docker machines. Cline used Modal, and Khan said Modal “helped us a lot.”
The practical consequence is that the slowest task becomes the limiting factor, rather than the sum of all tasks. That makes repeated evaluation feasible enough to support iterative improvement.
The score only matters after the failures are allocated
Khan’s recommended loop is simple but demanding: run the eval, get an original score, evaluate every failure, bucket the failures by cause, make one small change, rerun the full eval, and repeat.
| Step | What the team does | Why it matters |
|---|---|---|
| Run the eval | Execute the full task suite and get an original score. | Creates the baseline for hill climbing. |
| Inspect failures | Review the failed trajectories, often by sending another agent through the traces. | Turns a score into diagnoses. |
| Bucket causes | Group failures by common themes: broken tools, missing tests, timeouts, distraction, or other patterns. | Shows which problems are frequent enough to fix first. |
| Make one small change | Adjust one lever, then rerun the whole eval. | Keeps the improvement attributable rather than accidental. |
| Repeat | Use each run to expose the next set of flaws. | Makes evals an engineering loop rather than a one-off report. |
The key step is failure allocation. If an agent fails 50 of 89 tasks, Khan does not recommend treating the score as a single undifferentiated signal. He recommends sending another agent through the full traces of the failed runs. Each trace is a large record of every LLM call and action the agent took. The analysis should identify why each task failed: it did not run tests, a read-file tool broke, inference was too slow and timed out, the agent got distracted, or some other common pattern appeared.
Khan called this “portfolio allocate” the failures. The goal is to identify which levers actually move the score. If 10 failures come from one tool bug, 20 from timeouts, and 30 from agents going off the rails, the team can make targeted changes rather than guessing.
He said an eval run is really testing three things at once.
| What is being tested | Khan’s explanation |
|---|---|
| The model | A strong enough model can sometimes compensate for a poor harness and still produce a good score. |
| The harness | The scaffolding around the model determines whether the system actually leverages the model well. |
| The sanity of the problem | If the benchmark task is bad, a high score can mean the system optimized for the wrong thing. |
The harness point is central to Khan’s view of agent development. He pointed to the common observation that Anthropic models may work in Cursor, Droid, or other coding agents, but seem to work especially well in Claude Code. His interpretation was that this is not just about the model; it is about whether the harness brings out the best in the model.
The third category is a guardrail. If a team is solving “stupid problems,” Khan said, then scoring 100% does not matter. He credited the Lott Institute with doing a strong job on problem sanity for Terminal-Bench, but his broader warning was that every team has to remain honest about whether the benchmark corresponds to the product behavior they care about.
Cline’s Terminal-Bench gains came from infrastructure, timeouts, and prompting — not a model swap
Cline’s Terminal-Bench score began at 43%, according to Khan. The hand-drawn chart he presented ended at a 57% Cline final score and also included a 52% marker labeled “Claude code.” The visible improvement path named the specific interventions: scaling CPU and memory infrastructure for containers, raising the timeout of individual CLI runs, and improving thinking behavior.
A low score, in Khan’s account, might mean the model is weak. It might also mean containers are under-provisioned, the CLI run times out too early, or the harness prompts the model in a way that undermines performance.
Khan gave a concrete example around “thinking” behavior. Sometimes asking a model to think more helps. Sometimes it damages the response because the model loops, stalls, or spends thousands of tokens in unproductive repetition. The right intervention depends on the model family and the harness.
Cline maintains an internal benchmark across many kinds of models, including open-source models, Khan said. The purpose is not only to rank models, but to learn where the harness is tuned too narrowly. He said Cline found it was “very decent” on Anthropic model families, but not as strong on Gemini or Qwen model families, even though those models are themselves capable. Hill climbing revealed that better support for those model families could open Cline to users who prefer them.
That leads to Khan’s three zones of improvement.
The first zone is obvious flaws: crashes, rate limits, broken tools, or other straightforward bugs in the harness. These should simply be fixed.
The second zone is the real work: nuanced improvements. This includes prompt-engineering techniques that work for Anthropic models but do not transfer to Codex or Gemini, adjustments in prompt size, and other model-family-specific changes. This is where Khan locates the answer to a common builder frustration: why a model everyone calls excellent somehow fails inside a particular product or harness.
The third zone is the danger zone: overfitting to the benchmark. Khan described this as “straight up cheating” to get the highest score and post about it. He said many people have done it, and explicitly told the audience not to.
Honest hill climbing still has to pass the product test
Khan’s final prescription was not “trust benchmarks.” It was: find the benchmark, build the evals, and hill climb honestly. Hill climbing means taking a score, improving the harness against the eval, and repeating the process. But the score is only one half of the standard.
The other half is the “vibe check”: whether the product and model actually feel good to use. Khan’s warning cuts both ways. A good number is insufficient if the agent is unpleasant, unreliable, or misaligned with real user work. Good vibes without eval discipline leave a team guessing.
For Cline, the discipline surfaced practical constraints that were easy to miss: CPU and memory settings, CLI timeouts, model-family-specific prompting behavior, and harness choices that changed how capable the same underlying model appeared. For other teams, Khan suggested the abstraction will hold even if the domain is not coding: approximate the real problem, improve the score honestly, and keep testing whether the resulting system works for users.