AI Deployment Runs Into The Rest Of The Stack
Bloomberg, ServiceNow, Nvidia, Cursor, Fireworks, EXO Labs, Unblocked, and Wall Street Prompt each point to the same shift: applied AI is becoming constrained by power, chips, inference systems, runtime controls, organizational context, and human fluency. The competitive question is moving from which model performs best to which companies can make the surrounding stack work reliably enough for deployment.

AI’s new bottleneck is the rest of the stack
AI is leaving the software-only phase. The clearest pattern is not that models stopped improving; it is that deployment is colliding with everything around them. Electricity has to be generated, moved, and stabilized. Memory and chip capacity have to be manufactured. Inference has to be routed across cloud, local, specialized, and distributed systems. Agents have to be bounded by runtime controls. Coding tools have to understand the organizations whose code they modify. Professionals have to learn how the systems apply to their actual work.
That changes the applied-AI question. For the last two years, the easiest comparison was model against model: which system reasoned better, coded better, summarized better, or used tools more reliably. The more consequential comparison now is stack against stack. A company may have access to the same frontier model as its competitor and still lose if it cannot secure power, route inference economically, govern agents, preserve organizational context, or retrain its workforce.
The capacity map now runs from grids to training rooms. Bloomberg’s grid primer treats electricity as a binding input for AI and broader electrification. Daniel Pilling of Sands Capital treats memory, chip equipment, CPUs, and power providers as bottleneck beneficiaries, not just Nvidia. Bloomberg’s Qualcomm report shows hyperscalers looking beyond standard accelerator purchases toward custom ASIC execution. Cursor and Fireworks describe model specialization as an infrastructure problem, not just a training recipe. EXO Labs argues that local frontier AI is still a 100x price-performance problem across memory, kernels, energy, orchestration, and benchmarks. ServiceNow and Nvidia frame agents as governed systems of models, harnesses, sandboxes, permissions, and control towers. Unblocked’s Brandon Waselnuk argues that coding agents need organizational tenure, not just tool access. Bloomberg’s Wall Street report shows that even highly resourced banks are paying for human fluency after buying the software.
No single architecture emerges as the answer. The important shift is that “the model” has become inseparable from the physical, computational, organizational, and human systems in which it runs.
Power and chips are becoming the capacity ceiling
The hardest constraint sits below the data center. Bloomberg’s grid account argues that after decades of flat or declining electricity demand in many Western economies, AI, electric vehicles, and heat pumps are forcing electricity systems back into expansion mode. That makes AI growth a grid story, not only a data-center procurement story.
The change is structural. Rich Miller, a former Con Edison executive, ties the long plateau to post-1970s efficiency efforts and the shift away from energy-intensive manufacturing. Akshat Rathi says the industry is now seeing demand growth after roughly three decades in which many Western systems were not built for rapid expansion. The International Energy Agency projection shown in the piece has global electricity use roughly doubling by 2050. Bloomberg frames that as adding about “a whole new USA’s worth of electricity every five years.”
China is used as the contrast, not as a simple geopolitical verdict. Dan Murtaugh says China kept building its grid “basically nonstop since the 1990s,” while Western grid growth slowed. Bloomberg’s charting shows China’s power generation rising sevenfold from 2000 to 2024, while US electricity demand stayed comparatively flat. The implication is practical: countries that kept grid supply chains and skilled workforces active enter the AI and electrification wave with different capacity than countries trying to restart.
The grid story also complicates the clean-power story. Bloomberg’s Spain example shows that adding solar is not enough if the system loses physical stability services once provided by spinning generators. Guy Nicholson of Statkraft argues renewables “did exactly what they were told to do” during the Spanish blackout; the failure was that the grid lacked needed stability services. Synchronous compensators and other stabilizing machines become part of the AI infrastructure conversation because a renewable-heavy grid still has to maintain second-by-second balance.
Semiconductors are the more familiar bottleneck, but Pilling’s argument widens it beyond GPUs. He says AI demand is early, fast-growing, and meeting an industry with long lead times, oligopolistic suppliers, and pricing power. His estimate that only 2% to 3% of roughly one billion office workers use AI tools today is meant to show how much adoption may remain ahead. If that adoption arrives faster than supply can be built, the shortage map spreads through memory, chip equipment, power, and CPUs.
| Layer | Constraint described | Why it matters for applied AI |
|---|---|---|
| Electricity grids | Demand growth is returning after decades of flat Western consumption | AI data centers compete for power delivery and grid stability |
| Memory | Pilling says memory will become an increasingly significant bottleneck | AI workloads need more than GPUs; they need high-bandwidth memory supply |
| Chip equipment | Pilling names ASML and Lam Research as critical suppliers | Capacity expansion depends on tools that foundries need to make chips |
| CPUs | Pilling says agentic AI needs many CPUs | Agent systems use orchestration, tool execution, and conventional compute around accelerators |
| Custom ASICs | Qualcomm is reported to be helping ByteDance move AI chip designs toward volume | Hyperscalers are diversifying beyond standard accelerator purchasing |
Bloomberg’s Qualcomm report adds a second compute-supply pattern. Ian King says Qualcomm will supply AI data-center chips to ByteDance and frames the deal as a breakthrough in at least one part of the AI infrastructure market. The point is not just that Qualcomm has a named customer. King describes two routes: Qualcomm’s own processors and a Broadcom-like custom-chip role, helping large customers turn AI-chip designs into high-volume silicon. Caroline Hyde described the ByteDance arrangement as involving “millions of ASICs,” and King emphasized Qualcomm’s long history in system-on-chip design and volume execution.
That points to a more fragmented physical stack. Hyperscalers and AI application companies are not simply waiting in one line for one class of accelerator. They are buying memory, securing power, relying on chip equipment capacity, bringing CPUs back into the architecture, and exploring custom ASIC production. The bottleneck has moved from “can a model run?” to “can the surrounding industrial system supply enough stable power and specialized silicon for it to run everywhere people want it?”






Inference is becoming specialized infrastructure
The middle of the stack is fragmenting by workload. Cursor’s Composer work and EXO Labs’ local-inference argument point in different directions, but they share one premise: inference economics will be shaped by system design as much as by model scale.
Cursor’s Federico Cassano describes Composer 2 as a model strategy built around spending capacity on one environment: software engineering inside Cursor. His analogy is that a model is “sort of like a storage drive” with finite bits. Cursor wants those bits allocated to Cursor’s tools, interaction patterns, and coding-agent behavior, not to broad general-purpose competence. Dmytro Dzhulgakov of Fireworks treats that as an application-company pattern: once a product has usage data, tools, and a clear environment, training can push quality, speed, and cost beyond what prompting a larger general model can provide.
The operational details matter because they show specialization becoming a production discipline. Composer starts from Kimi 2.5, which Cassano describes as a one-trillion-parameter mixture-of-experts model with 30 billion active parameters. Cursor then uses mid-training and reinforcement learning inside environments that approximate its product. RL rollouts are full agent sessions, not isolated next-token predictions: the model calls tools, sees results, writes code, receives reward, and updates behavior.
Fireworks’ role is infrastructure. Cursor trained with one cluster and distributed inference across smaller clusters in different regions, using four clusters in total. Dzhulgakov says the Kimi model snapshot is about one terabyte, while training steps take roughly five to fifteen minutes. Sending full snapshots around the world would be too slow, so Fireworks and Cursor compressed and synchronized model deltas, about 20 times smaller than the full model in Dzhulgakov’s description. They also had to align inference and training numerically so that the trainer updated the path the model actually took during rollout.
EXO Labs comes at the same middle layer from the other side: not “specialize inside one cloud product,” but “make capable models run locally by attacking the inference stack.” Alex Cheema’s claim is explicitly not that local AI already beats the cloud. His reference point is awkward and expensive: GLM 5.1, which he described as probably the frontier open model at the moment, running on a setup like four 512GB Mac Studios at roughly $40,000 of hardware and around 20 tokens per second. He says users have come to expect closer to 50 tokens per second from cloud systems.
Cheema’s argument is that this is a systems gap, not a permanent verdict. Local inference is mostly memory-bound during decode, not compute-bound like training. The practical questions are whether the model fits in memory, how much memory bandwidth is available, and how much energy is spent moving bytes. He points to inefficient kernels, unnecessary launches, local orchestration, heterogeneous execution, RDMA, and honest benchmarks as places where the stack remains under-optimized. In one Qwen 3.5 case, he says EXO recovered about 30% inference performance by fusing kernels.
Prefill and decode explain why “local AI hardware” is not one category. Cheema says prefill wants compute, while decode wants memory capacity and bandwidth. A Mac may fit a huge model in unified memory but run it slowly; an RTX-class GPU may run smaller models quickly but lack enough VRAM. EXO’s answer is heterogeneous execution: split work across different devices according to which part of inference they handle best.
| Approach | Main bet | Constraint it attacks |
|---|---|---|
| Cursor Composer | Train a model inside one product environment | Quality, latency, and cost for Cursor-specific software engineering |
| Fireworks distributed RL | Pipeline training and rollouts across heterogeneous clusters | Utilization, weight synchronization, and efficient agent training |
| EXO local inference | Optimize the full local stack around memory, kernels, energy, and orchestration | Price-performance gap between local systems and cloud inference |
| Heterogeneous local execution | Split prefill and decode across devices | Different inference phases stress compute and memory differently |
The shared point is that inference is no longer a single line item called “model serving.” Cursor’s work says an application company can get leverage by training inside its own product environment. EXO’s work says the local frontier depends on memory hierarchies, interconnects, energy, kernels, and benchmarking. In both cases, the model is inseparable from the harness, hardware, runtime, and task distribution around it.


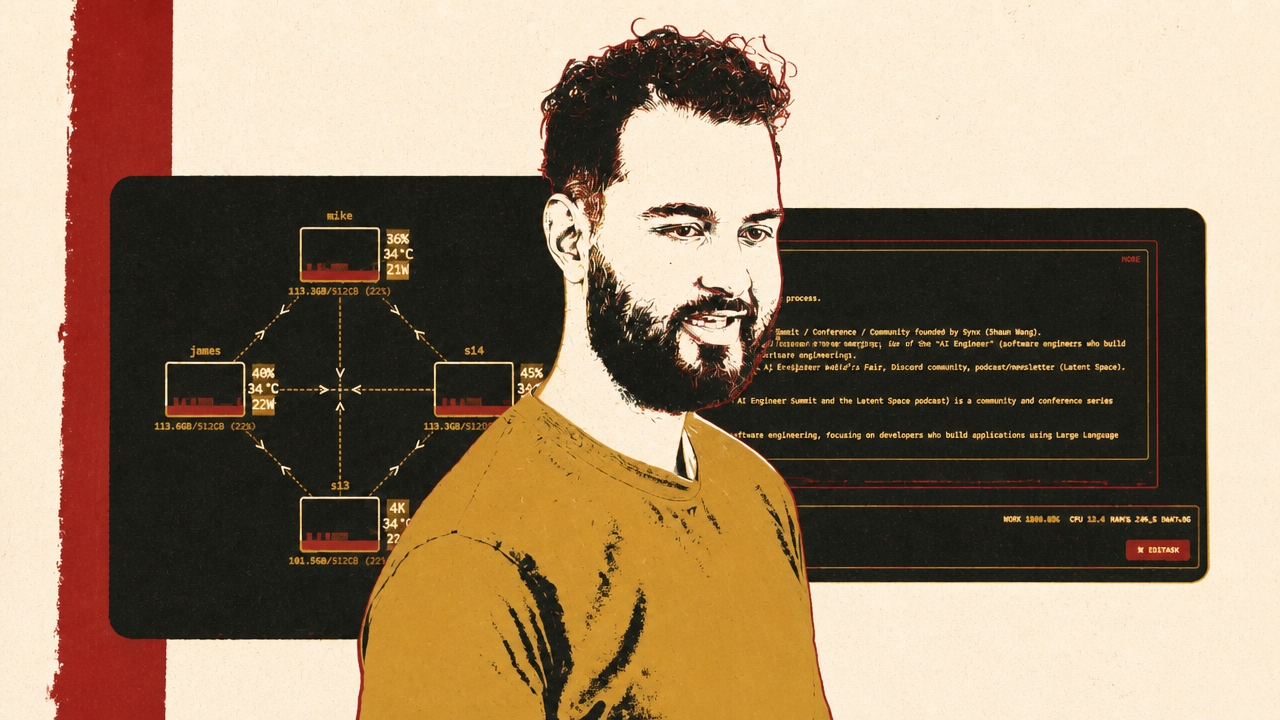
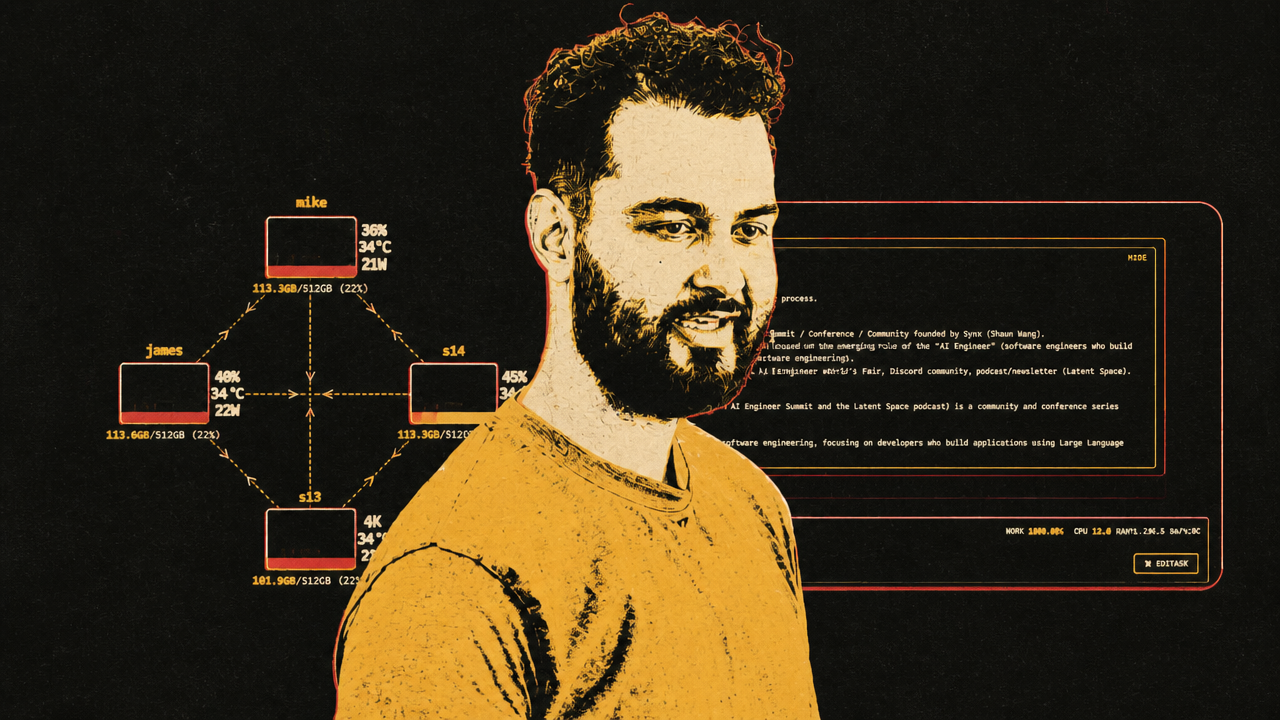
Enterprise agents need guardrails, not vibes
At the enterprise layer, ServiceNow and Nvidia argue that agent adoption depends less on trusting models and more on constraining execution. Joe Davis of ServiceNow and Adel Hallak of Nvidia describe agents as layered systems: models, harnesses, tools, sub-agents, sandboxed runtimes, identity, permissions, monitoring, and control towers. The practical claim is that useful autonomy is bounded autonomy.
The risk is concentrated in what Hallak calls the “lethal trifecta”: internet access, internal knowledge, and terminal or code access. Any one of those can be useful. Together, they let an agent read private information, act in the outside world, and modify systems. Davis compares agents to “mini engineers” that can operate continuously and at machine speed. That is exactly why the enterprise answer cannot be to ask the model to be morally reliable.
ServiceNow and Nvidia put the enforcement point in the runtime. Hallak describes Nvidia’s OpenShell as a secure runtime that controls what an agent can access, read, write, and call. It runs agents in sandboxes and supports policy enforcement during execution. Davis says ServiceNow connects that local sandbox to its cloud through an AI Control Tower, giving central visibility and policy across agents running on users’ machines.
The governing phrase is “deny by default.” Hallak compares the posture to zero trust: an agent does not begin with broad permissions and then get talked out of bad actions. It begins with no access, and specific actions must be explicitly granted. Davis says that if an AI decides it wants to update a salary in Workday, the company can deterministically block or prevent the action through identity and permissions.
The enterprise agent question is shifting from “can it do the task?” to “can the company prove, limit, monitor, and reverse what it does?”
The same architecture explains why “harness” has become an important term. Hallak defines the agent formula as model plus harness, in a runtime. The harness gives the model tools: file-system access, code interpreters, MCP tools, skills, and integrations. Davis describes it as a loop trying to complete a task with specific tool access. In enterprise settings, the harness is both a capability layer and a control surface.
ServiceNow’s internal IT-support automation is the proof point Davis offers, not a universal guarantee. The example is first-level support: employees need access to an application, cannot open email or a browser, or file another workplace-technology request. Davis says ServiceNow has automated 90% of support requests in this area internally, and that resolution times can fall by as much as 99% when the AI can complete a task in minutes rather than leaving it in a human queue. Hallak adds that even when the system cannot resolve a ticket, it can research documents, inspect screenshots, and hand a more complete case to a human support worker.
Those numbers matter because they anchor the governance discussion in a real workflow. The argument is not that agents should roam freely because they are now capable. It is that enterprise autonomy becomes deployable when the company can define identity, permissions, runtime boundaries, escalation paths, and observability. In that version of applied AI, the safety layer is not a policy document attached after the fact. It is part of the architecture.


Context is what makes agent work mergeable
Governance controls what agents may do. Context determines whether their work is any good.
Brandon Waselnuk of Unblocked describes the coding-agent failure mode with unusual precision: agents often have access, but not tenure. They may have tools, MCP connections, RAG, large context windows, repository access, and documentation. What they lack is the organizational memory a long-tenured engineer uses automatically: team conventions, ownership, Slack decisions, pull-request history, compatibility constraints, migration plans, rejected approaches, and which source of truth outranks another.
His analogy is a smart new engineer who has just arrived with no organizational context. That engineer can read code and still make bad changes because they do not know why the code looks the way it does. A coding agent can compile code that should never merge. Waselnuk’s distinction is “mergeable, not just functional.”
The three common fixes he rejects all provide more material without enough judgment. Naive RAG may stop after the first plausible result, a failure mode he likens to “satisfaction of search.” MCPs connect more data pipes but do not tell the agent where to look or what matters. A larger context window can hold more raw material without resolving conflicts among code, documents, tickets, and conversations.
A context engine, in his definition, is a runtime research-packet generator. It reasons across code, pull requests, planning tools, documents, conversations, and social structure, then returns a compact, token-optimized packet before the agent plans or writes code. It has to handle personalized relevance, data governance, conflict resolution, and authority. If main contains one implementation but a CTO wrote in Slack that the implementation is wrong, the engine should not flatten the conflict into a single answer. It should surface the contradiction and the authority signal.
The Kotlin SDK example makes the distinction concrete. Waselnuk describes two runs of the same task: add adaptive thinking mode for Claude 4.6 models while preserving backwards compatibility for callers using the old budget_token method. The no-context run compiled and passed checks, but a senior engineer requested changes because the implementation auto-detected adaptive mode for 4.6 models and broke existing callers. The context-engine run, according to Waselnuk, preserved opt-in defaults, followed factory patterns, covered all three modules, and received only a minor nitpick.
That example rhymes with Cursor’s Composer strategy. Cursor trains a model inside its product environment so it learns how to act within Cursor. Unblocked argues that an enterprise coding agent needs organizational context before acting inside a company’s codebase. One is model specialization through training; the other is runtime context assembly. Both reject the idea that a general model plus tool access is enough.
The broader enterprise lesson is that context becomes a moat only if it is available at execution time. Companies already possess the relevant information, but it is scattered across GitHub, Slack, Teams, Jira, design docs, incidents, code reviews, and human memory. Agent performance depends on whether that information can be made current, permission-aware, conflict-aware, and compact enough to guide action.


The last bottleneck is fluency
The human layer has its own capacity problem. Bloomberg’s Sally Bakewell frames Wall Street’s AI challenge as a shift from procurement to fluency. Banks have already spent “millions and billions” on AI software, she says. The harder question is whether senior professionals know how to apply those tools to finance-specific work quickly enough to keep the institution competitive.
Wall Street Prompt is the signal. Bakewell says the firm, founded by two former SoftBank fund managers, can charge $25,000 a day to train bankers and has a two-month backlog. Its sessions are not generic chatbot lessons. Bakewell describes training on tasks such as using Google Gemini with FBI-style behavioral analysis to spot red flags in founder pitch videos, and using ChatGPT and Claude to analyze earnings transcripts for market-moving information and build forecasting models.
That price points to a scarce resource: not access to ChatGPT, Claude, or Gemini, but the ability to translate those tools into institutional workflows. Bank of America, Citi, and T. Rowe Price are named as clients. JPMorgan has rolled out an LLM suite, Goldman is working with Anthropic, Bank of America says AI has made developers more productive, and Jamie Dimon says he uses AI every day. Bakewell’s point is that tool access and executive awareness still do not automatically create organization-wide competence.
The anxiety is double-sided. Caroline Hyde’s setup notes banks apologizing for describing some people as “lower value human capital,” while still committing to training. Bakewell says AI is being treated not just as a tool for efficiency but as “a requirement for survival.” Automation fear and training budgets are becoming part of the same institutional response.
Singapore appears as a competitive signal. Bakewell says Wall Street Prompt is considering expansion there because the city-state is focused on ensuring new financial-sector workers are AI fluent. That turns training from a back-office productivity exercise into a labor-market and financial-center competition.
The pattern mirrors the rest of the stack. Electricity access does not guarantee useful AI if the grid cannot deliver or stabilize power. A model does not guarantee enterprise autonomy if the runtime cannot enforce permissions. A coding agent does not guarantee mergeable code if it lacks organizational context. AI software does not guarantee productivity if professionals cannot reshape diligence, research, forecasting, and communication around it.

