Local Frontier AI Still Needs 100x Better Price Performance

Alex Cheema of EXO Labs argues that running frontier AI locally is primarily an inference-stack problem, not a model-training problem. Using a four-Mac Studio GLM 5.1 setup that costs about $40,000 and reaches roughly 20 tokens per second as the current reference point, Cheema says local price-performance still has about 100x to improve through better kernels, interconnects, heterogeneous hardware, energy efficiency, orchestration, and benchmarks. His case is that today’s awkward home cluster is not the endpoint, but evidence of how much optimization remains outside the cloud.
The local frontier is an inference problem, not a training problem
Alex Cheema framed EXO Labs around a specific claim: frontier AI should be able to run on local hardware, and the work required to make that practical is not mainly about retraining models. It is about the full inference stack — models, kernels, orchestration, hardware, networking, energy, and the harness that turns a model into a useful system.
Most AI today still runs in cloud data centers. Cheema’s objection was not just cost, though cost matters. His deeper argument was that AI is moving from a chat tool toward what he called an “exocortex”: an extension of the user’s own cognition. In that world, the question is no longer simply whether a hosted API is convenient. It is whether people want to “rent” something that increasingly behaves like part of their working memory, data environment, and agency.
He quoted Andrej Karpathy’s formulation: “not your weights, not your brain.” The phrase, for Cheema, captures several concerns at once: where the data goes, whether the system can be cut off, who controls access, and whether the most capable models become a concentrated source of leverage for a few companies. He described a cybersecurity friend who, while doing legitimate penetration testing work, was locked out of three major API providers — Claude, Gemini, and ChatGPT. Dependency on centralized systems becomes more consequential as AI moves deeper into professional workflows.
Cheema distinguished this from the more common debate about open training. Transparency in training matters, but EXO’s focus is narrower and more immediate: if the model already exists, what does it take to run it? If the answer is “a million dollars of hardware,” open weights do not solve the practical access problem.
That is where he thinks the current stack is still immature. Much of the hardware and software ecosystem was optimized around training, especially around NVIDIA GPUs in data centers. Cheema invoked Sara Hooker’s “Hardware Lottery” argument to describe the inertia: research directions often reflect the hardware stack that happens to be dominant, not necessarily the hardware that would be best for a given workload. For inference, and especially local inference, he argued that the useful design space is still underexplored.
The examples he gave were deliberately concrete. EXO had recently looked at Qwen 3.5 on Apple Silicon and found that measured performance was about 50% worse than what they expected from theory. The issue was not a new model architecture or a missing breakthrough. It was overhead from inefficient kernels, including unnecessary separate kernel launches. At a target like 150 tokens per second, a few milliseconds of overhead matters. By fusing kernels, EXO recovered about 30% inference performance.
Cheema used that case as evidence for a broader claim: much of local inference is not close to optimal. Kernel fusion is one layer. Orchestration is another. Hardware interconnects and communication overhead are another. The harness matters too. He noted that the same model can behave very differently under Claude Code versus OpenCode, because the surrounding system changes how the model is used. In local settings, where resources are constrained, a harness that understands the hardware can materially change practical performance.
Decode, not prefill, sets the local hardware agenda
Cheema’s technical argument began with a distinction that determines what kind of hardware matters. Training is compute-bound: the economics are largely about FLOPS and energy per FLOP. Inference, especially local inference at low batch sizes, is mostly memory-bound.
In LLM inference, he separated the prefill phase from the decode phase. Prefill loads the prompt and generates the KV cache. Decode is the autoregressive phase that generates tokens one by one. Cheema said prefill is compute-bound, while decode is memory-bound. For local use, he argued, decode is the more important constraint.
The slide Cheema used to explain this showed a prompt — “What are LLMs?” — entering an initial prefill iteration, then successive decode iterations producing “LLMs,” “are,” “neural,” “networks,” “that,” and continuing from there, all connected to a KV cache. The first stage builds the cache from the prompt, while the second repeatedly consults that cache and emits one token at a time. Cheema’s hardware argument followed from that split: the two phases do not stress the machine in the same way.
His reason was not that prefill is irrelevant. It was that good harnesses can reduce how often the same prefill work has to be redone. He pointed to Claude Code’s /context display as an example: much of the prompt is stable system prompt, tools, and other context that does not change request to request. The screenshot he showed listed 63k of 200k context tokens in use for Claude Opus 4.5, including 2.9k system-prompt tokens, 14.7k system-tool tokens, and 45.0k tokens reserved for the autocompact buffer. If a harness can preserve cache hits and keep much of the prompt constant, long-prompt benchmark behavior can overstate the importance of prefill for real workloads.
For decode, Cheema reduced the local hardware question to three practical variables: first, whether the model fits in memory; second, how much memory bandwidth is available; and third, how much energy is spent moving bytes.
| Decode constraint | Why Cheema said it matters locally |
|---|---|
| Memory capacity | The model has to fit in memory; loading from disk is too slow for useful inference. |
| Memory bandwidth | Decode speed depends on how fast weights and KV cache can be loaded into the GPU. |
| Energy per byte | Local devices expose power draw, heat, and battery limits directly to the user. |
Energy is not incidental in this framing. Cheema said phone demos often look impressive until the power and heat budget is considered. In EXO’s own phone experiments about 18 months earlier, he said inference could consume roughly 10 to 15 watts on a device with perhaps 10 to 15 watt-hours of battery. That is roughly an hour of battery life, and the phone became too hot to hold during benchmarking.
He connected this to recent work he attributed to a Stanford group around “intelligence per watt,” though he argued the better term is “intelligence per joule,” because the question is energy consumed per task rather than power at a moment in time. The metric, as he described it, divides model performance on a task by the energy used. Tracked over time, he said, it has been improving exponentially: roughly 5x over the past two years in one framing.
A later slide on efficiency contributions showed a larger combined gain: 18.0x total improvement, broken into 5.9x from hardware and 3.1x from model improvements. Cheema’s point was not that any one number settles the matter. It was that hardware and model improvements compound, and local AI should be evaluated across that whole stack.
Hardware memory capacity is also moving. Cheema showed a chart claiming a 126.3x improvement in local accelerator memory from 2012 to 2025, and noted that consumer hardware with hundreds of gigabytes of unified memory is a recent phenomenon. Apple no longer sold the 512GB Mac Studio configuration he had on stage, he said, but 256GB systems are available off the shelf. He also said a new M5 MacBook configuration could reach 128GB of memory at 614 GB/s memory bandwidth.
The larger conclusion was that local inference performance will not come from one lever. In Cheema’s account, it comes from fitting models in memory, increasing memory bandwidth, reducing energy per byte, improving kernels, improving model architectures, and making the harness aware of hardware behavior.
A $40,000 local setup is the current frontier example, not the endpoint
When asked whether consumers would really buy a $5,000 inference appliance, Cheema separated the present from what he expects within two years.
The present is expensive and awkward. GLM 5.1 had been released the day before the workshop, and Cheema described it as probably the frontier open model at that moment. He was somewhat tentative on the exact parameter count, but referred to it as a trillion-parameter model. In native FP16, he estimated it would require roughly 1.5 terabytes of memory. If someone used 512GB Mac Studios like the ones on stage, that meant roughly $40,000 of hardware to fit it. Even then, he said, such a setup might produce only around 20 tokens per second — below the roughly 50 tokens per second he thinks users have come to expect from cloud systems.
| Local frontier reference point | Cheema’s description |
|---|---|
| Model | GLM 5.1, released the day before the workshop; Cheema described it as probably the current frontier open model. |
| Scale | He referred to it as a trillion-parameter model, while checking the exact count aloud. |
| Native memory footprint | Roughly 1.5TB in FP16, by his estimate. |
| Hardware example | Four 512GB Mac Studios, if using the discontinued configuration he had on stage. |
| Approximate cost | Around $40,000 of hardware. |
| Expected speed | Around 20 tokens per second in that kind of setup, in his estimate. |
Cheema’s expectation is that the gap is not fixed. Across the stack, he sees roughly 100x remaining in price-performance improvements. He did not attribute that to one breakthrough. He pointed to harness changes, model changes, kernels, hardware specialization, and co-design. Data centers are already moving in that direction, he argued, with more specialized chips and more deliberate matching of workloads to hardware. He expects local systems to follow.
He was cautious about advising someone to buy a $5,000 box today. For experimenters, yes. For ordinary users, not yet. But within 18 months to two years, he expects products to exist that he could recommend more like an appliance: buy the box, run close-to-frontier models locally, stop paying for every token except through electricity. That was an expectation, not a claim that the market or hardware supply chain has already arrived there.
That expectation depends on another premise: most use cases will not need the most expensive model indefinitely. Cheema argued that AI use cases follow S-curves. Once a model is good enough for a task, additional intelligence has diminishing utility. Transcription was his example. A 10 trillion-parameter model reasoning for minutes is neither necessary nor acceptable for a low-latency transcription use case. Summarizing emails, creating to-do lists, and many consumer workflows have similar thresholds. In his view, the cloud will still matter for frontier scientific and highly complex tasks — curing diseases was his example — but most everyday tasks will eventually fall below the threshold where local systems are adequate.
He acknowledged uncertainty. The “fog of war,” borrowing another Karpathy phrase, is getting closer. He said he had been surprised by the jump in usefulness around Claude Code and Opus 4.5, especially after the Christmas period when many people returned to work and found that previously unreliable workflows had become possible. Some of that was model progress, and some was harness progress. His broader point was that even if the frontier keeps moving, the threshold for most local workloads can be crossed from below.
Benchmarks are the evidence mechanism for the 100x claim
Cheema’s price-performance thesis depends on measuring local AI more rigorously than the current public evidence base allows. He said the best sources at the moment are often Reddit and Twitter, where everyone reports different results. He praised the rise of “citizen scientists” using AI tools to experiment quickly, but said the downside is noise: people can misunderstand what they have measured, or be encouraged by an LLM into thinking they have made a breakthrough when the result is not useful.
His recurring example was extreme quantization. If someone runs a 1-bit version of a model, Cheema argued, they may be better off using a smaller model at higher quality. A social post claiming “Kimi on a MacBook” may hide the fact that the model was quantized to 1-bit, pruned, or configured to activate fewer experts than intended. It may run, but not at a useful quality point.
The slide he used for this section was blunt: “Real Local AI Benchmarks soonTM,” shown above photos of desktop hardware stacks. Cheema’s explanation was more specific than the slide. EXO plans to publish open local AI benchmarks to make these tradeoffs explicit. He said the company has a large amount of hardware specifically for this purpose and is already running benchmarks continuously. The planned benchmark site, which he said should arrive within about a month, would include thousands of results across hardware, models, quantizations, and pruning strategies.
The benchmarks, in Cheema’s framing, should not report only raw speed. He wants to pair tokens per second and prefill time with model quality and energy. “Intelligence per joule” was one proposed way to combine quality and energy, though he treated it as one useful metric rather than the only one. The useful output is a Pareto frontier: given a budget, what local setups offer the best combinations of quality, speed, cost, and energy?
For a $10,000 budget, for example, the frontier may show that GLM 5.1 delivers higher quality at about 20 tokens per second, while a smaller Gemma model delivers around 100 tokens per second. Neither is universally better. They occupy different points on the curve. A user who wants the strongest available open model may accept slower generation. A user who wants responsive everyday interaction may choose a smaller model with much higher token throughput.
The final question sharpened the same methodological point. An audience member asked about using automated research loops to optimize models for specific hardware, including approaches that load parts of a model from disk on a memory-constrained Mac. Cheema said he was cynical about some of that work. Auto-research tools are powerful, he said, but without scientific method they become a slot machine. A system may make changes that improve apparent speed while damaging model quality, and the user may not notice because the model still “runs.”
On disk-based inference, he was more direct: disk is too slow for the cases being discussed. Memory hierarchies are interesting in principle, and he allowed that exotic setups with many SSDs in RAID might make some expert-loading tricks worth exploring. There is research on predicting which expert will be needed next and loading it optimistically. But for local frontier inference, he argued, the more cost-effective path is to solve the memory problem in memory, not to make a MacBook stream a frontier model from disk.
The right local machine may be heterogeneous, not a bigger Mac or a bigger GPU
A repeated tension in the discussion was whether Apple Silicon is actually good local AI hardware. An audience member described the practical frustration: large models may fit into a Mac’s unified memory, but inference can be slow, hot, and power-hungry. By contrast, an RTX 5090-class GPU can deliver much higher inference speed, though with far less VRAM.
Alex Cheema agreed with the premise. A Mac gives a large unified memory pool, but not the same compute or bandwidth profile as an RTX GPU. He described an RTX 5090 as having 32GB of VRAM, GDDR7 memory, and close to 1.5–2TB/s memory bandwidth. A 512GB Mac Studio, by contrast, has more than 10 times the memory but around 800GB/s memory bandwidth and roughly 10 times less compute in his comparison.
His answer was not “Macs are better” or “GPUs are better.” It was that local inference wants both kinds of hardware, because different phases and model components have different bottlenecks.
Prefill wants compute. Decode wants memory bandwidth and enough memory capacity. Dense models and sparse mixture-of-experts models can have different optimal placements. A Mac may be appropriate when a huge model must fit into a large memory pool; an RTX may be better when a smaller dense model can fit into fast VRAM and run at high speed. Cheema said the most cost-effective local setup today may involve combining devices and splitting the workload more granularly than simply placing the whole model on one machine.
That is why EXO is working on heterogeneous execution. Cheema described the goal as making it easy to connect additional accelerator hardware to a Mac; as an example of the kind of result they are working toward, he said to imagine plugging an RTX directly into a Mac and getting something like a 3x speedup on large models. On stage, the concrete heterogeneous example used an NVIDIA Spark paired with a MacBook. Cheema said the Spark had more compute, while the MacBook had higher memory bandwidth: he gave the MacBook at 546 GB/s and the Spark at 273 GB/s, while saying the Spark had about four times more compute. The ratio difference, he said, was about 12x.
| Device role in Cheema’s example | Hardware characteristic he emphasized | Inference phase |
|---|---|---|
| NVIDIA Spark | About four times more compute than the MacBook in his comparison; 273 GB/s memory bandwidth. | Prefill |
| MacBook | 546 GB/s memory bandwidth in his comparison, roughly twice the Spark’s bandwidth. | Decode |
The intended split was to run prefill on the Spark and decode on the MacBook. That creates its own systems problem: the KV cache produced during prefill must be streamed to the MacBook so decode can read it on every pass. In the demo setup, the devices were connected over 10 gigabit Ethernet through an adapter because the MacBook lacked an Ethernet port. Cheema said the communication must be fast enough to overlap data transfer with computation; otherwise prefill finishes, the system waits for KV cache transfer, and decode starts late.
The live heterogeneous demo had Wi-Fi and setup issues, which were visible in the exchange on stage. The EXO interface shown during the demo displayed a pipeline with “Ryuichi’s MacBook Pro” and an NVIDIA GPU node processing a request to summarize two papers. Cheema described the “after” case as prefill on the Spark and decode on the MacBook. In the specific large-prompt example, he said it was about 2x faster end to end. In a later run, an audience member reported about 7 seconds for a single-paper MacBook-only run; the paired run on a similar paper came in at 4.8 seconds. Cheema stressed that this kind of split does not help small prompts — “hello” will not get faster — but becomes more valuable as prompt size grows, because prefill time grows sharply with prompt length for most model architectures.
EXO’s software claim is that clustering should become an app-level primitive
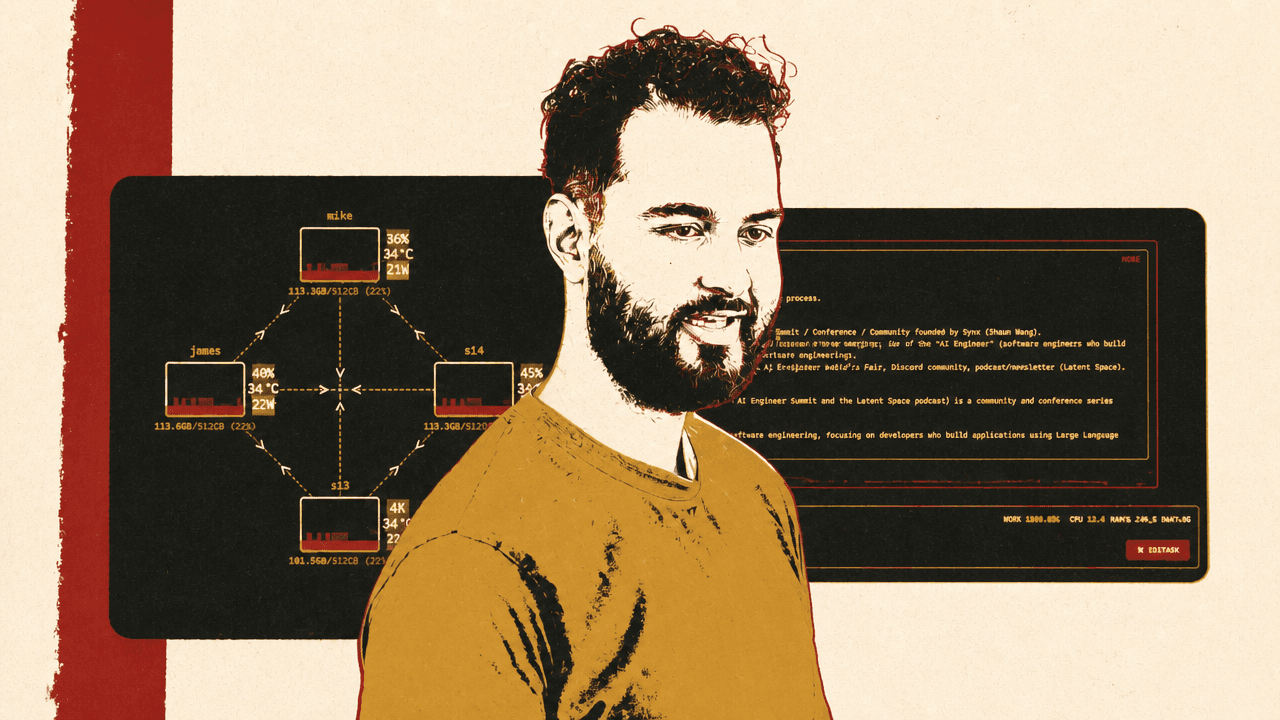
The hardware argument depends on software that can make a messy local cluster usable. Alex Cheema described EXO as a background app installed on every device. It automatically discovers other devices, runs as a mesh network, exposes an HTTP API endpoint on each device, and figures out how to distribute models across whatever hardware is available.
The stage setup used four Mac Studios connected by Thunderbolt 5. The EXO dashboard shown on screen made the software claim concrete: a topology view displayed four nodes labeled “mike,” “james,” “s13,” and “x14,” with lines between them, temperature and memory readouts on each node, and an instances panel showing a GLM 5.1 model spread across all four machines. Each node showed roughly 112GB of memory in use, and the instance was marked ready to chat. The visible model label was “GLM-5.1-9B-FP4-0B,” and the hardware pane indicated tensor execution, MLX, and RDMA.
Cheema was not merely arguing that four machines could be manually configured to run a model. He was showing the cluster as a live object: nodes, links, model instances, memory use, and hardware status all visible in one dashboard. The surrounding claim was that clustering should become an app-level primitive rather than a networking project for the user.
The critical systems detail was EXO’s recent RDMA integration. Before that work, Cheema said node-to-node latency between Macs over consumer macOS was around 300 microseconds. That is small in ordinary application terms but enormous for tensor-parallel inference. If a model has 60 layers, as Cheema said is the case for Kimi or DeepSeek, and tensor parallelism requires two synchronizations per layer, then generating one token requires about 120 synchronizations. At 0.3 milliseconds each, roughly 40 milliseconds can be lost just to communication. Under those conditions, clustering may let a model fit in memory, but it does not make it faster.
With RDMA over Thunderbolt 5, he said latency dropped by roughly 100x into single-digit microseconds. That changes the scaling behavior: instead of tens of milliseconds in communication per token, communication can be under a millisecond. In Cheema’s account, that is the difference between clustering as a memory workaround and clustering as a path to real speedup.
The GLM 5.1 demo used the 4-bit version because the model had just come out and the full version would have been around 1.5TB. The quantized model was still described as almost 400GB. EXO had converted it to MLX the day before; Cheema noted that this was easier than supporting an entirely new architecture because GLM-5 support already existed and GLM 5.1 was another checkpoint of the same architecture. By contrast, he said Gemma 4 required more work because its architecture, including KV cache behavior, differed from previous models.
He prompted the model with “tell me about ai.engineer.” The dashboard showed all four machines at high utilization, which Cheema used to illustrate tensor parallelism across the RDMA-connected Macs. The response identified AI Engineer as a community, conference series, and media brand founded by Swyx.
He then launched a much smaller Qwen model on two of the machines. The dashboard showed the smaller model running at about 77 tokens per second, with utilization rising on the two selected nodes. The model quality was not the focus; the operational behavior was. Different model instances could be loaded onto different subsets of the cluster, and EXO could route execution across them.
The ad hoc device-joining demo illustrated both the promise and the messiness of local clusters. An audience member connected an M4 MacBook by Thunderbolt. The MacBook joined the cluster over TCP/IP, but not with RDMA enabled; Cheema said Thunderbolt 5 is required for RDMA, and enabling it on macOS currently requires booting into recovery mode because Apple treats it as a developer-focused feature. The dashboard also warned about incompatible macOS versions. Cheema used that moment to explain that EXO uses event sourcing: each machine writes an append-only log, and a newly joined node replays the cluster history to catch up. The reason, he said, is consistency in a dynamic environment where devices can sleep, power off, or disconnect while requests are in progress. A local cluster is not a fixed data-center rack; the software has to assume devices come and go.
Cloud batching is a real advantage, but Cheema sees three ways it may weaken
One obvious objection to local inference is batching. Cloud providers serve many users at once and can batch requests to use hardware efficiently. A single local user cannot normally do that. Alex Cheema accepted the economic point: if cloud unit economics are 100x better because of batching, local inference looks structurally disadvantaged.
The batching slide made the objection simple. Without batching, four inferences run as separate sequential blocks. With batching, the same four inferences are stacked and scheduled together. Cheema paired that with a roofline-style chart showing how increasing batch size can move a workload from bandwidth-bound toward better hardware utilization. For cloud GPUs serving many users, that is a real economies-of-scale advantage.
Cheema argued that the disadvantage may not remain as large as it looks, for three reasons: multi-agent systems, test-time scaling, and personalized model weights through continual learning.
Multi-agent systems create local parallelism even for one user. Cheema cited Grok 4.20 as an example, showing a diagram with multiple agents collaborating. If one user request fans out into several agents running in parallel, the effective local batch size is no longer one. It might be eight. On hardware like a Mac, he suggested, that can be enough to improve utilization materially.
Test-time scaling is a related form of parallelism. Instead of generating one answer, a system can generate many and choose the best. Cheema described best-of-N as the simplest case: run 10 passes, then use a verifier or scorer to pick. More sophisticated search methods include beam search and lookahead search. He showed a Hugging Face research figure comparing methods and a chart where scaling the number of generations improved MATH-500 accuracy for a small model. His takeaway was that there appears to be a scaling law where smaller models plus more test-time compute can match larger models on some tasks.
That matters for local inference because test-time search turns one user request into many model calls, again raising effective batch size. It also changes the hardware tradeoff: a smaller model running repeatedly may be preferable to a single pass through a much larger model, depending on latency, quality, and energy.
The third possibility, continual learning, cuts the other way: it could make cloud batching worse. Cheema described a possible future where inference and training blur. Instead of a model being fixed at inference time, each user’s model weights update based on their own data and usage. That could solve some long-context and memory problems by reducing dependence on stuffing everything into a prompt; the model itself changes.
But if each user has different weights, batching across users becomes difficult or impossible. In the extreme case where the whole model changes per user, the cloud cannot batch those requests together. Cheema said that would make local inference roughly 10x better relative to the cloud, depending on how the technique lands. If only a small part of the model changes, the effect may be smaller.
If the whole model is changing, then you can't batch at all.


A home cluster may not stay idle if the agent is useful enough
An audience member asked about utilization: how much does Cheema actually use such a local cluster, and could idle local compute be rented out?
Alex Cheema said his own utilization is still low. He continues to use a lot of Opus and Grok. Local models are useful for some things, and that set is growing, but they are not yet a full replacement for his own work.
He separated two future possibilities. One is a distributed network of idle local clusters. If EXO eventually had a million clusters, and many were underused, the aggregate idle compute could be large. Cheema imagined spare capacity going toward volunteer science problems or other inference-heavy workloads. He said inference is relatively easy to distribute in a data-parallel way if each node already has the capability to run the model locally; the system does not need to cluster machines over the internet for a single request.
That was explicitly conditional on scale. Cheema was not pitching idle-compute rental as an immediate EXO product. He said it becomes interesting only if many people already own capable local AI hardware for their own reasons.
The other possibility is that utilization rises because local agents become useful enough to run continuously. If a local system has frontier-level performance, access to all the user’s data, and no per-token cost beyond electricity, Cheema said he would want it running all the time: scanning the internet for relevant information, thinking about EXO’s direction, watching for things he should know, and acting as a 24/7 companion or assistant. In that world, there may be less idle compute than expected.
The comparison to crypto mining came up naturally. An audience member suggested that renting out home AI hardware may follow the same path as home GPU mining: initially attractive, then outcompeted by large-scale operators. Cheema said some incentives are different. Local AI hardware has direct private value: privacy, control, and local access. Crypto mining hardware, by contrast, simply runs at 100% for financial return.
He was skeptical of projects whose main pitch is paying users to rent out hardware. He argued they often operate at the wrong abstraction layer. Instead of renting raw hardware, a network should rent higher-level outputs: tokens, tasks, or even task completion with relaxed latency requirements. A 24-hour task API, for example, could tolerate retries and variable latency and might use cheap spare capacity effectively. But Cheema emphasized that this only becomes interesting at scale. A hundred Macs is negligible. A gigawatt-equivalent distributed network would be a different matter.