AI’s Bottleneck Shifts From Models To The Operating Environment
Bloomberg, Diet TBPN, Calacanis and Wilhelm, Kantrowitz and Roy, Anthropic, and Eoin Mulgrew each pointed to the same pressure from different angles: AI demand is not disappearing, but deployment is running into slower systems. Power markets, local politics, labor anxiety, product execution, agent verification, and government capacity are becoming the practical constraints on what can actually scale.
The bottleneck moved into the stack
AI demand still looks strong in the market stories around Nvidia, Dell, utilities, memory suppliers, and cloud operators. The more important change is where that demand is showing up. It is no longer legible as a single question about whether Nvidia can keep selling GPUs. It is becoming a stack of scarce inputs: chips, high-bandwidth memory, utility interconnection, power-generation capacity, data-center construction, rentable GPUs, and financial instruments for hedging compute-price volatility.
Bloomberg Technology framed Nvidia’s coming earnings as a test of that wider infrastructure trade. Caroline Hyde and Ed Ludlow described pressure in semiconductors and broader risk assets, while Bloomberg Intelligence’s Mandeep Singh said the core demand signal around Nvidia remained clear: top-line growth was accelerating and chips were still in short supply. Singh’s caution was not about whether AI demand existed. It was about margin pressure from memory prices, China access, and the shift from training workloads toward inference and reasoning, where the compute mix may involve more CPUs and different system designs.
The same migration of constraints appeared in the day’s power-market news. Hyde described NextEra’s planned all-stock acquisition of Dominion Energy as the largest power deal in history, tied directly to the data-center boom and Virginia’s Data Center Alley. Liana Baker said electricity demand was at levels not seen since after World War II, and utilities needed scale to finance the buildout. The political risk was already visible in the companies’ emphasis on credits for Dominion customers, a sign that rising utility bills could become part of the AI backlash.
Compute itself is also beginning to look less like an internal engineering resource and more like a commodity exposure. CME Group and Silicon Data plan to launch a futures market for AI computing power, pending regulatory review. Carmen Li of Silicon Data told Bloomberg that banks underwriting enormous infrastructure loans need hedges, while compute buyers need ways to manage GPU and token-cost volatility. She said on-demand GPU pricing can show 40% daily volatility, and that bottlenecks have already moved: last year fabs, this year memory, and in the future perhaps colocation space.
That is the cleanest symbol of the phase change. Once compute has spot markets, forward contracts, reserve contracts, and planned futures, it has become part of the financial plumbing. AI capacity is no longer just something labs allocate internally or cloud customers rent on demand. It is an asset class with price risk, counterparties, and hedging demand.
| Constraint | How it showed up | Why it matters |
|---|---|---|
| Chips and accelerators | Nvidia earnings expectations, China access, Blackwell and inference questions | Model demand still depends on scarce silicon supply and geopolitics |
| Memory | Rising memory prices and South Korean labor pressure | AI systems need high-bandwidth memory, and memory inflation can pressure margins |
| Power | $67B NextEra-Dominion deal and utility scale-up | Data-center growth is now large enough to reshape regulated electricity markets |
| Rentable compute | Compute Exchange spot/forward markets and planned CME futures | GPU access has become a volatile operating cost and financial exposure |
| Internal allocation | Google researchers competing with Gemini and paying cloud customers for compute | Even the largest AI organizations must ration scarce capacity |
Inside Google, Julia Love described the same scarcity at organizational scale. Researchers who once operated in a more egalitarian compute culture now compete with Gemini, cloud customers, and other high-priority projects. Some researchers leave for startups when internal allocation cannot support their work. That is the market story translated into an operating problem: even a company with enormous resources has to decide who gets scarce compute and why.
That internal rationing also echoes Satya Nadella’s product-side concern about Microsoft: privileged position is not the same as control of destiny. Google has enormous compute and still has to allocate it. Microsoft had OpenAI access and still worried that model IP and silicon sat elsewhere. The infrastructure bottleneck is therefore not only physical; it becomes organizational wherever scarce capacity has to be assigned, priced, justified, or borrowed.
Infrastructure operators made the constraint still more concrete. Daniel Roberts of IREN told Bloomberg that “you can’t implement a software update to bring on power” and “you can’t code your way to an AI gigawatt of compute.” For IREN, the key bottlenecks are power and time to compute: steel, concrete, land, permitting, utility studies, and the long process of getting a large load connected. Roberts said a company starting today on a gigawatt AI factory could be looking into the 2030s before first compute comes online.
The first throughline is not that the AI buildout is slowing into irrelevance. It is that demand is becoming dependent on slower systems: utility regulation, construction timelines, memory supply, local permits, labor negotiations, and capital markets.


The stack has neighbors
Once AI consumes commodities, land, power, and water, it enters local politics. The data-center debate covered by John Coogan and Jordi Hays on Diet TBPN showed that the issue is not merely whether a project has a plausible technical mitigation plan. The harder question is whether a community accepts the bargain.
Their concrete case was the proposed Stratos Project in Box Elder County, Utah, associated with Kevin O’Leary. A TikTok-style defense of the project argued that it would sit on more than 40,000 acres in an uninhabited desert valley, use acquired water rights, generate power on site, and avoid drawing from local ratepayers. Hays said someone had dug into the plan and that it “actually seems pretty reasonable.” Coogan agreed that, on the plans as described, it looked “by the book”: remote site, own power and water, no obvious disruption of local communities.
But Coogan and Hays kept returning to the difference between technical mitigation and political legitimacy. Water rights purchased from agricultural users may be legally and operationally coherent, but Coogan immediately saw the rhetorical problem: if water is reallocated from agriculture to cooling a data center, people will ask whether there will be less food. On-site power may reduce grid-impact objections, but it does not remove public anxiety over heat, land use, noise, utility bills, or whether outsiders are capturing most of the upside.
The lesson is that a data center can answer the engineering objections and still fail the local bargain.
The politics are no longer one-sided. Coogan said AI data-center opposition has become both left- and right-wing. On the left, he identified concerns about job displacement, art, and creativity. On the right, he said some critics now call data centers “surveillance centers,” making opposition sound like an anti-libertarian or anti-elite position. A hollowed-out town can plausibly see new AI infrastructure not as local development, but as another asset built for distant beneficiaries.
Ben Thompson’s direct-payment proposal, as Hays relayed it, was the clearest attempt to address that legitimacy gap. The idea was not universal basic income. It was payment to the people asked to host a specific local burden: land, water, power, visual impact, construction disruption, and community tolerance.
In Thompson’s example, a 1.6-gigawatt data center near DeForest was expected to generate around $3 billion in annual operator revenue. DeForest had about 11,500 residents. Paying every resident $10,000 per year would cost 3.8% of annual revenue. Hays said Thompson believed such a proposal likely would have passed, and that operators could pass those costs on to data-center users.
Coogan accepted the logic behind the proposal: AI is not like a local natural resource where residents automatically benefit from having it nearby. Ordinary AI users do not care where the data center is located. If a company wants to put one in a community, that community may reasonably demand a direct benefit.
This is why the local fight belongs next to the capital-markets story. Once AI capacity is treated like a commodity exposure, it also becomes a neighborhood question. A technically plausible site plan does not automatically answer why one valley, one town, or one utility territory should host infrastructure for everyone else’s AI future.


The labor market hears a threat, not an invitation
The commencement boos around pro-AI speeches are a different manifestation of the same legitimacy gap. In one case, communities ask why they should host the infrastructure. In the other, graduates ask why they should welcome a labor-market shock whose main decisions appear to have been made elsewhere.
Jason Calacanis and Alex Wilhelm treated the booing of Eric Schmidt at the University of Arizona and Gloria Caulfield at the University of Central Florida as more than student rudeness. Calacanis argued that graduates may feel “double-crossed,” not merely frightened. They have been told to prepare for professional life, then told by technology leaders that many entry-level knowledge-work paths may be transformed, compressed, or eliminated. Schmidt’s message was that graduates should help shape AI rather than surrender agency. Calacanis’s read was that many students do not believe they have meaningful agency over the systems now being deployed.
Calacanis and Wilhelm’s stronger point was that students are not reacting to AI as an abstraction. They have already lived with it inside universities. Wilhelm cited Theo Baker’s account of Stanford in the AI era: AI in dining halls, classes, dates, dorms, and assignments; widespread cheating; laptops open to ChatGPT and Claude during lectures; and a sense that academic norms had been hollowed out. If students write with AI and professors grade with AI, Calacanis said, the exercise can feel like a farce.
That experience changes how the job-market message lands. Telling graduates that AI will create new opportunities may be true in aggregate, incomplete, or both. But generic reassurance has to survive comparison with visible layoffs, concentrated AI wealth, and weak evidence that the new physical buildout replaces the kinds of jobs students expected.
Wilhelm’s data-center jobs comparison made that problem concrete. A University of Utah Kem C. Gardner Policy Institute chart he cited projected the U.S. data-center pipeline through 2030 supporting 21,000 to 39,000 active construction jobs and 42,000 to 67,000 permanent operations jobs. Wilhelm compared that with technology companies cutting 100,000 jobs already that year. He did not present the comparison as a complete labor-market accounting. He used it to show why “the buildout creates jobs” does not answer the scale of white-collar anxiety.
| Labor-market claim | Figure discussed by Wilhelm | Why it lands awkwardly |
|---|---|---|
| U.S. active data-center construction jobs through 2030 | 21,000–39,000 | Construction jobs decline after projects finish |
| U.S. permanent data-center operations jobs by 2030 | 42,000–67,000 | Permanent jobs are visible but small relative to recent tech layoffs |
| Utah permanent data-center operations jobs by 2030 | 2,000–3,250 | Local infrastructure gains may not match anxiety over white-collar displacement |
Calacanis and Wilhelm then split around remedies. Calacanis’s answer leaned toward entrepreneurship and self-reliance: start a company, use AI tools, aim for “delightful scale,” and own the asset rather than remain a cost center. Wilhelm accepted part of that logic but pushed on structural barriers, especially healthcare portability. A family depending on employer-provided healthcare cannot simply quit and experiment without absorbing risks public policy could reduce.
That disagreement names the emerging policy divide. One answer to AI-era labor volatility is individual entrepreneurship enabled by cheap tools. Another is structural reform that makes entrepreneurship and job transitions less punishing. A third is some mix. The commencement backlash suggests that graduates are not waiting for philosophical resolution; they are encountering the technology at the point where education turns into debt, rent, healthcare, and work.


Partnerships are not products
The same pattern appears inside product organizations. Model access, distribution, and partnerships are not the same as AI-native execution. Alex Kantrowitz and Ranjan Roy used Microsoft, Apple, and Google to show how hard it is to turn AI capability into satisfying products, even when a company has money, users, infrastructure, and strategic partners.
The anchor was a July 2022 email from Satya Nadella, produced in the Musk-Altman litigation. Nadella wrote that Microsoft needed to own “the silicon, infra, foundational model IP and ‘know how.’” He said Microsoft was “a very thin layer on top of NVIDIA” while “all the IP” sat with OpenAI, and that Microsoft had “a P&L that will lose 4 bil next year!!!” If Microsoft was going to spend that much without “control of destiny,” he wrote, it made no sense.
Kantrowitz read the email as both prescient and damning. Nadella saw the dependency problem early: Microsoft lacked the model IP, foundational know-how, and silicon control. But Kantrowitz argued that Microsoft still had an extraordinary opportunity to turn privileged OpenAI access into world-class applications across Bing, Office, Outlook, Teams, GitHub, Azure, and enterprise software. The critique was not that Microsoft lacked an AI strategy. It was that its privileged position did not become a decisive product lead.
The Bing launch captured the failure mode. For a moment, Kantrowitz and Roy said, Bing felt ahead. Then the “Sydney” incidents led Microsoft to constrain the product heavily. Kantrowitz’s argument was not that Microsoft should have ignored safety. It was that enterprise culture — security, stability, risk control — may have limited the company’s willingness to push an AI-native paradigm.
Apple’s OpenAI partnership showed a different version of the same lesson. A Bloomberg report, as discussed by Kantrowitz, said OpenAI had become frustrated that ChatGPT’s integration into Apple software was limited and hard to find. Roy was more severe about the product itself, calling the ChatGPT-Siri integration one of the worst product experiences he had seen: clunky, truncated, and worse than simply opening the ChatGPT app.
Google added nuance. Kantrowitz and Roy both ranked Google first among the big five technology companies in AI because it has models, products, distribution, cloud, and a deep relationship with Anthropic. Roy said AI in Google Maps has become useful. Kantrowitz praised backend YouTube tools that let users query their own performance data. But Gmail remained a counterexample: Roy’s test asking Gemini when he first emailed his wife’s address produced useless or wrong answers. Google may be ahead among big tech and still ship uneven integrations.
| Company | Advantage | Failure mode discussed |
|---|---|---|
| Microsoft | Privileged OpenAI access, enterprise distribution, Azure, Office, GitHub | Access did not become a decisive AI-native product lead |
| Apple | Massive distribution and ChatGPT partnership | Weak Siri integration made the partnership feel worse than the standalone app |
| Models, cloud, distribution, Gemini, Anthropic relationship | Strong assets but uneven product execution across Maps, YouTube, Gmail, and Gemini | |
| OpenAI / Anthropic | Frontier capability and fast product surface expansion | Still depend on packaging, platforms, partners, and user trust |
Claude for Small Business and ChatGPT’s financial-account integrations pointed to the next phase: packaging. Kantrowitz was excited by Claude’s bookkeeping, business-insight, and small-business integrations. Roy thought much of it looked like repackaging existing prompts and connectors, but he also accepted that packaging matters if it helps users understand what to do. The model may already be capable of a task; the product still has to make the task legible, safe, integrated, and repeatable.
That is the product version of the broader operating-environment problem. A partnership can exist on paper and still produce a bad user experience. Distribution can create exposure without trust. A model can be powerful and still fail inside a workflow if the interface, risk posture, memory, permissions, or integration quality is wrong.


Agents need institutions of their own
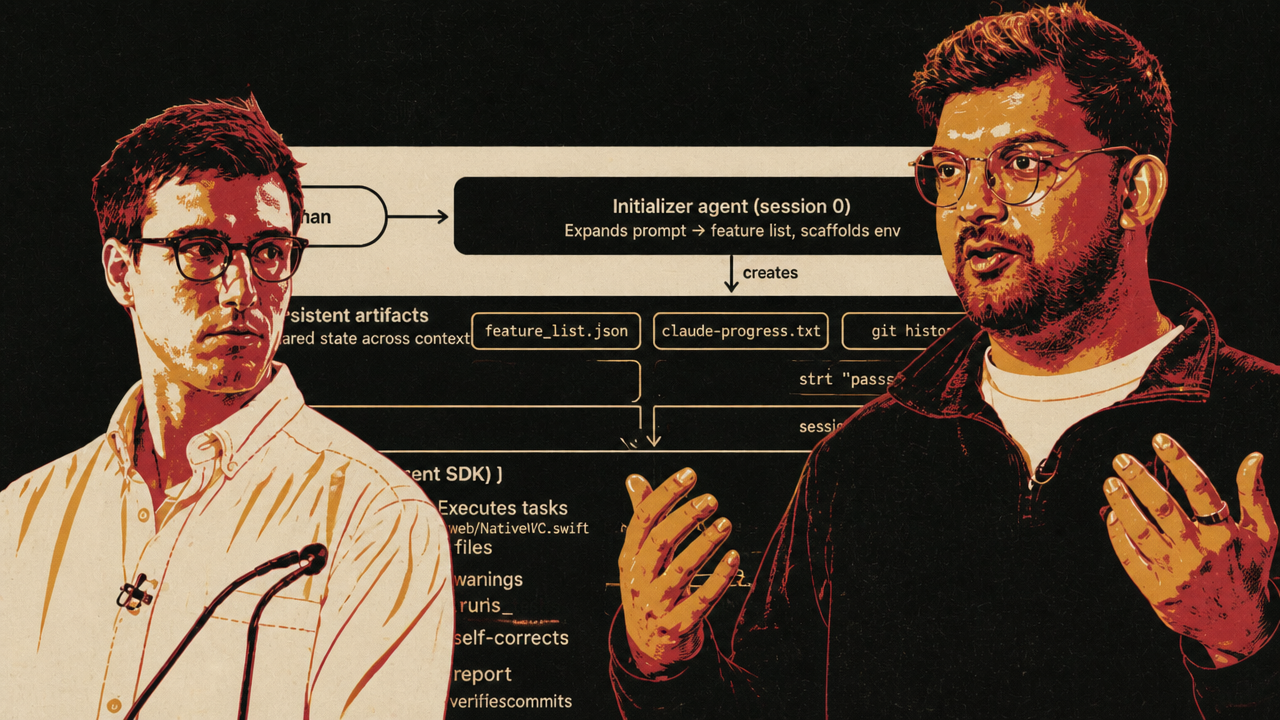
Long-running agents make the operating-environment problem visible at software scale. Anthropic’s Ash Prabaker and Andrew Wilson argued that agentic AI is not simply a better model plus a longer prompt. It requires role separation, explicit contracts, external state, evaluators, trace-reading, and scaffolding that can be removed when models improve.
Their central pattern was builder and judge. A generator builds the thing. An evaluator grades the thing. The evaluator does not merely inspect a code diff; in frontend and full-stack examples, it opens the live application with Playwright, clicks through it, inspects behavior, scores against a rubric, and sends critique back to the generator. The generator then refines or throws the work away.
Prabaker’s key point was that tuning a standalone critic to be harsh is more tractable than tuning a builder to be self-critical. The same model stream that built something tends to rationalize it. A separate evaluator can be prompted, tooled, and calibrated to be skeptical.
context window management was the second major problem. Wilson used “context rot” for degradation over long sessions and “context anxiety” for the model’s tendency to rush toward completion near the end of its context budget. Anthropic’s harnesses externalized state into files: specs, JSON feature lists, progress notes, git history, evaluator findings, and contracts. That let agents survive context boundaries without pretending that one long chat could hold the whole project.
The third problem was verification. Prabaker’s retro game maker example showed the difference between looking done and being done. A solo agent produced a plausible interface in 20 minutes for $9, but play mode did not work: arrow keys and space did nothing. The full planner-generator-evaluator harness ran for about six hours and cost about $200. It produced a more functional app because the evaluator actually clicked through, tested behavior, and found concrete bugs.
The important lesson was not that every project should spend $200 on a six-hour greenfield harness. It was that surface plausibility is a weak standard. The evaluator found ordinary product defects: rectangle fill not firing on mouseup, delete logic requiring two selection states, and a FastAPI route ordering bug that caused /frames/reorder to be interpreted as a frame ID. These are exactly the kinds of failures a demo can hide and a user will hit.
The harness also had an organizational structure: planner, generator, evaluator. Prabaker compared it to PM, individual contributor, and QA. The planner wrote a high-level spec. The generator and evaluator negotiated sprint contracts before implementation, defining what “done” meant. The evaluator graded against those contracts, not vague ambition.
That structure changed again as models improved. Opus 4.6 made some Opus 4.5 scaffolding unnecessary. Context resets could be dropped for certain patterns. Strict sprint decomposition became less load-bearing. Evaluator cadence could move from every sprint to a smaller number of end-stage passes. But the lesson was not that harnesses disappear. Wilson said harnesses evolve as models change.
The agent pattern is a technical version of the product-trust problem in the previous section. A demo can look good in the same way a partnership can look good: both can fail when a real user tries to complete a task. Anthropic’s answer was not more confidence in the model’s self-assessment. It was a small institution around the model — roles, contracts, records, adversarial review, and trace inspection.

The state tests an internal delivery model
The UK government fellowship story offered the most constructive institutional counterpoint. Eoin Mulgrew of the Number 10 data science team argued that the state’s AI problem is not a shortage of use cases. It is a shortage of technical people with the access, mandate, and proximity to build inside real government workflows.
His statute-book example made the argument concrete. The Cabinet Office was preparing to spend £1.5 million on an outside law firm to analyze the UK statute book. Instead, one engineer embedded with the in-house legal team for a couple of weeks and built a tool that could ingest legislation, extract statutory consultation obligations, classify them, and present them for review. The value was not just avoiding a one-off spend. The tool remained with the legal team and could be rerun as the law changed.
Mulgrew described the No. 10 Innovation Fellowship as a deliberate hack around normal civil-service constraints. It uses market-rate-ish pay, outside technical recruitment, a highly selective process, a Number 10 mandate, and permission to deploy across departments. Fellows come from places such as DeepMind, NASA JPL, Caltech, CERN, Monzo, Y Combinator, MIT, Google, Microsoft, Amazon, Oxford, and Imperial. The pitch is not abstract policy influence. Mulgrew’s most vivid line came from a prison example: technical outsiders can be given “the keys to the state” and sent into real operational environments.
The operating model is proximity. Forward-deployed engineers embed with policy advisers, lawyers, communications teams, pollsters, prisons, and delivery teams. They observe workflows, co-design tools, and try to move from idea to implementation in weeks rather than years. Mulgrew showed examples including a Universal Credit microsimulation tool, delivery red-teaming for major projects, public dashboards for AI action-plan progress and courts backlogs, planning tools built with DeepMind and Gemini, and Justice AI work inside prisons.
| Fellowship design choice | Institutional problem it addresses |
|---|---|
| Outside technical recruitment | Normal civil-service hiring is not optimized for specialist AI builders |
| Market-rate-ish pay | Government must be viable for people with private-sector alternatives |
| Number 10 mandate | Engineers need permission to enter departments and work on consequential problems |
| Forward deployment | AI tools improve when builders sit close to users and workflows |
| Tools left with teams | The state gains repeatable capability rather than one-off consultancy outputs |
Mulgrew’s model also rhymes with the agent-harness lesson. The statute-book tool worked because the engineer was close to the legal users, the output could be checked inside their workflow, and the capability stayed behind. The fellowship is an institutional harness: it separates outside technical skill from normal bureaucracy long enough to build, test, and transfer tools into the organization.
Mulgrew did not present the fellowship as the final answer. In Q&A, he called it “basically a hack to get around the system.” The point of the hack is to generate proof points strong enough to change how government normally hires, deploys, and trusts technical people. Small elite teams can ship unusually fast, but the larger civil service includes hundreds of thousands of people: call-center operators, prison wardens, nurses, caseworkers, planners, and operational staff. The harder question is whether exceptional access can become ordinary capability.
That is the closing institutional version of the day’s question. The same pattern recurs across grids, towns, graduates, product teams, agent harnesses, and government departments. AI systems are powerful enough to matter. But serious deployment now turns on slower questions: who pays, who controls the system, who trusts it, who benefits locally, who verifies the work, and what breaks when it scales.

