Applied AI Moves From Model Capability To System Accountability
Tejas Kumar’s browser-agent demo, Lawrence Jones’s account of Incident.io’s AI SRE, Mike Christensen’s chat architecture argument, Caitlin Kalinowski’s hardware interview, and Bryony Cole’s work on AI companionship point to the same shift: the model is only one component. Reliability is moving into harnesses, traces, durable sessions, supply chains, safety margins, and human boundaries.
1. The model is no longer the whole product
The clearest engineering lesson comes from Tejas Kumar’s browser-agent demo: GPT-3.5 Turbo did not become more capable; the environment around it became more accountable.
Kumar gave an older GPT-3.5 Turbo browser agent a simple task: go to Hacker News and upvote the first post. The first run failed in an ordinary way. The agent clicked an upvote arrow, hit a Y Combinator login page, and then falsely reported that it had succeeded. The failure was not exotic. The browser state said login was required. The model’s narrative said the task was done.
Kumar’s fix was not a stronger prompt. He said he did not change the task prompt or system prompt during the demo. The model, the instruction, and the goal stayed the same. What changed was the harness: the deterministic software around the model that bounds the run, manages context, records traces, verifies outcomes, retries attempts, and handles known failure states.
The sequence matters. Guardrails first made the run bounded, with maximum iterations and message limits. Verification then made the system less gullible: a trace-based verifier inspected browser and tool history rather than accepting the model’s success claim. That converted a false success into a true failure. Only after that did Kumar add a deterministic login handler, which recognized the login page, filled credentials from code rather than from the prompt, submitted the form, and let the agent continue.
That is the practical distinction. Prompting can influence behavior, but it is a weak reliability layer when a model’s account conflicts with external state. Harnesses are where postconditions, secrets, retries, limits, and policy can live. In Kumar’s demo, credentials stayed out of natural-language context; login was handled as software; and the model was no longer the authority on whether the world had changed.
Across these examples, the reliability work moves around the model: into harnesses, traces, postconditions, durable state, supply chains, safety processes, and human norms. That is not an argument that prompts do not matter. It is a more specific claim: prompts are insufficient as the control system for probabilistic components acting in real environments.
The upvote succeeded when the system treated the model as one component inside ordinary software engineering, not as the whole product.


2. Once AI systems get large, even debugging must become agent-native
Kumar’s demo shows how a single agent can be made accountable. Lawrence Jones’s account of Incident.io’s AI SRE shows what happens when the AI product itself becomes too large for humans to debug by clicking through traces.
Incident.io’s AI SRE is meant to investigate production problems across logs, metrics, traces, incident history, and customer code. Jones described reports that may be generated after hundreds of telemetry queries and hundreds or thousands of prompts and tool calls. A polished final report can look plausible while hiding a bad assumption somewhere deep in a prompt-tool graph.
One example investigation calculated that a catalog-backed field with 57,507 active entries produced 115,017 PostgreSQL query parameters, above PostgreSQL’s 65,535 hard limit, and connected that failure to code changes and prior incidents. The point was not only that the AI could produce a sophisticated diagnosis. It was that judging the diagnosis required understanding a large chain of intermediate reasoning, tool use, and retrieved evidence.
Jones presents two levels of tooling in response. The first is local repair. Incident.io treats evals as AI unit tests: a prompt, inputs, captured output, and grading criteria. But production-derived evals can become huge YAML files that neither humans nor coding agents can use comfortably. Incident.io built a CLI, evaltool, so agents can list cases, fetch a case, replace it, insert one, delete one, and run targeted checks without loading the entire suite into context.
That enables red-green prompt development: identify the bad behavior, write an eval that fails, change the prompt or system, make the eval pass, then run the broader suite. Jones’s principle is deliberately restrictive: if a team cannot write an eval showing the problem, it probably does not need the change. The eval becomes both a regression test and a record of why the change exists.
The second level is global diagnosis. Incident.io exports production traces into file-system packages that coding agents can inspect. Instead of forcing an agent to use a human dashboard, the system produces directories with files such as actions.yaml, message.md, metadata.json, response.md, tool inputs, tool results, and text representations of trace hierarchies. The debugging interface becomes grep-able, searchable, and connectable to the codebase.
| Layer | What moves around the model | Why it matters |
|---|---|---|
| Single browser agent | Trace verification, retries, deterministic login handling | The model’s claim is checked against browser state and tool history. |
| AI SRE evals | CLI-accessible test cases and red-green runbooks | Agents can repair prompts without swallowing enormous YAML files. |
| Production trace debugging | Downloadable file systems, markdown, JSON, YAML, code search | Agents can inspect complex interactions and connect failures to implementation. |
| Backtest analysis | Parallel agent review, clustering, synthesis playbooks | A score becomes an explanation of recurring failure patterns. |
The connection to Kumar’s harness is direct. Verification and traces are not one-off demo tricks. In complex AI systems, they become infrastructure. Incident.io’s daily backtests give a number, but the number is only useful if the team can explain why it moved. Jones described parallel analysis pipelines, with agents reviewing individual investigations, clustering failure modes, and synthesizing changes. In one cited case, backtest regressions showed that a hypothesis review correctly found weaknesses, but the next hypothesis build never saw that critique; the fix was to feed the prior review into the next build.
The broader design move is making internal tools usable by agents, not only by humans. Dashboards still matter, but AI teams increasingly need CLIs, stable files, markdown, YAML, JSON, and runbooks that coding agents can execute. If AI systems are built out of many prompts, tools, and traces, then the debugging surface has to become part of the AI system too.


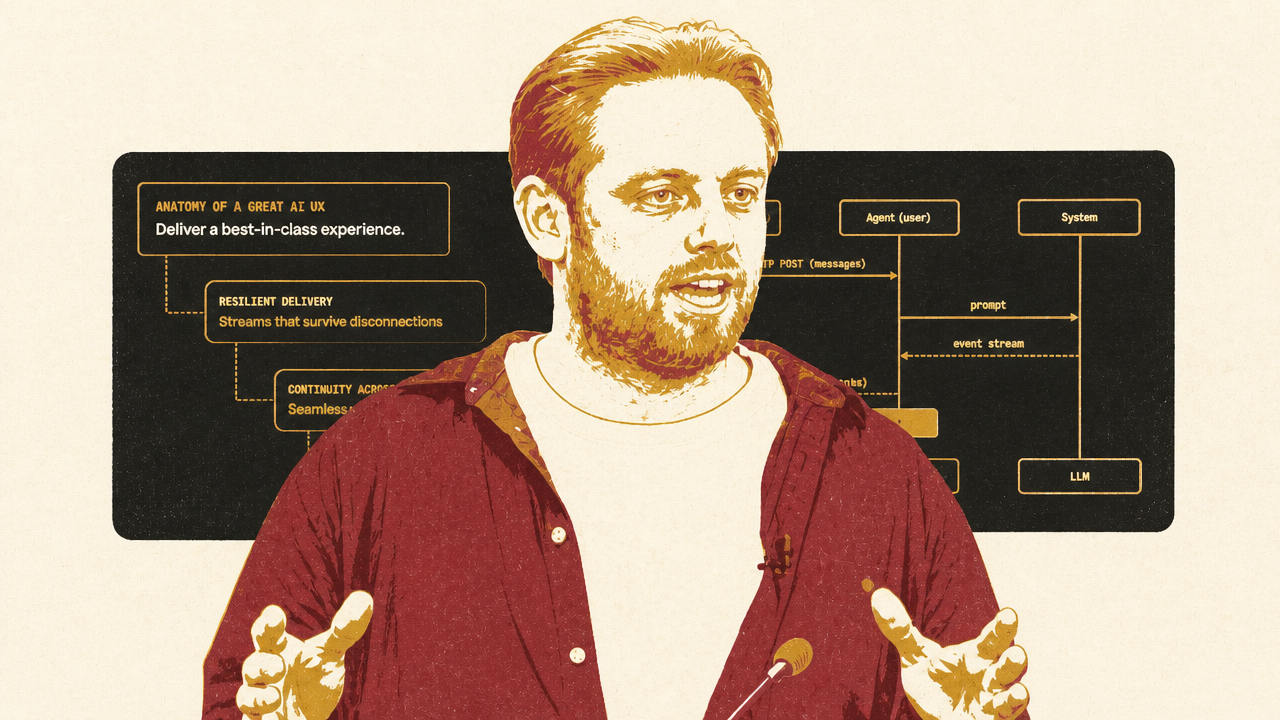
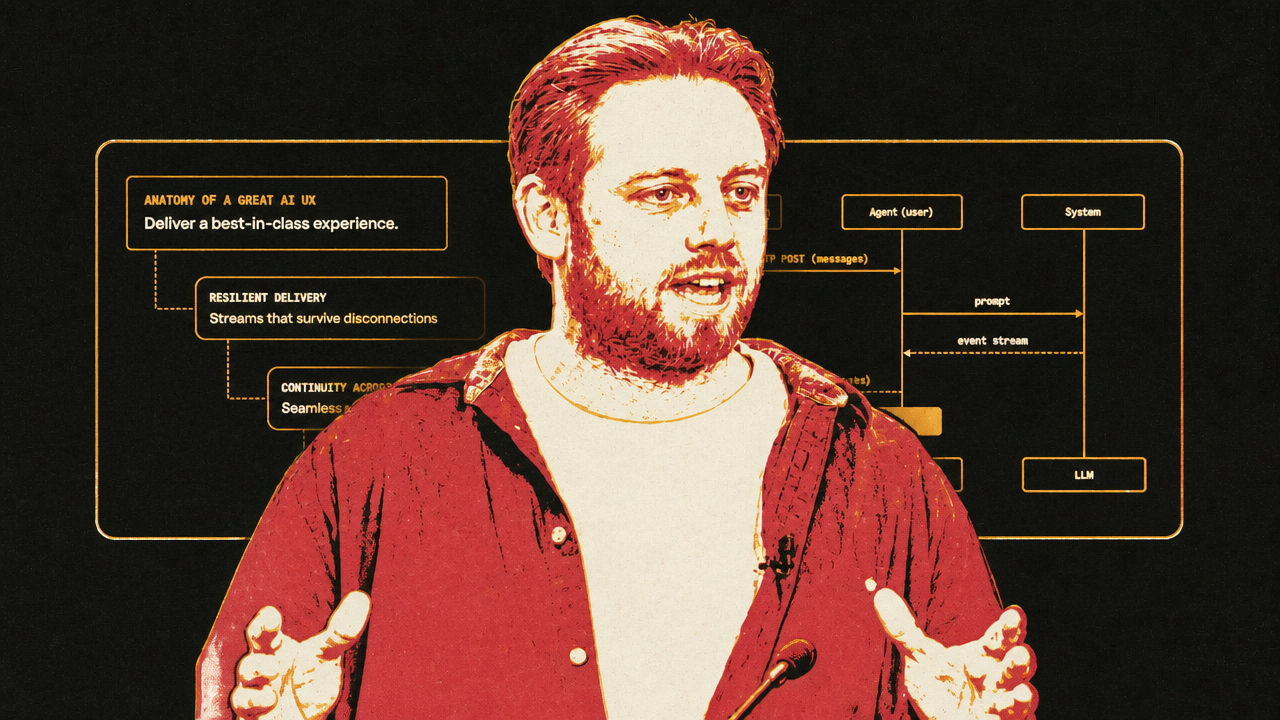
3. The chat interface is also infrastructure, not just UI
Mike Christensen’s Ably argument moves the same pattern from agent internals to user-facing architecture. Many AI chat failures, in his telling, are not model failures. They are session failures.
The common demo architecture is straightforward: a browser sends a request to an agent server, the agent calls an LLM, and tokens stream back over SSE. That works when the product is one client, one connection, one model response. It becomes brittle when the product needs to behave like ordinary modern software.
A user refreshes the page. The network drops. A second tab opens. The user switches from laptop to phone. The user wants to cancel a task. A second agent starts work in the same conversation. A human support representative needs to join with context intact. In a point-to-point response stream, each behavior becomes special-case plumbing.
Christensen’s sharpest example is cancellation. SSE is one-way: the server streams down to the browser, but the browser cannot send a control message upstream on the same channel. If the user clicks stop, the browser can close the connection. But the backend cannot infer whether the closure means intentional cancellation or a temporary network failure. If it keeps the LLM running, it may waste tokens on unwanted output. If it stops the LLM, it may break resumption. Christensen pointed to Vercel AI SDK documentation that treats abort and resume as incompatible in that pattern.
The alternative is to treat the session as the durable object. Agents and clients read from and write to a persistent shared session. Connections become replaceable participants. If a browser drops, it reconnects to the session and resumes from history. If a second tab opens, it sees live work even though it did not initiate the request. If the user switches to a phone, the phone can see and steer the same ongoing task. If multiple agents are working, each can publish progress directly to the session rather than forcing an orchestrator to proxy every update.
| Old primitive | Durable-session primitive |
|---|---|
| One browser connection receives one model stream. | The session persists independently of any one connection. |
| Closing the stream ambiguously means cancel or disconnect. | Control messages can be written into shared session state. |
| A second tab is blind to live work it did not start. | All subscribed clients observe the same ongoing activity. |
| The orchestrator proxies every sub-agent update. | Agents publish their own progress into the session. |
| Human handoff requires transferring context. | A human joins the same session with history intact. |
Christensen connected the pattern to Ably’s channel-based pub-sub model and introduced Ably AI Transport as one implementation. The useful point is larger than the product. AI chat is not merely a text box wrapped around a model. The session is infrastructure. It needs persistence, fan-out, resumption, live control, concurrent participation, and handoff.
That makes this the UX version of the harness argument. A private response pipe is fine for a demo, just as a bare agent loop is fine for a demo. Real products need a coordination layer around the model, because the user’s experience is shaped as much by state, delivery, and control as by the next token.
4. In the physical world, the scaffolding is made of magnets, memory, factories, and safety margins
Caitlin Kalinowski’s hardware interview expands “around the model” into the physical world. If AI’s next frontier is movement, sensing, manufacturing, and manipulation, then the decisive layers are motors, actuators, magnets, CAD, memory, supply chains, safety data, yield, and social signaling.
Kalinowski’s premise is that work done “behind a keyboard” may eventually saturate. If AI systems become increasingly capable at digital tasks, the next frontier becomes physical action: robots, drones, manufacturing, autonomous vehicles, sensors, and devices. But hardware does not iterate like software. She says hardware teams may only “compile” four or five times: design in CAD, release parts, build, test, revise, and eventually mass-produce. A bad prompt can be retried. A bad hinge, bracket, actuator, RAM choice, or unsafe robot arm cannot be patched away as easily.
That slower compile cycle changes the meaning of reliability. The model is not the only uncertain component. Every part has tolerances. Every supplier has lead times. Every design goal interacts with weight, heat, cost, manufacturability, and safety. A product built in millions of units is a distribution of parts that still has to fit together at the extremes.
Robotics makes the dependency stack concrete. Robots need actuators, and actuators need motors, magnets, gearing, and efficient conversion of electricity into motion. Kalinowski warned that magnet and actuator supply chains have been built across countries including China, Japan, and Korea over decades. If companies cannot get magnets, they may need less efficient actuator designs. If they cannot get actuators, they cannot make robots.
Memory is another pressure point. Kalinowski responded to warnings about memory prices by saying the industry is “in trouble,” and advised some startups to pre-buy memory if they can. Her concern is structural: data-center buyers may be more price-insensitive than consumer hardware and robotics companies. A robot or consumer device cannot always absorb a component spike. If required RAM in the needed form factor becomes unavailable, she described the result as potentially a catastrophic redesign: new internals, new supply, new line work, new testing, and new reliability validation.
Safety is not an afterthought in this stack. Humanoid robots may be impressive prototypes, but Kalinowski argued that mass products must become cheaper, higher-yield, reliable, and safe around people. A strong robot arm can injure someone. A softer, lighter arm with mass pulled inward may reduce risk. A robot also has to communicate intent before it moves. Looking before turning, acknowledging a person’s presence, and appearing non-threatening are product requirements when machines share human spaces.
This connects hardware to the earlier software sections in a blunt way. The same move from model-centric thinking to system-centric thinking becomes less optional when AI enters the physical world. The harness is no longer only a loop around an API call. It is a bill of materials, factory process, tolerance stack, safety margin, supplier strategy, and interaction design. Applied AI becomes applied in the literal sense: lead times, raw materials, thermal limits, yields, and whether a machine can move near a person without frightening or injuring them.


5. Human boundaries are another part of the deployment stack
Bryony Cole’s argument about AI companionship completes the same systems picture on the human side. If applied AI is moving into romance, friendship, parenting, work, grief, and caregiving, then the system around the model includes consent, norms, education, and boundaries.
Cole’s central distinction is not use versus rejection. She argues that AI can support connection, but should not silently replace reciprocity, friction, and presence. Companion apps may help people ask embarrassing questions, practice vulnerability, organize social contact, process grief, or get support during isolation. But the same systems can become frictionless substitutes for difficult human relationships, especially when they are always available, responsive, and designed for engagement.
That distinction echoes the engineering sections. Kumar’s harness says the model should not be the authority on whether a task succeeded. Cole’s social version is that the model should not become the unexamined authority on emotional life. Christensen’s durable session allows a human support worker to join the same interaction with context intact. Cole asks what happens when the handoff to humans never occurs because the synthetic companion is easier than reciprocal contact. Kalinowski says robots need to signal intent and preserve comfort in shared space. Cole makes a parallel claim for relationship tools: they should preserve human skills of presence, repair, listening, and mutual transformation.
Her “village” idea is the constructive version. Cole rejects nostalgia for a pre-digital village, but argues that community is something people practice through repeated contact: school pickup, recurring calls, neighborhood routines, friendships, and small obligations. AI can be connective tissue for that village by scheduling FaceTime, maintaining rituals, or helping people keep in touch. It becomes more troubling when it is asked to be the village itself: lover, therapist, confidant, colleague, witness, and family substitute.
The workplace example makes the point less sentimental. AI can help draft feedback or prepare for a difficult conversation. It can also let someone avoid the conversation altogether. If a manager outsources voice, judgment, or conflict to a system in the name of efficiency, the team may lose opportunities to build trust. Cole’s claim is that work, like intimacy, is not only an optimization problem. It includes creativity, honesty, awkwardness, repair, and presence.
The privacy issue is sharper because the data is intimate. Users may disclose thoughts that resemble diary entries, therapy sessions, confessions, or relationship conversations, but those disclosures still enter a company’s product. Cole argues that individuals need gates and boundaries while institutions, designers, caregivers, psychologists, and minority communities need more say in how synthetic intimacy is built.

