Agent-Native Clouds Need Faster Primitives, Not New Ones



Railway founder Jake Cooper argues that software infrastructure does not need to abandon its old primitives for agents, but must make them much faster, cheaper, safer and more observable. In a wide-ranging interview with swyx and Alessio, Cooper lays out Railway’s attempt to build an agent-native cloud through own-metal data centers, production forks, progressive rollouts and deployment loops that assume thousands of concurrent software-producing actors rather than one human pushing a pull request.
Railway’s bet is that agents need old primitives under new pressure
Jake Cooper describes Railway as “the easiest way to ship anything”: a place where a user can go to a canvas, or talk with Claude, and ask to deploy a Postgres instance, a GitHub repository, or a piece of code. The product goal is not only deployment, but continuing application evolution: cloning environments, forking “into a parallel universe,” copying production data and services, validating changes, and collapsing them back without reconstructing a separate staging world by hand.
The agent-era version of that thesis is not that agents require a fundamentally different stack. Cooper’s sharper claim is that agents need the same basic primitives humans needed — network, compute, storage, orchestration, version control, observability — but at a scale and compression that breaks existing assumptions.
People will say that “Agents need a whole new infrastructure layer” — they actually need basically the exact same thing. Network, compute, storage. Just much, MUCH faster.


The difference, in Cooper’s account, is speed and multiplicity. Humans have needed feature flags, logs, metrics, traces, version control, filesystems, networks, databases, and safe rollout paths. Agents need those capabilities while running thousands of concurrent attempts, testing changes incrementally, snapshotting filesystems, coordinating with other agents, and knowing when to ask a human to intervene. What looks like a new category of infrastructure may be ordinary infrastructure under a much harsher concurrency and feedback-loop constraint.
That changes where bottlenecks appear. Railway does not use Kubernetes as its core orchestration substrate, Cooper said, because it wants higher-order control over where workloads land. Agents make that control more important: memory reuse, placement, and efficient orchestration become cost-structure issues when workloads fan out. Existing components all the way down the stack may melt under the compressed workload profile: orchestration needs to be “massively better than kube,” networking likely needs something better than Envoy, and systems such as etcd may fail under the coordination load. The implication, as Cooper framed it, is not a single replacement product, but a cloud architecture built to swap pieces out whenever the next bottleneck emerges.
Shawn Wang framed Railway’s existing branching, fast spin-up, and orchestration work as “pre-work” that happened to match what agents want. Cooper agreed, but resisted the idea that the needs are alien. Agents want to version things, test changes incrementally, query what happened at a specific point in time, inspect traces and logs, write and snapshot files, and run compute near data. The workload is familiar. The operating envelope is not.
That pressure also reshapes the user interface. Railway’s canvas has been one of its recognizable product surfaces: a visual map of infrastructure blocks, services, and dependencies. Cooper now sees the canvas moving from input layer to output layer. Humans once used the canvas to manipulate infrastructure directly. In an agent-native workflow, agents use CLIs and APIs to make changes, while the canvas becomes a human control surface: what changed, what needs approval, what context is necessary to make a decision.
A CLI, in Cooper’s view, is well suited for agents precisely because it is often unfriendly to humans. A command-line tool with 40 arguments and 600 flags would be absurd for most human operators. For an agent, it is a rich set of handles. The more ways a model can query state, fetch dynamic information, and close the loop, the better. Railway therefore treats the CLI, dashboard, and telemetry as part of the same iteration system: where did the user or agent get stuck, what argument would remove friction, and how much did that change improve the happy path?
The internal rule Cooper stated is blunt: “You never, ever, ever want to be waiting on compute anymore. You always want to be waiting on intelligence.” If compute is the bottleneck, Railway treats it as a system failure to be destroyed. That view connects the product experience to the infrastructure buildout: deployment should feel instantaneous because any wait between intention and running software gives a new workflow room to emerge around the platform.
The business had to survive the free tier before it could absorb agent-era growth
Railway’s growth curve, discussed from Cooper’s public signup chart, did not follow the clean venture-capital fantasy of uninterrupted up-and-to-the-right expansion. Cooper described the first phase as a grind to the first 100 users. The early support link went to Discord; he kept notifications on and watched a second monitor so that if anyone entered, he could greet them immediately. That early phase created love for the product, but not a working business.
The free-tier era generated usage from “everybody under the sun,” including Discord bots, Reddit bots, phishing, trojans, and crypto miners. Building an open internet product taught the team how hostile that environment can be. The product had users and affection, but the economics were untenable: at one point Railway was losing roughly $500,000 per month, with about $50,000 per month in revenue, on a bank account of around $20 million.
Railway’s public signup chart, from a Jake Cooper post shown on-screen, carried the caption “Only two secrets in life: Don’t doubt your vibe; Don’t quit” and displayed a long flat-to-gradual period before a steep rise. Cooper treated the shape as evidence of different company phases rather than a simple growth morality tale: expansion phases where Railway added features to test use cases, followed by compaction phases where it stripped or refined the product for the users it wanted to serve.
Cooper described the free-tier correction as a forced rebuild. Railway wanted to reach as many people as possible because it sees software as an increasingly important medium of creation, especially as creation in the physical world has become harder. But the company could not continue subsidizing unrestricted free usage while trying to stay lean. It closed off the fully free user path for a period, rebuilt the business, and focused on making the economics work.
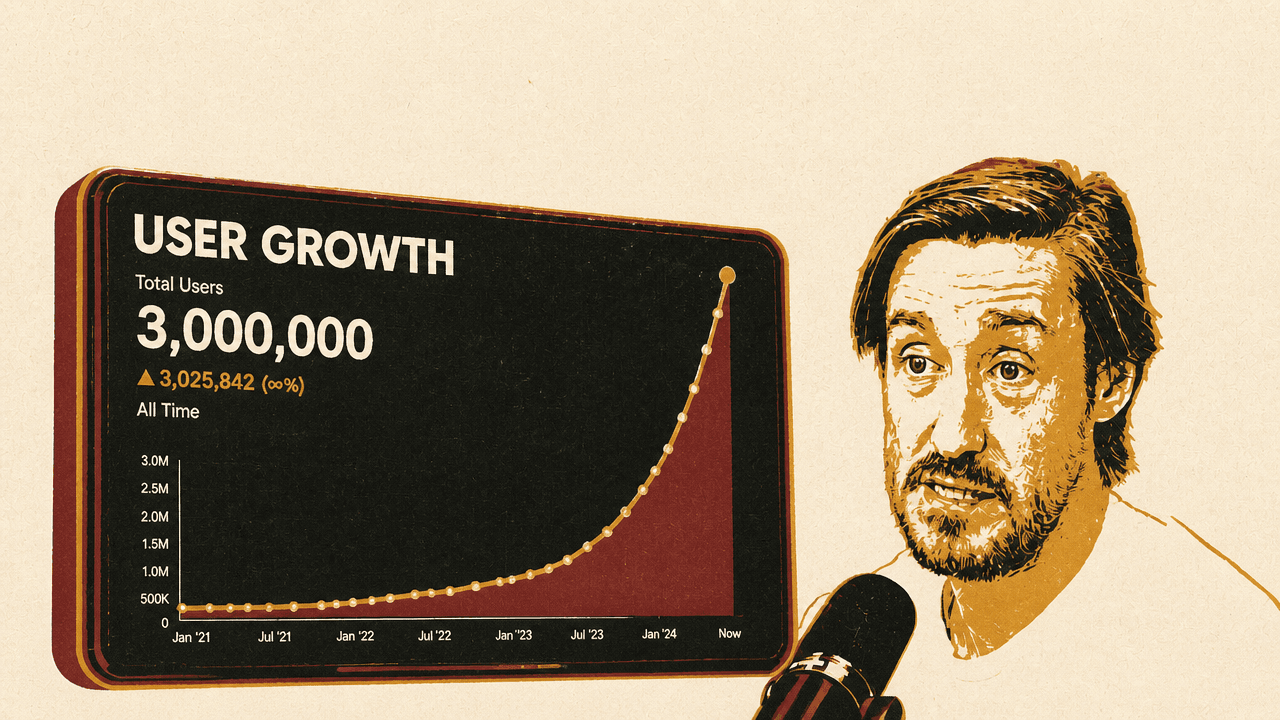
That lean operating model remains central. Railway has around 35 people and roughly 3 million users, Cooper said, adding about 100,000 users per week. When Alessio Fanelli asked whether the number was already 3 million, Cooper confirmed it. Wang’s reaction — “Holy shit” — captured the scale mismatch between team size and user count.
| Metric | Figure discussed |
|---|---|
| Team size | 35 people |
| Users | About 3 million |
| New users | About 100,000 per week |
| Free-tier-era loss | About $500,000 per month |
| Free-tier-era revenue | About $50,000 per month |
The growth pattern also reflects Railway’s mixed consumer and business character. Cooper pointed to seasonal divots around summer and winter, when users go on holiday. As Railway gets more business usage, weekday activation becomes more visible and the curve smooths.
The agentic top-of-funnel shift began more recently. Railway had prioritized agentic usage as a top-of-funnel motion and, over the previous six months, had “deeply prioritized” agents as a mechanism for building and deploying software. Cooper compared the shift to the dot-com era: even if there is a speculative run-up, and even if bottlenecks or economics break parts of the cycle, the long-run importance of the underlying change can still be real. His line of progression was assembly to C to C++ to JavaScript to words. If words become the dominant programming interface, the deployment platform has to close the loop from language to running software.
That dot-com analogy was not offered as a guarantee that every agent company works. Cooper’s point was narrower: if agents become the dominant species of software production over the next decade, then the infrastructure consequences must be addressed regardless of near-term hype. The questions become: what is the inference cost of thousands of parallel agents; how is their compute made efficient; how do they coordinate; how do they version changes safely; and when do they raise their hand to ask a human instead of becoming an interrupt factory?
Owning metal is a margin strategy, a performance strategy, and a control strategy
Railway started on public clouds, but Cooper said the vast majority of its workloads now run on Railway’s own bare-metal data centers. The company still maintains cloud presence for bursting, but its long-run direction is own-metal. At one point, Railway reached 100% own-data-center usage on its dashboard before growth forced it back into cloud bursting while it added capacity.
The economics are the clearest reason. Railway’s payback period for buying metal, compared with renting equivalent capacity in the cloud, is about three months, assuming four years of depreciated hardware. That is the kind of ratio that changes what a platform can afford to offer. On Railway-owned metal, Cooper said margins are around 70%, which lets the company subsidize cloud bursting during periods when demand outruns installed capacity.
Cooper’s data-center description was intentionally plain. You go to a provider such as Equinix, rent power and a cage, fill the cage with racks and servers, and connect internet. Then, as Shawn Wang joked, “they handle everything else,” and Cooper corrected: “you just handle everything else.” That “everything else” is the platform’s operational burden: procurement, network design, workload placement, hardware failures, capacity planning, migration, and reliability.
Capacity planning became acute when Railway’s growth exceeded the quota available from an upstream cloud provider. At the start of the year, Railway became compute constrained because one upstream provider could not provide quota fast enough and the hardware was slower. Cooper spent a weekend rebuilding Railway’s network overlay so it could straddle five clouds: Oracle, AWS, Railway’s own infrastructure, GCP, and another provider. That let Railway rent capacity where available and compact workloads back onto its own metal as space and power came online.
The company’s model is therefore hybrid by necessity, but not by indifference. Cooper wants to avoid being compute constrained. Cloud bursting is the release valve; own-metal is the margin engine. If revenue can scale as fast as compute, and if the platform keeps making build-and-deploy loops easier, then the business becomes partly a capital deployment problem: how quickly can Railway acquire and install servers, how much cash should it use, what debt should it take, and where does venture capital fit?
Cooper distinguished “data center debt” from the generic negative perception of venture debt. Railway can borrow against hardware, with debt secured by the servers themselves. He described the terms as prime plus a spread, with refinancing possible as rates change. His broader financing argument is that venture capital should not be the hammer for every problem. Equity is expensive if the company improves over time; founders should ask what unfair advantage each financing source buys. Hardware-backed debt can make sense for servers in a way that venture capital may not.
The hardware market itself has become strange. Cooper said that after Railway’s last fundraise, the value of its servers rose enough — driven by RAM price increases — that the amount of money raised was less than cash in the bank plus server value. He also pointed to hyperscalers deploying enormous capital expenditures and suggested that if every person eventually runs dozens or hundreds of agents in parallel, even efficient systems will require vast compute buildouts.
The “data centers in space” exchange tested the edge of that infrastructure imagination. Cooper had posted skeptically about an NVIDIA-related Starcloud satellite claim, asking how that much heat would be dissipated in a vacuum. He clarified that he does not think space data centers are impossible, only that he had not seen anyone show the heat-dissipation solution. The exchange mattered because it exposed Cooper’s operating mode: he is willing to consider ambitious infrastructure, but wants the physical bottleneck named and solved.
Railway’s own bottleneck work goes deep. Cooper had been patching Railway’s fork of the Linux kernel during the week of the recording, related to a storage layer for agentic work. It was not an upstream patch, at least not yet. For him, that is continuous with the product thesis: if the user experience requires changes at the kernel, network, storage, or orchestration layer, Railway should go there.
Safe agentic deployment requires production forks, not trust in the agent
Cooper is not a believer in “AI SRE” if that means giving an agent direct authority over production without safe primitives. He has become a deep believer in AI as the dominant way software will be authored, but he remains skeptical of agentic operations unless the infrastructure can make failure survivable.
His warning was concrete: if an AI SRE is unleashed on production infrastructure without safe ways to copy volumes, fork services, protect databases, and test close to production, “it’s going to nuke your production database.” In his view, the question is not whether observability vendors can suggest plausible fixes. Many of those fixes may be good. The problem is the last 20% of complex long-tail situations, where approving a plausible change can create an incident.
Railway’s answer, as Cooper described the desired platform direction, is forked environments that remain as close to production as possible. He described an agent as a small actor inside the canvas that can decide it needs to copy one service and another service to test a hypothesis. Ideally it receives a read-only copy of production; PII is marked for transformation; databases are cloned or copy-on-write; and the agent validates the change near the actual production shape. The objective is to avoid staging drift, where a separate environment slowly stops matching production and therefore stops proving anything.
This is where Cooper’s earlier critique of stacked infrastructure entropy becomes operational. Many companies have Docker for local development, Kubernetes for production, scripts for provisioning, separate staging assumptions, and hand-managed glue. At scale, those differences slow developers and destabilize iteration. Railway wants to compress those layers into a platform where production-like forks are cheap, fast, and first-party.
That same principle governs rollout. Railway uses progressive rollouts internally and Cooper expects agents to need the same class of tools: feature flags, shadow traffic, blast-radius control, and staged exposure. His argument is that large companies have repeatedly built such systems in-house because they become necessary at scale. In the agent era, the need arrives earlier because small teams and even individual developers can generate changes at a rate previously associated with large organizations.
The incident discussion made this concrete. A Railway incident post said an issue affected around 3,000 users, where authenticated content may have been served to unauthenticated users. Cooper said the issue involved an upstream provider whose behavior did not match documented behavior, despite that provider having written the relevant RFC. Central Station surfaced early signs when users reported cache invalidation problems. Railway turned the feature off immediately, then published a writeup on impact, resolution, and prevention.
Cooper said Railway errs toward over-disclosure. One of the company’s four values is “honor,” and he framed the honorable response as notifying the widest set of potentially affected users rather than letting a provider appear to gaslight customers. The incident was not sent to the whole user base because progressive rollout limited the impact. That is the same infrastructure lesson again: the way to survive change is to make exposure incremental, observable, and reversible.
Central Station is Railway’s internal system for making that possible at user scale. It aggregates feedback, support, and other user signals into clusters. If an incident is brewing, Railway can identify how many users are affected, break off a focused discussion, and route it to people with the relevant expertise. Instead of choosing the right Slack or Discord channel and hoping the right person sees it, the system dynamically clusters context and routes it. Cooper said Railway knows, for example, which four people are close to networking; when a networking cluster appears, the system can narrow the path to them.
Railway’s public Station page displayed 75,743 threads and 2,868,206 developers. Railway’s stats page displayed real-time totals for users, services, deploys, requests, and logs. Cooper said Railway exposes those stats in real time and even has a JSON path for them. This is part of a broader “build in public” posture: show the scale, publish incident reports, and continue improving the communication loop.
| Railway stats page metric | Displayed value |
|---|---|
| Users | 2,868,368 |
| Services | 9,038,970 |
| Deploys | 59,523,340 |
| Requests | 130,900,589,925 |
| Logs | 569,429,026,147 |
Cooper and Wang expect the pull request to lose its centrality
Cooper’s most aggressive engineering-management claim was that writing code by hand is now often the wrong use of time. After winter break, he told the company that if someone is writing code by hand, they are doing it wrong. The tools, in his view, are now good enough to move extremely quickly. Engineers should review and reconcile code rather than generate by hand code they already know how to write.
If you are writing code by hand, you are doing this wrong.
He did not mean architecture stops mattering. He argued the opposite: architectural patterns matter more now, because the engineer’s role shifts toward specifying, reviewing, reconciling, testing, and deciding. If an engineer knows how they would write something, they should ask an agent to write it and then reconcile until it looks like what they would have produced.
Railway is spending heavily on coding agents internally. Cooper said he personally was at about $25,000 of usage, with other power users across the company, though not every one of Railway’s 35 employees spends at that level. Asked what it would take to spend $3 million per month, he said most companies are now deployment-bound rather than idea-bound. CFOs may object first, because token bills become eye-watering, and inference costs must come down. But the business question should be tied to production impact: what percentage of tokens end up producing shipped software?
This is where Alessio Fanelli made the sales comparison: companies would spend a billion dollars on sales if they knew it returned two billion in revenue. Cooper agreed and suggested a naive but useful metric: the percentage of tokens that end up in production. If tokens accelerate roadmap items that become production value, the spend has a different meaning than raw experimentation cost.
Cooper’s internal experience is that agents have accelerated Railway’s roadmap. Some projects the team expected to ship over years now look shippable in months because agents allow rapid prototyping, validation, and test generation. He gave the example of building massive test benches with thousands of tests, describing such tests as effectively free to author now. That lets the team work out ideas for systems such as block storage or lower-level infrastructure without incrementally building every step in the old way.
He used an F1 driver analogy for who should receive the most expensive AI leverage. If someone is highly adept with the tools, it makes sense to put them in a $3 million car and point them in a direction. For others, the same spend may not make sense. The emerging pattern, in his telling, is not uniform automation across all engineers, but high-leverage operators using expensive tools to prototype, validate, and pull the roadmap forward.
Shawn Wang put the software-development-cycle claim more starkly: “the pull request is dying,” becoming something closer to a prompt request, and code review may also change if other systems are in place. Cooper agreed that pull requests are “definitely dying,” but his explanation tied that future to AI SRE, feature flags, and rollout infrastructure rather than to code generation alone. In this view, the unit of change is no longer just a human-authored diff waiting for a human reviewer. It becomes a prompt, a generated change, a spec, tests, observability, feature flags, staged rollout, and production feedback.
Cooper’s current mental model for reliable agentic development has three points: a clear spec defining the system, the code, and the tests. He acknowledged that this sounds obvious to any experienced engineer — an RFC, code, and tests — but argued that the three must reinforce one another. If the spec and tests match but the code does not, an agent can reconcile the code. If the code and tests drift from the spec, the loop exposes that. The fuzzy part and the discrete parts can correct each other.
The same logic applies to self-modifying infrastructure. Wang described running an agent with the Railway CLI, allowing it to provision new infrastructure and add it to itself. Cooper said he has set up a loop where the Railway CLI runs on something already deployed on Railway; the process is authenticated as the current box, can make changes, and then calls railway deploy to deploy itself. From there, the agent can spin up an instance, attach Postgres, modify its own environment, and either merge the working change or throw it away.
For Cooper, that is the shape of agentic infrastructure: self-replicating systems that iterate in production-like environments, generate a proposed new infrastructure state, ask whether it looks good, loop again if needed, and then apply.
Railway’s “new serverless” is full Linux, long-running state, and pay-for-what-you-use
When Wang placed Railway in the lineage of serverless, Cooper accepted a middle category rather than a clean label. In their framing, the old serverless promise was elastic execution without explicit provisioning. The agent-era need they discussed is different: stateful, long-running workflows or executions that can still spin up instantly and avoid paying for idle resources.
Railway’s thesis, from Cooper’s description, has always been: users need a computer, a box that speaks Linux, and they need to deploy anything on it. The platform should offer network, compute, and storage; allow workloads to run indefinitely; and charge only for what is used. He rejected the simple “servers are back” discourse as too blunt. The target is convergence: run something for a long time, but do not statically provision and pay for unused capacity.
That makes Railway neither pure functions-as-a-service nor traditional VM hosting. It wants the surface area of a general Linux machine with the operational loop of an instantaneous deployment platform. This is also why Cooper thinks the era of choosing a fixed AWS instance with four vCPU and 16 GB RAM will be badly stressed by agent workloads. If an agent workflow needs a thousand such machines, the static provisioning model becomes prohibitively expensive in his account. The atomic deploy unit must be cheaper, faster to start, and closer to pay-per-use.
Railway’s builder stack reflects this same pattern. It built Nixpacks, based on Nix, to infer dependencies from source code and build images. It later moved to Railpack, a builder developed from the ground up after lessons from building millions of apps with Nixpacks. A Railway blog page displayed the company’s explanation: Nixpacks worked well for 80% of users, but that still left 200,000 Railway users potentially encountering limitations daily, and Railway needed a major builder upgrade to scale from 1 million to 100 million users.
Cooper’s critique of Nix was pragmatic rather than ideological. Nix is effectively a stack of versioned binaries at specific slices in time. If users need different versions, package space can bloat, image size grows, and real-world workloads become difficult at scale. Wang noted that content addressing and caching should, in theory, optimize this. Cooper’s response was that at large enough scale, with enough users and a disparate enough set of machines, the problem resembles the challenge described in Meta’s XFaaS paper: hyperscale serverless systems often need to break out specific runtimes to control costs and utilization. Railway did not want to do that because “deploy anything” is part of its core promise.
Railway’s next direction, Cooper said, involves content-addressable filesystems that can lazy-load anything from any point and page it into memory. That idea also connects to his “cattle not pets” reversal. Traditional infrastructure culture says servers should be cattle, not pets: disposable, interchangeable, not lovingly maintained unique machines. Cooper’s hot take is that pets can return if there is a cloning machine for the pets. If every frame of a system can be snapshotted, lazily loaded, and restored, then a highly specific stateful environment becomes less dangerous.
In that world, the ceremony around Dockerfiles, Ansible scripts, and hermetically sealed DevOps lines can shrink. Instead of defining only a specific cut of a filesystem, the platform can snapshot the whole filesystem, lazily load it, iterate, and merge filesystem state into production if the result is correct. Cooper acknowledged this opens a large set of problems, but for Railway it is one of the directions that make safe agentic iteration possible.
Temporal sits adjacent to this workflow question. Cooper has used Temporal and its predecessor Cadence for nearly a decade, including at Uber, where Cadence powered long-running trip actions such as rides, Jump Bikes, scooters, and cars. Wang summarized the appeal as programming an entire user journey top-down as one function. Cooper agreed that this model is important for agents: a system needs to assign a task, know whether it is complete or incomplete, and move to the next task.
His critique is that Temporal is a jet engine. When it works and is understood, it works extremely well. But it requires the developer to hold the full workflow model in their head. Non-determinism issues can arise when workflow history replays. Large workflows become many-state machines full of conditionals, signals, queues, pre-commit hooks, and activities. Railway runs its deployment pipeline on Temporal and has built or begun building internal tools to test state machines and manage complexity. If Railway moved off, Cooper said, it would likely build its own workflow engine, though he cautioned that such a system should not be casually vibe-coded; it needs serious testing, including Jepsen-style validation.
Heroku is the ancestor, not the ambition
Railway is often placed in the “new Heroku” category, especially when companies look for a modern home for workloads they had been running on Heroku. Railway has a migration page aimed at Heroku users, and Cooper said the company has seen recognizable companies arrive saying they want to move workloads off Heroku. He described the experience as surreal: some customers were companies people would know, and Railway’s reaction was essentially, “you were running stuff on here?”
Cooper’s explanation for Heroku’s position was explicitly speculative. He said he could only guess at Salesforce’s internal reasons. His guess is focus. Salesforce’s business is CRM; Heroku is a compute business adjacent to that core. When a product is not the focus of the parent company, it competes internally for budget, resourcing, alignment, and mission. Cooper connected this to a broader lesson from large companies: abundant money can reduce the pressure to focus, and split focus dilutes products.
The source did not establish an official Heroku shutdown beyond the materials and discussion presented. Wang referred to “the Heroku official deprecation,” while Cooper said the public release was “a little bit odd” and described behind-the-scenes communications to some people suggesting they should close accounts because the service would be deprecated and removed over time. The point he drew from it was not an audit of Salesforce’s product plan, but a focus lesson: infrastructure platforms struggle when they are not central to the company operating them.
Heroku still matters to Cooper as a foundational developer experience. He and Wang both described learning from it. Before Heroku, deployment could mean dragging files to an FTP server or fighting through manual deploy setup. Heroku made deployment feel approachable. Railway is happy to “carry the torch” in that sense.
But Cooper does not want Railway to be merely the new Heroku. His stated ambition is broader: Railway should become the way people build and deploy software and, eventually, the way people monetize software. The familiar CI/CD loop remains part of the transition, but Railway is trying to build for primitives, agent fan-out, production forks, and instant iteration rather than copying Heroku’s exact workflow.
That refusal to copy extends to hyperscalers. Cooper said Railway has been deliberate about inventing its own infrastructure from scratch, informed by papers, while promising itself not to copy someone else’s homework. If Railway copied the hyperscalers, he argued, it would become them over time and lose. Its reason to exist is that the activation energy required to deploy something to production on hyperscalers is too high. Railway’s target is no friction between thought and running reality.
This is also why focus came up when Wang asked whether Railway might become a GPU provider. Cooper said there is a strong argument not to do that now, because a company is defined by what it does not do as much as by what it does. Railway is focused on the cloud and deployment loop, and he said Railway does not have current plans to do GPUs. At the same time, he believes Railway will “100%” do GPUs at some point in the future — not as a leaked roadmap item, he stressed, but because full vertical integration eventually requires FLOPs. For now, no GPUs; eventually, if the platform’s mission demands it, GPUs become another primitive.
Cooper’s founder model is obsession across layers, not balance
Cooper is a solo founder in a startup culture that often recommends co-founders, YC, and clear founder archetypes. He did not claim that solo founding is easier or generally preferable. Co-founders can make sense when ownership is segmented cleanly — for example, one technical person and one customer or business person. But two co-founders can be the worst number if there is no tiebreak. Even with a CEO, the arrangement is hard; without clear ownership, disagreements stall.
For Cooper, there is no balance among product, infrastructure, go-to-market, and company building. His answer was obsession across layers. He wants to understand how people think about the product from a market perspective and also whether a kernel-level change can prevent a user’s SSH connection from dropping. Railway’s product vision forces that breadth: the experience reaches from customer feedback routing to network overlays, filesystems, observability, support systems, and deployment primitives.
Writing is one of his tools for managing that breadth. He described taking weekends seriously when clarity is missing: disconnect, write about where the company is, where it should go, what problems it is solving, and what the route might be. When the vision is clear, he thinks it can make sense to work harder for a period. His personal rhythm is to work intensely from Monday through Friday, disconnect Saturday, and return Sunday afternoon for writing and weekly planning.
He also treats advice as provisional. Most advice, he said, should be digested and thrown out the window; if it is useful, it will return through experience. That applies to standard startup advice as much as to operating advice. His broader complaint is that society has made failure expensive, which discourages people from leaving established paths.
The founder theme connects back to Railway’s technical posture. Cooper said the work is fun precisely because the problems span so many levels: getting information from customers to support to the engineer who built a feature; making safe production iteration possible; giving users context in the dashboard; drilling down to infrastructure; managing orchestration as a real-time operating system versus a feedback control system. He has to “peel” himself away from technical problems to scale the company.
The result is a company that wants to be a new cloud without accepting the old cloud shape. It operates data centers, borrows against servers, patches kernels, builds internal incident-clustering systems, rethinks deployment workflows around agents, and argues that pull requests, static staging, and hand-authored code are all under pressure. The organizing principle is not novelty for its own sake. It is Cooper’s repeated standard: whatever has to be rebuilt to make deployment instantaneous and agent-safe is fair game.