Diffusion Models Generate Images Through Critical Instability Windows


Luca Ambrogioni argues that trained diffusion models generate images through brief instability windows rather than uniform step-by-step denoising. In a Microsoft Research generative modeling seminar, he links score dynamics, conditional entropy and statistical-physics phase transitions to show how low-frequency spatial modes soften at critical times, allowing noise to organize into coherent structure. Experiments on patch models, Fashion-MNIST and ImageNet models are presented as evidence that these critical windows govern both pattern formation and the timing of effective guidance.
Generation is concentrated at instability, not spread evenly across denoising
Luca Ambrogioni frames diffusion generation as a reverse stochastic dynamics whose most important events are not uniformly distributed over time. The standard setup starts with a forward diffusion process that gradually corrupts clean data into high-noise, approximately thermal white noise. A neural network is trained to reverse that corruption by learning the score function, the gradient of the log marginal density at each time. Once the score is known, the reverse SDE can be integrated to produce samples.
Ambrogioni’s focus is the structure of that reverse dynamics after training: whether it undergoes sharp dynamical events, and whether those events can be understood with the language of statistical physics. His claim is that trained diffusion models do not simply “denoise continuously” in a time-homogeneous way. They pass through specific instability points where the potential governing the reverse dynamics changes shape and the model makes generative decisions.
The account separates three related regimes. The first is finite-mode symmetry breaking: a model chooses among a finite set of alternatives, such as two prototypes or class-like branches. The second is an information-theoretic view: conditional entropy identifies when the reverse process is transmitting information about the final sample, and can be used as a clock for sampling. The third is spatial mode softening: in generalizing, translation-equivariant image models, the critical event is not a finite class choice but the instability of low-frequency spatial modes that seeds long-range pattern formation.
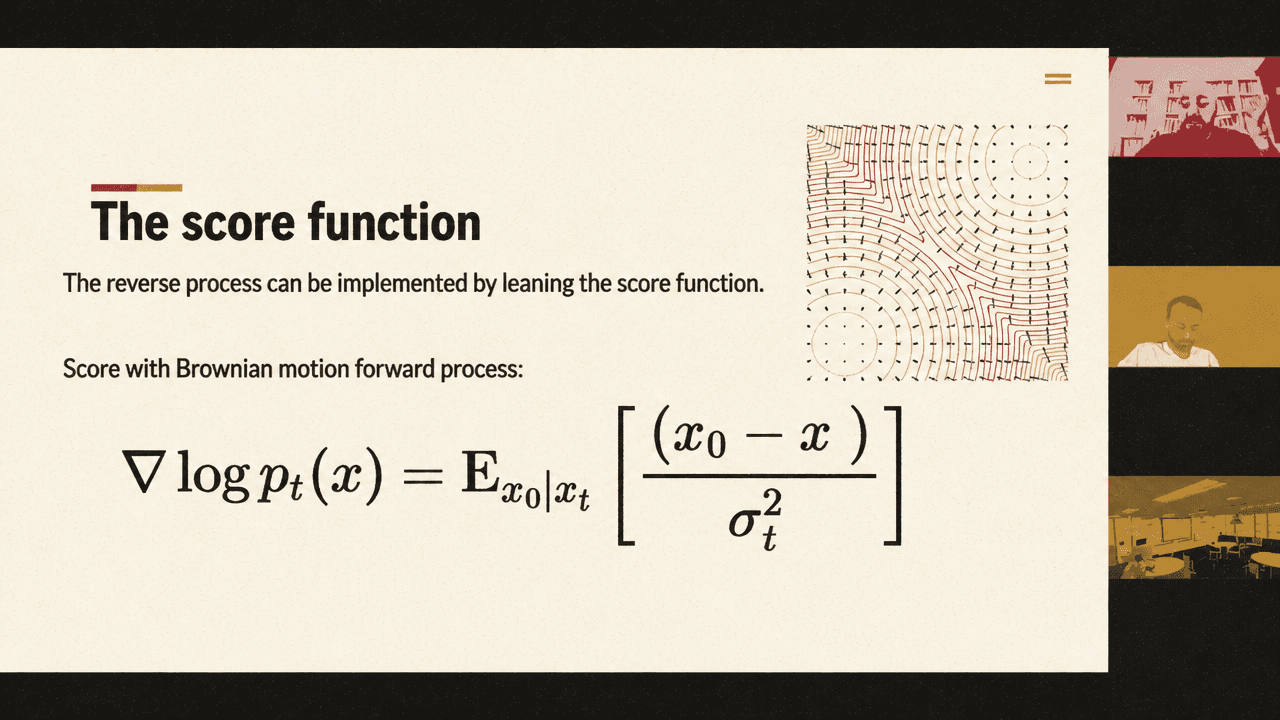
The score function is central because it can be written, for a Brownian forward process, as a posterior average over clean data points consistent with a noisy state:
Ambrogioni interprets this as an average over possible denoising vectors. If there were only one possible clean image, denoising would be trivial: subtract the noise. But for a noisy state that could have arisen from many different clean images, the score averages denoising directions that point toward different destinations. Those directions can cancel. He calls attention to “destructive interference” in this posterior average: when the model has not yet committed to a generative branch, many incompatible denoising directions coexist, and the macroscopic score vector contracts.
That contraction links the geometry of the score to information flow. When the score is decisive and long, sampling is close to deterministic because many perturbations are pulled back. When the model must choose among incompatible futures, the score contracts and noise can be amplified into a real generative decision.
The role of the score is not to make decisions itself, is to suppress invalid decisions.


The denoising score-matching loss follows from the same identity. During training, one can sample a clean data point, corrupt it, and use the one-sample empirical estimator as an unbiased estimate of the true score. The neural network cannot depend on the hidden clean image directly, so under squared error the nonparametric optimum is the conditional expectation: the true score. Ambrogioni stresses that the square loss is not arbitrary; it is the choice that makes the learned function converge to the posterior average in the nonparametric limit, in line with standard Bayesian decision-theoretic reasoning.
That training fact sets up the physical question. The learned score defines a potential-like landscape for the reverse dynamics. At very high noise, the marginal distribution is Gaussian, so the potential is simple and convex. At very low noise, the potential resembles the data distribution and typically has many minima. Somewhere between those limits, the landscape must acquire multiple basins. Ambrogioni’s argument is that this transition can be sharp: the quadratic barrier suppressing deviations vanishes, and small stochastic perturbations are amplified toward different modes.
Symmetry breaking turns noise into a generative choice
Luca Ambrogioni describes the first version of this theory as spontaneous symmetry breaking in generative diffusion models, developed with Gabriel Raya in the 2023 NeurIPS paper “Spontaneous symmetry breaking in generative diffusion models.” The physical analogy is a ferromagnet. At high temperature, a spherical magnet has no preferred direction and respects rotational symmetry at the level of an individual sample. At low temperature, it develops a magnetic field pointing in one direction. The laws remain symmetric at the ensemble level, but each realization has broken the symmetry.
In diffusion generation, the symmetry is the set of possible outcomes. At pure noise, the sample has not decided what it will become. As reverse dynamics proceeds, it may need to choose among alternatives — Ambrogioni’s example is a male or female face under an idealized dataset with equal representation. If the alternatives are exactly symmetric in the data, the ensemble can preserve the symmetry while each generated sample breaks it.
The corresponding potential changes from a single basin into multiple basins. In a two-mode cartoon, the symmetric state is stable at high noise, flat at the critical point, and unstable after the barrier disappears. In a real model there is usually not exact symmetry, so the branches may have unequal energies. Ambrogioni notes that in that case the transition is closer to a first-order transition rather than the idealized second-order symmetry-breaking case, but the qualitative dynamical phenomenon remains: a region of instability controls which branch the sample enters.
One empirical probe is late initialization. Instead of starting reverse diffusion at the highest noise level and running all denoising steps, Ambrogioni and collaborators initialized at later noise levels, fitting Gaussian moments to account for shifts in mean and covariance. In DDPM experiments on MNIST, CIFAR-10, ImageNet64, and CelebA64, the slide from the 2023 symmetry-breaking paper showed FID staying roughly constant while a substantial early portion of the denoising trajectory was skipped, then deteriorating abruptly after a sharp threshold. The accompanying ImageNet late-start examples showed images remaining similar across earlier skipped starts and then becoming visibly degraded past that threshold.
His interpretation is that before the first symmetry-breaking event the potential is effectively unimodal. Perturbations caused by noise are pulled back by the quadratic barrier, so the detailed dynamics is not doing much beyond maintaining the Gaussian-like state. At the symmetry-breaking point, that barrier is suppressed. Small noise kicks then become consequential because they push the sample into newly forming basins.
The “highway exit” analogy captures the practical consequence. Diffusion is not a road on which every location is equally important. It has branching points. If a fast sampler jumps over a branching point, it can miss a minority mode and default toward the majority basin.
Ambrogioni connects this to diversity loss in accelerated sampling using a CelebA64 race-diversity analysis shown from the 2023 symmetry-breaking work. In that experiment, the slide compared the training set, a 1000-step DDPM reference, a five-step DDIM sampler, and a five-step late-initialized sampler. Ambrogioni says the training set and 1000-step DDPM reference had essentially matching measured race distributions. With only five DDIM denoising steps, the white class became much larger and minority race categories were squeezed out. With the five-step late-initialization scheme, positioned near the relevant symmetry-breaking point, the measured diversity was restored.
The claim is limited to the experiment as presented: in the CelebA64 analysis, skipping the time at which a minority-vs-majority decision was dynamically available suppressed minority modes, while placing the same small number of function evaluations near the bifurcation recovered the measured distribution without extra computation.
| Regime | What changes | Practical consequence |
|---|---|---|
| Before symmetry breaking | The potential is effectively unimodal and perturbations are pulled back. | Early denoising steps can often be skipped with little effect on FID. |
| At symmetry breaking | The quadratic barrier is suppressed and small noise kicks become consequential. | Branching decisions, including minority modes, are available. |
| After symmetry breaking | The sample has entered a basin and later denoising refines it. | Fast samplers that skipped the branch may preserve image plausibility while losing diversity. |
The broader lesson is that image quality and distributional diversity can fail differently. A fast sampler may maintain plausible images while losing branches of the distribution, because the skipped events are not merely local refinements; they are decision points.
The fixed points of the score reproduce mean-field phase transitions
Luca Ambrogioni formalizes the connection between out-of-equilibrium diffusion dynamics and equilibrium statistical physics through the fixed points of the score. Fixed points of the score are minima of the potential energy. Studying their stability means studying the Jacobian of the score, or equivalently the Hessian of the potential, around those points.
For simple data distributions, the fixed-point equation of the score becomes the equation of state of a mean-field statistical physics model. Ambrogioni uses the example of two delta functions, where the minima and zeros of the score can be computed directly. Setting the score equal to zero yields the same kind of self-consistency equation that appears in a Curie-Weiss magnetic system. His 2025 Entropy paper, “The statistical thermodynamics of generative diffusion models: Phase transitions, symmetry breaking, and critical instability,” presents this as a mean-field formulation of the score fixed-point equations.
This is the cleanest bridge in his account: bifurcations in the reverse diffusion dynamics have the stability structure of mean-field phase transitions. The mean-field model is defined over the distribution of clean data conditional on the noisy state . That is also why Ambrogioni relates the story to stochastic localization: both are concerned with how the posterior over clean states localizes as noise is removed.
But the fixed-point view has a practical limitation in trained high-dimensional models. Points of highest probability density are not necessarily typical points of the stochastic process. In high dimensions, trained networks see samples on an entropic shell around a fixed point, not the noiseless fixed point itself. Ambrogioni says this makes direct Jacobian analysis at the fixed point unreliable: the network is not trained there.
That motivates a shift from local fixed-point stability to a global information-theoretic quantity: the mutual information between the noisy state and the final clean sample, or equivalently the conditional entropy . This quantity averages over typical states rather than probing a possibly untrained, zero-noise equilibrium point.
Conditional entropy is the generative clock
Luca Ambrogioni uses conditional entropy to measure how much information about the final generation is transmitted at each time. The mutual information identity is simple:
For generation, the useful object is the conditional entropy rate. It tells how quickly uncertainty about changes as the diffusion time changes. Ambrogioni calls it a kind of “generative bandwidth”: the amount of information being transmitted at a given point in the reverse process.
A key result is that, for the diffusion processes he discusses, the entropy rate can be expressed through the norm of the score function, or equivalently through traces of the score Jacobian. Ambrogioni cites Kong, Brekelmans, and Ver Steeg’s 2023 “Information-theoretic diffusion” for the conditional-entropy-rate formulation, then connects it to score norms and Jacobian traces. The practical significance is that an otherwise difficult statistical quantity becomes estimable from the learned vector field. Entropies are usually hard to estimate; here the diffusion structure turns the entropy rate into an average involving the score.
The same formula links entropy production to instability. When the score Jacobian has eigenvalues that destabilize trajectories under generation, nearby reverse trajectories diverge. Divergence amplifies microscopic stochastic noise into macroscopic differences in the final sample. That amplification appears as a spike in conditional entropy rate. Ambrogioni’s information-dynamics framing associates divergent trajectories with generative branching.
Ambrogioni corrects the sign convention during the discussion of this point: the unstable directions are positive eigenvalues under the generative dynamics, while the corresponding directions can appear with the opposite sign under the forward process. The substantive point is that directions which contract under one temporal orientation become the directions in which reverse generation amplifies perturbations.
The paradoxical consequence is that high information production occurs when the score norm is small. A strong score suppresses noise by pulling deviations back. A contracted score lets stochastic perturbations pass through. At a global symmetry-breaking point, where the quadratic barrier is suppressed, noise in many directions can affect the sample, producing a high-bandwidth generative moment.
The point with the highest entropy rate are the point where the norm of the score is minimal.
This provides a principled way to choose time discretization. In a continuous SDE, the choice of time parameter is essentially a gauge: a monotone reparameterization with the appropriate rescaling does not change the underlying dynamics. But once the process is discretized, the choice of time grid matters. A grid can waste steps where little information is transmitted and skip regions where almost all generative information is produced.
Ambrogioni’s proposal is to use conditional entropy as the clock: take steps of equal information transmission rather than equal increments of an arbitrary noise schedule. In EDM experiments on ImageNet-64 and CIFAR-10, he reports that entropic spacing improved fast first-order and stochastic samplers, including against the already optimized EDM grid, across the image settings he showed. The slide on “Fast sampling EDM with entropic time spacing” displayed FID and FID-DINOv2 comparisons for ImageNet-64 and generated-image comparisons across different step counts, and Ambrogioni described the improvement as coming directly from the entropy-based schedule rather than from tuning extra parameters.
For continuous distributions, the conditional entropy requires regularization because differential entropy can diverge. The rescaled entropy used in the experiments multiplies the entropy rate by a function of ; when asked about it, Ambrogioni says the team does not fully understand the physical meaning but can show optimality for Gaussians in KL terms. A spectral variant further downweights high spatial frequencies because they are less perceptually relevant. He says it gave only marginal improvements over the rescaled version in the image experiments because the rescaled formula already suppresses high frequencies substantially.
The strongest practical effect he reports is in discrete diffusion, including language-diffusion work he described as forthcoming rather than already published in the talk. He said the group was preparing the results for a NeurIPS submission and had tested at about 150 million parameters, explicitly not at large scaling. In those experiments, his group uses a standard continuous diffusion setup over bit streams: tokens are binarized, bits are encoded as or , and diffusion is run in that continuous representation. They currently use a tokenizer for compatibility, then randomly binarize token space and append the bits. Semantic binarization, where similar tokens are kept close, did not matter in their experiments. Error correction also did not appear to matter much.
Within that limited regime, Ambrogioni says proper sampling, stochasticity, and entropic calibration can match autoregressive quality and outperform mask diffusion. He also says the sampling calibration matters much more than training calibration, and that stochasticity is important for high performance in language diffusion — a contrast with trends toward deterministic flow matching and ODE-style generation. These were presented as preliminary results from ongoing work, not as a claim established at language-model scale.
The mechanism he emphasizes is the same across images and the preliminary language work: if generative information is concentrated unevenly over time, then using an information-based clock becomes a way to allocate scarce sampling steps to the parts of the process where they matter.
Generalization replaces memorized branches with spatial modes
Luca Ambrogioni says the symmetry-breaking story can look like memorization if the model is choosing among a finite set of global patterns. In a two-delta toy model, the model chooses or . With a finite number of high-dimensional prototype images, the Jacobian of the reverse drift around the symmetric point contains an identity term from the forward process plus a covariance term from the data prototypes. If the prototypes are few and high-dimensional, they are approximately orthogonal, so each prototype becomes an approximate eigenvector. Each eigenvalue crossing zero corresponds to a bifurcation toward a global pattern.
Ambrogioni argues that this is not the right picture for generalizing image diffusion models. A real trained model, especially one with convolutional architecture and translation equivariance, is not simply memorizing whole large images. In the thermodynamic limit of very large images, memorizing global patterns would require unbounded information. Instead, the model compresses information into local couplings and feature relationships — for images, correlations among nearby pixels and local structures.
Translation equivariance changes the eigenvectors. In a translationally invariant system, the linearized operator behaves like a convolution operator, and Fourier modes become eigenvectors of the Jacobian. The instability is no longer a finite decision among stored prototypes. It is a spatial instability over frequency modes.
This is where Ambrogioni introduces mode softening. In a translationally invariant generative model, low-frequency spatial modes lose stability at a critical point. Rather than one isolated eigenvalue crossing zero, a continuum of low-frequency modes becomes soft as the image size grows. The zero-frequency mode destabilizes first, and nearby low-frequency modes follow. The result is long-range pattern formation.
The physical analogy shifts from mean-field bifurcation to field theory. In statistical field theory, systems have infinitely many degrees of freedom and phase transitions are often described in Fourier space. Ambrogioni says that for generalizing diffusion models with locality and translation equivariance, the instability structure becomes analogous to spatial critical phenomena rather than a simple finite-dimensional pitchfork.
In trained EDM-style ImageNet models, he reports Jacobian directional-derivative measurements along spatial Fourier modes. In translationally invariant models such as convnets, dynamic instabilities correspond to mode-softening events where low-frequency Jacobian eigenvalues vanish. Ambrogioni says the observed pattern is a critical region in which low-frequency modes show pronounced suppression relative to higher-frequency modes. In parallel, an estimated correlation length peaks. That peak marks the region where low-frequency fluctuations can extend over long spatial scales, seeding coherent structure. The mode-softening slides showed this visually as low-frequency directional derivatives dipping around the critical region while pattern correlation length began to grow rapidly.
The temporal picture is sharp. Before mode softening, noise is present but the relevant spatial modes are suppressed; the potential pushes perturbations back. At the critical region, low-frequency barriers vanish and noise can excite long-range structure. Shortly afterward, the system restabilizes around the emerging image configuration. From then on, denoising refines the sample but does not fundamentally change the large-scale pattern.
Ambrogioni illustrates the same phenomenon analytically with a patch score model introduced by Kamb and Ganguli in 2024. The model uses patches rather than the whole image to compute the score, making it translationally invariant and unable to memorize entire images. Because the score has an analytic form, the Jacobian spectrum can be derived. For ferromagnetic patches, the low-frequency eigenvalues take a Ginzburg-Landau-like form:
The sign of controls the instability. Since the term penalizes nonzero spatial frequency, the first instability occurs at . Then a continuum of small- modes softens. In the patch score model, this produces the soft-mode phenomenology directly. In a comparison among patch score, empirical pattern memorization, and Fashion-MNIST, Ambrogioni says the soft-mode structure appears in the generalizing patch model and in the trained Fashion-MNIST network, but not in the finite memorization case.
The distinction matters because it separates two kinds of “decision” in diffusion. A finite bifurcation can select a class-like or prototype-like branch. Mode softening describes how a full spatial field becomes organized. It is about the emergence of the image’s large-scale pattern, not simply a label choice.
Critical windows are also intervention windows
Luca Ambrogioni treats the mode-softening theory as more than a descriptive diagnostic. It identifies when the model is most sensitive to perturbations. If noise is blocked before the critical point and structure is largely frozen afterward, guidance should be especially effective during the instability itself.
His guidance experiment applies a short guidance pulse at the critical mode-softening stage and compares it with pulses applied at random times. In an EDM2 class-alignment comparison using DINOv2 scores, the slide reported that critical pulse guidance produced higher alignment than random pulse guidance for almost all tested classes. The visual example compared dog images generated without and with the critical guidance pulse, and the bar chart summarized class-alignment differences. Ambrogioni is careful not to present this as an engineering contribution optimized for deployment. The point is evidentiary: the critical stages located by the theory are functionally important. They are moments when the system is reactive to perturbations because the relevant barriers have softened.
That same distinction appears in the question period. Sasank Edara asks how to know which classes the model ends up in when multiple modes soften at the same time. Ambrogioni separates two cases. For a finite number of classes, the relevant event is a pitchfork-like bifurcation with a finite number of eigenvalues crossing zero. If there are two classes, the eigenvector pointing between them crosses zero at the decision time. One can investigate such decisions with “U-turn” experiments: start from an image of a class, add noise up to a certain time, then denoise again. As the noising crosses the symmetry-breaking time, the original class information is lost and the re-denoised image may switch class.
Mode softening, however, is not primarily about class labels. It concerns a continuum of spatial eigenmodes. Even within a class such as “dog,” there are indefinitely many ways to generate a specific dog. Mode softening is about the formation of the whole spatial pattern, not just selection of a semantic class.
Asked what it conceptually means for a mode to soften, Ambrogioni answers in terms of the potential’s resistance. An eigenvalue measures how strongly the potential pushes back when noise perturbs a given eigenvector. If a high-frequency eigenvalue remains strongly stabilizing, white noise may try to introduce high-frequency components but the dynamics suppresses them. When low-frequency modes soften, the potential stops pushing back in that sector. The low-frequency part of the noise becomes free, creates long-scale correlations, and seeds the future image. When the eigenvalue becomes unstable under generation, small kicks are amplified. After a brief window, the system restabilizes and the pattern freezes.
A large part of the pattern is produced at the moment of mode softening because it's the only moment in which the system lets the noise speak.
This is the most compressed version of the theory: diffusion generation is a controlled filter on stochasticity. Most of the time, the score suppresses noise. At critical instability windows, it stops suppressing selected directions. The noise that passes through those directions becomes structure.