Generative AI Targets Three Bottlenecks in One Health Decisions

Harvard postdoctoral fellow Lingkai Kong argues that generative AI can address three recurring failures in high-stakes One Health decision-making: scarce deployment data, hard-to-represent constrained policies, and shifting human priorities. In a Microsoft Research seminar, he presents flow matching, diffusion models and LLM agents as tools for patrol planning, poaching prediction, HIV testing policy and reward design, with collaborations involving conservation partners, the WHO, the Gates Foundation and South African health researchers.
Three gaps define the decision problem
Lingkai Kong’s central claim is that high-stakes One Health decisions repeatedly break at three points: there is too little reliable data for the environment where a decision will be deployed; the feasible policies are often too large and constrained to represent directly; and human priorities change faster than reward functions and policies can be redesigned by hand.
His proposed response is a stack of generative AI methods placed at those failure points. Flow matching is used first to transfer knowledge from shifted offline data while estimating where that data can still be trusted. It is then used again to represent policies over constrained combinatorial action spaces by generating continuous cost vectors that a solver converts into feasible actions. Diffusion is used to reason about unobserved contact-network expansion. LLM agents are reserved for the deployment bottleneck: converting changing stakeholder instructions into candidate reward functions and policy evaluations.
| Gap | Method | Application | Partner or status |
|---|---|---|---|
| Observational scarcity | Composite flow matching to reuse shifted offline data and estimate a local dynamics gap | Ranger patrol planning and poaching prediction | IFAW collaboration; Earth Ranger integration and Hwange National Park deployment described as next steps |
| Policy learning | Flow matching policy parameterized through a combinatorial optimization solver | HIV testing over contact networks | WHO, Gates Foundation, Wits Health Consortium collaboration; KwaZulu-Natal trial planned |
| Human-AI alignment | LLM agent for reward design with iterative refinement and social-choice-based selection | Changing public-health priorities | Presented as a deployment workflow for adapting policies as stakeholder priorities shift |
One Health is the application frame. Kong defines it as the recognition that human health, animal health, and environmental health are deeply interconnected, a framework shown as endorsed or adopted by organizations including WHO, CDC, FAO, WOAH, and UNEP. His motivating example is wildlife crime: illegal wildlife trade disrupts ecosystems, brings animals into closer contact with people, bypasses health screening and regulation, and creates conditions for zoonotic spillover. The presentation states that 75% of emerging infectious diseases are zoonotic in origin, making wildlife crime a threat across all three domains.
The operational problem that follows is resource allocation under uncertainty. In public health, decision makers may need to find people with undiagnosed disease while test kits and clinician time are scarce. In conservation, rangers may need to protect large national parks from poaching, logging, and illegal fishing with small patrol teams. Both are sequential decision problems: today’s action changes what is observed, who or what can be reached next, and how adversaries or disease dynamics may respond.
Kong’s data-to-deployment pipeline has four stages: data, forecasting, policy optimization, and deployment. The observational scarcity gap appears because real data collection is expensive while deep learning methods are data hungry. The policy learning gap appears when actions live in large combinatorial spaces with complex feasibility constraints. The human-AI alignment gap appears when stakeholders change priorities, requiring new reward functions and sometimes new policies.
Shifted offline data is useful only where the dynamics still match
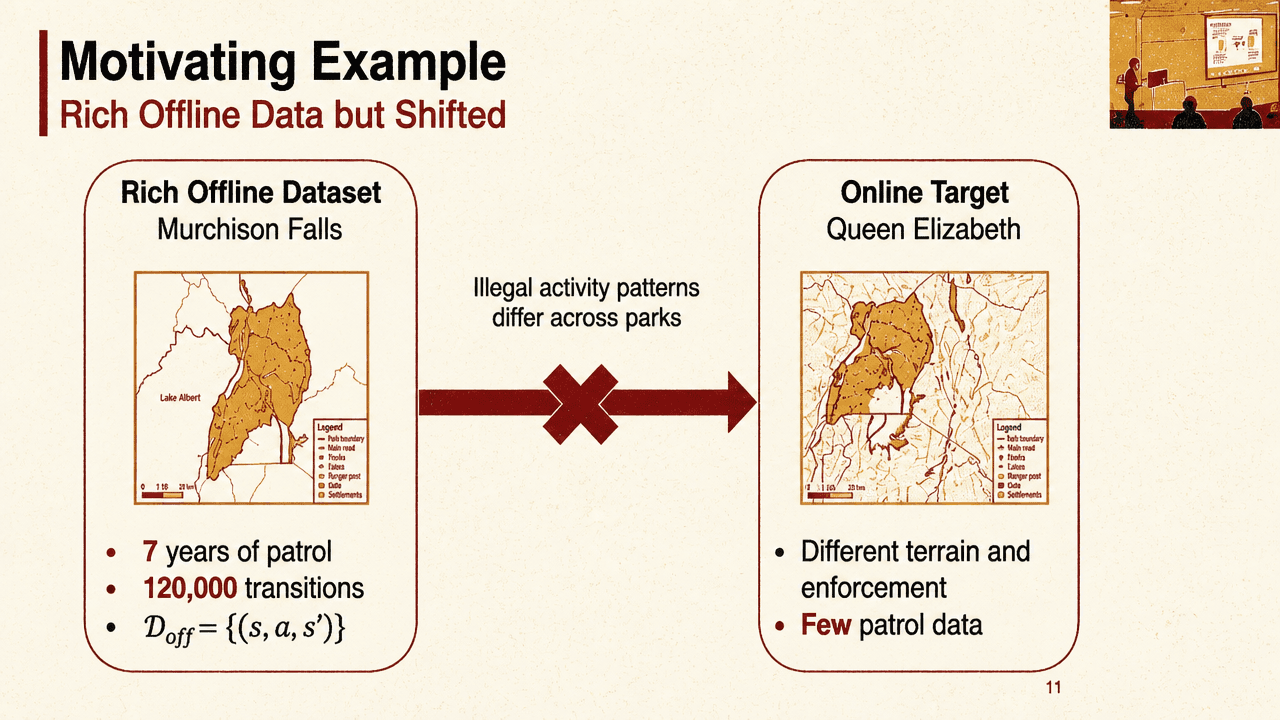
The first technical problem begins with ranger patrol planning. Rangers patrol national parks to detect and deter illegal activity, but adversaries observe past patrols and adapt. Patrol decisions also have long-term effects. Reinforcement learning is a natural formulation, but trial and error is costly because one “trial” is a real patrol. Parks are large; ranger teams are small.
Historical patrol data creates an opportunity but not a free substitute for online learning. Kong gives the example of Murchison Falls, with seven years of patrol data and 120,000 transitions. The target environment may be Queen Elizabeth National Park, where terrain and enforcement differ and only limited patrol data is available. In reinforcement-learning terms, the offline transition dynamics and the online deployment dynamics may not match: for the same state and action, the next-state distribution can differ. Naively using all shifted offline data can therefore mislead policy learning.
The same shifted-dynamics problem appears outside conservation. In viral surveillance, historical strains may not predict emerging variants whose transmission dynamics differ. In robotics, trajectories collected from a new robot may not match an aging robot whose joints have loosened and motors have worn. Across these examples, the question is how to reuse large shifted offline datasets while learning with only limited interaction in the target environment.
The missing object is a local reliability signal. Kong calls it the dynamics gap: a distance between the offline transition distribution and the online transition distribution at a given state-action pair. If the gap is small, offline data are reliable in that region and can be exploited. If the gap is large, offline data are unreliable there, and the agent should explore the online environment instead. In his phrasing, the dynamics gap tells the system “where to trust the past and where to learn from scratch.”
Existing approaches often estimate this gap with KL divergence, which can be obtained through binary classification without explicit dynamics modeling. The limitation, in Kong’s account, is that KL divergence becomes unbounded when the supports of the two distributions differ, making it unstable under large dynamics shifts. He proposes Wasserstein distance as the more stable alternative because it remains finite even under support mismatch and carries a geometric interpretation: the distance reflects physical movement in state space.
That choice creates two requirements. Transition dynamics may be high-dimensional and multimodal, so the model must be expressive. Online data are scarce, so the method must also be data-efficient. Kong’s solution is a flow-matching method with two modules: a composite flow structure for data-efficient dynamics learning, and optimal-transport pairing for more accurate Wasserstein estimation.
Flow matching, as presented by Kong, learns a transport map from a simple base distribution, such as Gaussian noise, to a complex target distribution. For transition dynamics, the distribution is conditional: the next-state distribution depends on the current state and action. The method therefore uses conditional flow matching, where the velocity field and transport map are conditioned on the state-action pair.
The data-efficiency move is to avoid learning the online dynamics directly from Gaussian noise. First, the large offline dataset trains an offline flow, producing an “offline world model” that captures environmental structure. Then the online flow starts from the offline dynamics and transports them to the online dynamics. Kong describes this as “standing on the shoulders of the offline world.” He also gives an informal theoretical guarantee: in flow matching, if the base distribution is closer to the target in Wasserstein-2 distance, generation error is lower. Since related offline and online environments should often share structure, the offline dynamics should often be closer to the online dynamics than Gaussian noise is.
At inference time, for a fixed state-action pair, the model generates paired offline and online next-state predictions by passing the same noise sample through the offline flow and then the online flow. The average squared distance between those paired predictions becomes a proxy for the dynamics gap. In the ranger-patrol example, the state is the current location of illegal activity, the action is a patrol route decision, and the next state is the predicted next location of illegal activity. The gap estimate becomes the average geographic distance between offline and online predictions on the map. A large distance means the dynamics have changed substantially between the offline and target environments.
The gap estimate depends on learning the right transport
The gap estimator depends not only on the predicted distributions but on how points are paired between them. The same offline and online prediction clouds can be connected by short, sensible transport lines or by long, crossed, arbitrary ones. Kong illustrates one transport with a gap of 1.2 and another with a gap of 6.5.
This matters because Wasserstein distance is the minimum transport cost. If offline and online dynamics are identical, the true gap should be zero. A non-optimal transport could still assign nonzero distance even when the distributions match. The method therefore has to encourage the flow to learn optimal transport, not arbitrary transport.
The key observation is that flow matching’s learned transport is determined by training pairings. Standard flow matching samples a base batch and a target batch, pairs samples randomly, and trains the flow to follow those training arrows. Random pairings lead to arbitrary, shuffled transport.
Kong’s fix is regularized optimal pairing within each training batch. Each data point is a transition tuple because the model is learning the conditional next-state distribution. The pairwise cost between an offline sample and an online sample has two parts: a term that prefers similar next states, and a term that prefers similar state-action conditions. The method computes the optimal pairing and trains the flow using those paired samples.
The stated convergence result is that, as the weight on pairing conditions grows and the training batch size grows, the proposed gap estimator converges to the Wasserstein-2 distance between offline and online transition dynamics for a fixed state-action pair. That is the justification for using the trained composite flow not just as a predictive model but as a local reliability estimator.
The simulation results use MuJoCo robotics benchmarks with three types of dynamics shift: friction, kinematic, and morphology. The setup allows 40,000 online interactions, described as 4% of standard online RL. Across 27 tasks, the proposed method improves average return by 14.2% over the best baseline shown. In simulated ranger patrols using Murchison Falls as the offline dataset and Queen Elizabeth as the online environment, Kong says the method finds 8% more illegal activity than the best baseline after one year of simulated patrols.
| Setting | Reported setup or result |
|---|---|
| MuJoCo shifted-dynamics benchmarks | 40,000 online interactions, described as 4% of standard online RL |
| MuJoCo average return | +14.2% over the best baseline across 27 tasks |
| Simulated ranger patrol | +8% illegal activity found versus the best baseline after one year |
The conservation work then moves from simulated planning to real-world poaching-prediction experiments. Here, the composite-flow idea is applied to predicting a poaching risk map: for each region of a park, estimate the probability of poaching activity. Real conservation data add another complication: detection is imperfect. Rangers may fail to observe illegal activity because of rough terrain and dense vegetation.
To handle data scarcity, the flow does not start from Gaussian noise. It starts from an ecological prior built from geographic features and past patrol effort. To handle imperfect detection, the method combines the latent poaching-risk model with an ecological detection model that estimates whether rangers would observe illegal activity. Multiplying latent risk by detection likelihood gives the probability of observed detections, and the flow is trained in latent space to infer true but unobserved poaching risk.
Kong reports a 10% improvement in poaching prediction over the strongest baseline, including classical machine-learning models and state-of-the-art deep-learning models. He also describes this as the first successful application of generative models to poaching prediction.
The deployment status is staged. The method has been validated in simulations; real-world conservation data experiments have been run for poaching prediction; and Kong says the team is working with the International Fund for Animal Welfare to integrate the method into Earth Ranger. Earth Ranger is described as a conservation platform used at more than 600 sites worldwide. The next step is deployment work in Hwange National Park in Zimbabwe, which Kong describes as one of Africa’s largest parks, home to more than 40,000 elephants, and facing serious poaching threats.
A slide quotes Lionel Hachemin, IFAW’s program director for Wildlife Crime: “I’m really excited by these results. I honestly thought generative AI was just hype—but this completely changed my mind!!” Kong presents that partner reaction as evidence of the kind of field impact he wants the work to have, while describing Hwange integration as ongoing or next-step deployment work.
HIV testing turns policy learning into constrained combinatorial RL
The second major gap is policy learning under combinatorial constraints. Kong’s human-health example is HIV testing, developed with the World Health Organization. He states that around 6 million people worldwide are living with HIV but do not know their status. In his formulation, testing is critical because once someone knows their status, they can start treatment, and treatment dramatically reduces transmission to others. But testing kits and clinician hours are limited, so the decision is whom to test next.
The setting is a contact network. Each node is a person, and an edge represents a relevant contact; in the HIV example, Kong identifies it as sexual interaction. Testing one person updates the global knowledge state and exposes a frontier set: neighbors of people already tested who can be reached through referrals. The action is not chosen from the whole population, but from this evolving frontier.
This makes the decision sequential. Testing someone now changes the frontier and therefore changes who can be tested later. The action must satisfy state-dependent combinatorial constraints: choose a budgeted number of people from the current frontier. The goal is to learn a policy distribution over feasible actions.
The bottleneck is combinatorial explosion. Selecting 5 people from 50 candidates yields 2,118,760 possible actions. A policy cannot explicitly represent a distribution over all feasible actions in such spaces, especially when constraints change with the state.
Kong’s contribution here is a flow-matching policy for reinforcement learning with combinatorial actions. It has two components. First, a solver-parameterized flow policy gives a compact continuous representation while guaranteeing feasibility. Second, the training procedure uses a reparameterized critic and a smoothed Bellman update to make actor-critic training efficient and stable.
The solver-parameterized idea uses a combinatorial optimization solver as the bridge between continuous generation and discrete feasible actions. Off-the-shelf solvers such as Gurobi and CPLEX can solve linear combinatorial optimization problems using a cost vector and a constraint set. The solver returns the feasible action minimizing the linear objective.
The key observation is that different cost vectors produce different feasible actions. The cost vector therefore becomes a continuous handle for a discrete action. Instead of learning a distribution over exponentially many actions, the model learns a continuous distribution over cost vectors. The solver converts each sampled cost vector into a feasible action.
In the HIV testing example, suppose the pool contains 50 people and the budget is to test 5. The flow generates a cost for each person; the solver selects the 5 with the lowest costs, while also respecting constraints such as membership in the frontier. Because only the direction of a linear cost vector affects the solver output, not its magnitude, Kong restricts cost vectors to the unit sphere. Doubling all costs would not change the ranking or selected action. That is why he calls the model a spherical flow policy.
The policy architecture raises a training problem. Kong uses actor-critic training: the actor is the flow policy, and the critic is a Q-function estimating the expected future reward of taking an action in a state. But the actor outputs cost vectors, while the environment action is produced by a solver. Two issues arise.
The first is efficiency. To score a sampled cost vector with the Q-function, the system would need to call the solver to convert that cost vector into an action, then compute the Q-value. Doing that for every sample at every flow-training step would require batch combinatorial optimization throughout training.
The proposed answer is a reparameterized critic. Since the solver defines a mapping from cost vector to action, the composed quantity Q(s, a*(s, c)) can be treated as a function of state and cost vector. A network, denoted Q-tilde, takes the state and cost vector as input and directly outputs the Q-value. Scoring then becomes a forward pass through the critic, without a solver call at training time.
The second issue is discontinuity. Cost vectors live on a sphere and vary continuously, but feasible actions are finite. The solver partitions cost space into regions; all cost vectors in one region map to the same action. Within a region, Q-tilde is flat. At region boundaries, the selected action changes, and the Q-value can jump. Kong says these jumps create high gradient variance, making critic learning unstable under standard Bellman training.
His fix is a smoothed Bellman update. Instead of training the critic to predict the exact Q-value at a single cost vector, the method samples neighboring cost vectors on the sphere from a vMF distribution and trains the critic to predict the local average Q-value over that neighborhood. Kong states two theoretical properties: the smoothed Bellman equation has a unique fixed point, and that fixed point is smooth over the sphere. This allows stable critic learning with standard temporal-difference methods.
On four combinatorial RL benchmarks—dynamic scheduling, dynamic routing, dynamic assignment, and dynamic intervention—Kong reports a 21% average improvement over state-of-the-art combinatorial RL baselines. He also reports faster training time, attributed to the reparameterized critic.
The question period clarifies an important point: the solver is not being replaced by a neural network. An audience member initially asks about “learning a network that basically can do the same job as the solver.” Kong explains that the flow output is still passed to a combinatorial optimizer because the final action must satisfy combinatorial constraints. The learned component is the policy over cost vectors and, during training, the reparameterized critic used to avoid repeatedly calling the solver for scoring. When asked whether the method backpropagates through the solver, he says the setting is reinforcement learning and the training uses a weighted flow-matching objective within an actor-critic framework rather than relying on direct solver backpropagation.
Incomplete contact networks require predicting how the frontier will expand
The HIV formulation initially assumes the full contact network is known. Field partners pushed back on that assumption. In practice, only part of the network is observed. When a person such as X1 is tested, the team learns that person’s result and reported contacts, such as X2, X3, and X4. Those contacts become the frontier. Everything beyond the frontier remains unknown until more people are tested. The network expands as testing proceeds.
This changes the policy problem. To decide whom to test next, the policy must reason about parts of the network it has not yet observed. Kong’s solution is to train a diffusion model on historical contact-tracing data. After each historical test, the program recorded contacts and features such as age and marital status. The diffusion model learns, for a frontier node, how many new contacts might appear and what their features might be.
At decision time, the method starts from the observed partial network and samples K plausible completions. Each sampled graph fills in the unknown portion differently. The policy is evaluated on each sampled graph, producing candidate frontier-node selections. The final decision is obtained by aggregation: the node selected most often across the samples is chosen. The purpose is to make decisions more robust when the full network is unknown.
On a real HIV contact network, the evaluation metric is cumulative discounted positives: finding positive cases earlier receives higher reward. The results compare Random, Greedy Classifier, Partial Graph, and the proposed method. Kong reports that the proposed method finds more cases faster than the baselines, with an area-under-curve score of 9.29 versus 8.45 for the best baseline, an improvement shown as 12.6%.
| Method | Area under curve |
|---|---|
| Best baseline | 8.45 |
| Ours | 9.29 |
Kong says the work is moving toward a real field trial in KwaZulu-Natal, South Africa, in collaboration with the Gates Foundation, WHO, Professor Alastair van Heerden, and Wits Health Consortium. KwaZulu-Natal is identified as the trial location, and Kong shows mobile testing operations. He says the partner teams’ mobile testing units have reached tens of thousands of people across rural communities, and that a field trial is planned later in the year.
Changing stakeholder priorities make reward design the deployment bottleneck
The final gap appears after a policy exists. In deployment, public-health stakeholders’ priorities keep changing. One week they may ask to slightly prioritize young people because of higher transmission rates. Later they may prioritize pregnant women and rural areas to prevent vertical transmission and address access gaps. At another point they may want to balance coverage across groups to ensure equity.
In reinforcement learning, each of these priorities maps to a reward function, and each reward function produces a different policy. A shift in priorities therefore becomes a new reward-design problem followed by retraining. Kong identifies three reasons this is hard.
First is the language-to-math gap. If a stakeholder says “slightly prioritize young people,” the word “slightly” does not determine whether the reward weight should be 1.2, 1.5, or 2.0. Second, distributional impacts are hard to predict. A reward function intended to prioritize pregnant women could unintentionally over-serve urban areas while under-serving rural communities. Third, reward design is iterative. A team designs a reward, trains a policy, simulates outcomes, evaluates failures, revises the reward, and repeats the loop.
Kong proposes an LLM-agent framework to accelerate this process. A stakeholder supplies a natural-language command, such as “slightly prioritize young people.” The LLM receives that command plus the RL codebase, so it has access to the environment structure, and generates multiple candidate reward functions. Each candidate represents a different interpretation of the instruction.
The framework has two design choices Kong emphasizes. It does not ask the LLM to produce a final reward in one shot; instead, it uses an iterative refinement loop to improve generated reward functions. It also does not let the LLM select the reward function by itself. Instead, it uses a social-choice-based selection function to choose among policies in a way intended to maximize benefit across groups. In Kong’s description, this automates a reward-design cycle that otherwise requires substantial human effort, reducing it to a process that can run in hours.
This final module differs from the flow-matching work. The earlier methods address data scarcity and combinatorial policy synthesis. The LLM-agent component is aimed at the human-AI alignment gap: the practical difficulty of translating changing stakeholder priorities into reward functions and policies quickly enough for deployment.