Small-Model Inference Needs Infrastructure Beyond Model Servers

Filip Makraduli of Superlinked argues that the hard part of small-model inference is no longer simply serving a model, but operating many embeddings, rerankers, extractors and multimodal models efficiently in production. In his account, conventional one-model-per-container deployments waste GPU capacity and leave teams to rebuild routing, autoscaling, monitoring, hot-swapping and eviction themselves. Superlinked’s SIE is presented as an open-source attempt to provide that missing infrastructure layer for AI search and document-processing workloads.
The missing layer is production infrastructure, not another model server
Filip Makraduli presents Superlinked’s SIE as an attempt to fill a gap in small-model inference: the layer between a working model server and a production system that can route, autoscale, monitor, hot-swap, and evict models without wasting GPUs. The claim is not that teams lack ways to run a model. It is that embeddings, rerankers, extractors, and other small models used around AI search and document processing create an operational shape that standard one-model deployments do not handle well.
Model serving itself is not the missing piece. Makraduli names TEI, vLLM, and a FastAPI wrapper as examples of things that can serve a model. The gap is what happens after that: routing, per-model pool isolation, autoscaling, scale-to-zero, monitoring, Terraform, Helm, and cloud deployment. In his telling, every team ends up rebuilding that layer on its own, and it “barely exists in open source.”
The problem is sharper for small models because one-model-per-container or one-model-per-GPU deployments waste capacity. Makraduli contrasts five 24GB GPUs, each assigned to one small model — Stella, bge-m3, a reranker, GLiNER, and CLIP — with most of each GPU left idle. The alternative is one 24GB GPU running multiple models through hot-swapping and least-recently-used eviction.
| Deployment pattern | Example shown | Consequence |
|---|---|---|
| One model per GPU | Five 24GB GPUs for Stella, bge-m3, reranker, GLiNER, and CLIP | Most GPU capacity remains idle |
| Multi-model GPU sharing | One 24GB GPU with the same model types hot-swapped | Higher utilization, with least-recently-used eviction when memory is tight |
That utilization problem is the clearest version of the infrastructure claim. A deployment pattern that looks operationally clean — one model, one container, one GPU allocation — becomes wasteful when each model occupies only a few gigabytes. In that setting, the bottleneck is not simply model speed. It is whether the serving layer can load, evict, and route across several models without pinning a whole accelerator to each one.
The Superlinked inference engine, or SIE, is the response Makraduli says his team built. It is open source, Apache 2.0, and presented as an inference server plus production cluster for embeddings, reranking, and extraction. The stated goal is not just to run a single model, but to let teams move from a laptop to Kubernetes with model choice treated as configuration rather than a fresh infrastructure project.
Why small models matter to agentic workflows
Agentic workflows depend on context, and Filip Makraduli argues that unmanaged context degrades. That is why infrastructure for AI search and document processing matters even to teams that do not think of themselves as search teams.
He points to “context rot” as the practical reason. Citing Chroma Research, he describes document question-answering performance degrading as input length grows: quality falls as context increases, or in his shorthand, more tokens produce worse answers. His answer is context management — deciding what goes into context before an agent or workflow uses it.
Small models become part of that context-management layer. They can preprocess data, rerank candidates, extract relationships, classify content, or prepare knowledge structures before a larger model is asked to reason over the result. This can also coexist with simpler tools such as code search and grepping. In his view, preprocessing can make those file systems and search workflows better rather than replacing them.
Makraduli separates several supporting signals from the community. A reference to Liu et al. 2023 is used for the “lost in the middle” pattern: accuracy drops when relevant information lands in the middle of the context. A Chroma reference is used for broader testing of context behavior across models. He also cites Andrej Karpathy’s use of LLMs to build personal knowledge bases, and points to Chroma’s Context-1 work on a self-editing search agent. A visible post from @hwchase17 says a raw folder was compiled into a knowledge graph with a “71.5x token reduction” instead of reading files directly. Makraduli’s point is that preprocessing and context reduction have become a practical pattern for making agents more effective.
His production example is taxonomy classification for an e-commerce catalog with roughly 10,000 categories. The workflow takes product titles and images, extracts signals, encodes text and images, reranks candidates, and classifies items into categories such as “Electronics + Computers + Laptops.” Makraduli describes SIE in that case as a tool-calling solution: small models act as tools that retrieve, filter, and process data for the workflow.
The operational point is that switching model type should mean changing one parameter, not rebuilding the surrounding infrastructure. If a workflow needs an embedding model, a reranker, a named-entity extractor, or a multimodal encoder, the infrastructure should not force a new deployment pattern each time.
Model support is not a checkbox
Model support is the “yin” of inference in Filip Makraduli’s framing. The reason is breadth: open source models are multiplying quickly, and users want to choose the right model for narrow tasks.
your inference is worthless if you're not supporting the right models or you're not offering enough breadth of options for your users.


Makraduli cites Hugging Face Hub statistics showing model counts rising from 2022 through 2025, with 2.7 million models marked on March 26. He says there may now be close to three million. His broader claim is that open source is moving quickly in both size and accuracy, and that on specific tasks, open source models can beat managed services.
He points to general-purpose open source models as part of the same trend. A performance-versus-size comparison places smaller Gemma and Qwen variants against larger models by Elo score. Makraduli’s interpretation is that low-parameter models can be highly relevant, and infrastructure has to keep up with that reality.
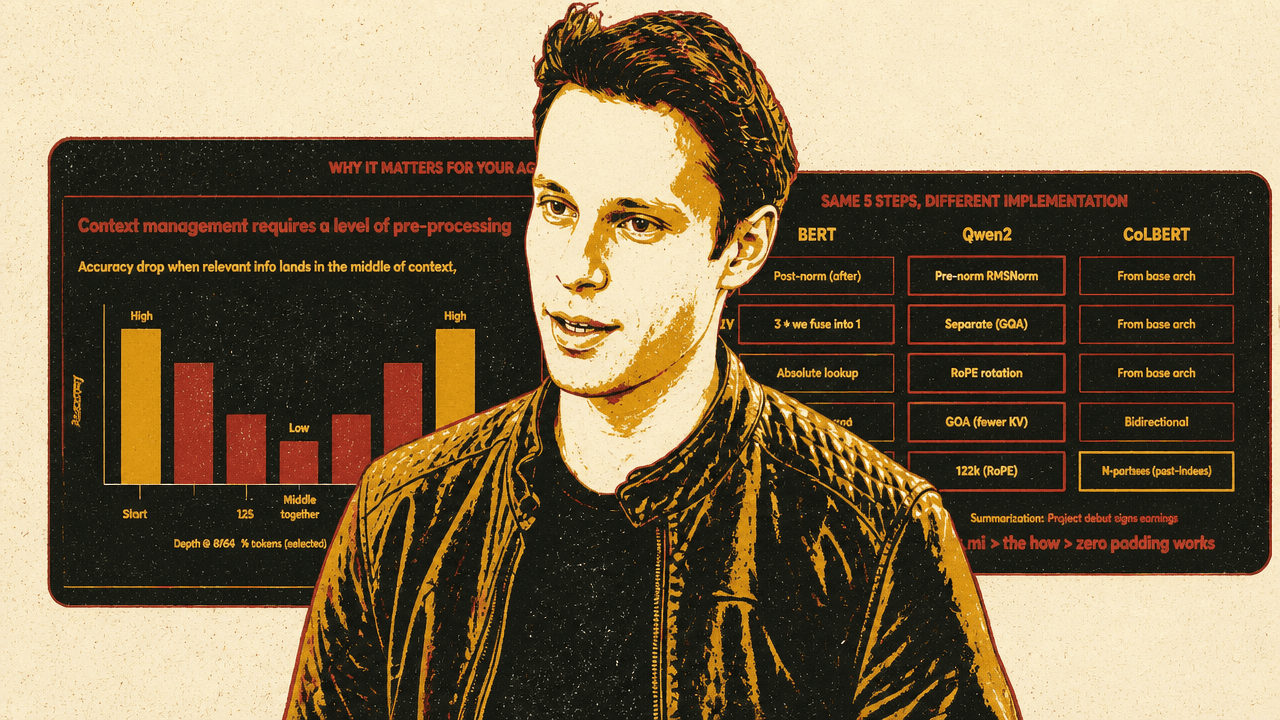
But supporting many models is not the same as putting many names in a configuration file. Architectures differ under the hood. He lists BERT, ModernBERT, cross-encoders, SPLADE, Qwen2, ColBERT, CLIP, SigLIP, Florence2, and XQling as examples of model families with different assumptions and outputs. Some produce dense vectors. Some produce sparse vocabulary-weight vectors. Some produce scores rather than vectors. ColBERT-style models output a vector per token for late interaction. Multimodal models combine image and text encoders into a shared embedding space.
That leads to the engineering burden: there is no universal engine where BERT, Qwen2, and ModernBERT are interchangeable. Makraduli says Superlinked re-implemented the forward pass and pooling for each architecture rather than merely wrapping existing implementations. The system is presented as supporting 85+ models with 35+ runtimes and inference backends, with 15 of 35 adapters using Flash Attention 2 with variable-length sequence packing.
Different architectures force different inference paths
The same high-level inference request can require different internal implementations depending on the model family. Filip Makraduli spends much of the technical section on that point because, in his telling, this is one of the places where small-model infrastructure becomes harder than it first appears.
He compares BERT, Qwen2, and ColBERT across five steps: normalization, query/key/value handling, positional encoding, attention, and output. The differences are not cosmetic. They affect the forward pass, memory behavior, batching, and output handling.
| Step | BERT | Qwen2 | ColBERT |
|---|---|---|---|
| Norm | Post-norm | Pre-norm RMSNorm | From base architecture |
| Q/K/V | Three projections, fused into one | Separate projections with grouped-query attention | From base architecture |
| Position | Absolute lookup | RoPE rotation | From base architecture |
| Attention | Multi-head attention | Grouped-query attention with fewer KV heads | Bidirectional |
| Output | One pooled vector | One pooled vector | N vectors, one per token |
The BERT and Qwen example shows why a generic abstraction can break. BERT can use absolute positional lookups; Qwen uses rotary positional embeddings. BERT-style query, key, and value projections can be fused in a way that Qwen’s grouped-query attention does not allow. ColBERT is different again because its output type is not a single pooled embedding but multiple token-level vectors used for late interaction.
Padding waste is another implementation detail that becomes a production issue. In token-based batching, one request may have few tokens while another has many. If both are padded to the longer length, compute is spent on empty tokens. Superlinked’s approach uses variable-length Flash Attention so packed sequences can avoid that waste. Makraduli describes this as a key differentiator in their inference design.
This is where his earlier correction about inference returns. He had already worked with vLLM, training, fine-tuning, evaluation, benchmarking, applied AI research, and Flash Attention. What he had overlooked was how models run in production: scheduling, GPUs, routing, and automation. Building SIE with infrastructure engineers at Superlinked was his way of learning that missing layer from first principles.
The cluster is the other half of the system
Infrastructure is the “yang” of inference in Filip Makraduli’s framing. In SIE, the visible user-facing API is intentionally small: encode, score, and extract. Around those primitives, the cluster handles routing, queuing, GPU pools, model loading, eviction, metrics, and autoscaling.
The simplified architecture has three endpoints: /v1/encode, /v1/score, and /v1/extract. Requests go through a router with per-model routing, LoRA affinity, pool routing, and queue-based behavior for high concurrency. The pools can use different hardware: an L4 pool for models such as Stella or GLiNER, an A100 pool for bge-m3 or rerankers, and an H100 pool for Qwen2-4B with TensorRT-LLM. Across pools, the system uses LRU eviction.
Autoscaling is part of the design rather than an afterthought. Makraduli says the system uses Prometheus metrics with KEDA autoscaling, including scale-to-zero, so GPUs are not kept idle when there is no work. He also references spot instances, Terraform, Helm, Docker images, AWS, and GCP. The intended deployment experience is “terraform apply” plus Helm install to get production infrastructure.
The contrast with a standalone model server matters. A server can expose inference for one model. SIE is presented as a way to combine model breadth and production operation: model adapters on one side, cluster management on the other. Makraduli says Superlinked open sourced both halves — the model inference layer and the production cluster — so teams do not have to write the glue code themselves.
He frames the project as specifically oriented toward AI search and document processing. Superlinked tested SIE with Chroma, Qdrant, Weaviate, and LanceDB. Superlinked’s integration material describes uses such as instruction-following rerankers, relationship extractors, self-hosted data transformations, indexing and ranking models, and query or data preprocessing for latency. Those examples support the narrower point: the engine is meant to sit in the model stack around retrieval, ranking, extraction, and document workflows.
The lesson Makraduli says he learned
Filip Makraduli begins from a correction to his own earlier confidence. He had written about what makes embedding model inference fast, covering Flash Attention, quantization, whether workloads are memory-bound or compute-bound, and whether rewriting systems in Rust solves the problem. The correction he says he received was that he had missed a key aspect: inference in the real world.
That correction becomes the structure of his argument. Inference is not only a model’s forward pass, and it is not only a server endpoint. BERT, Qwen2, ColBERT, cross-encoders, sparse models, and multimodal encoders do not all behave like interchangeable embedding functions. A fleet of small models also cannot be operated efficiently if each one requires a dedicated GPU and a hand-built deployment stack.
Makraduli closes by revealing the recurring background image from his materials: a vector visualization of sinusoidal positional encodings, the transformer mechanism used to encode position. The callback fits the narrower lesson. Understanding model internals still matters. But for small-model inference in production, those internals have to meet scheduling, routing, memory pressure, and GPU utilization in the same system.