Agent Evals Should Replay Production, Not Exhaustively Imitate Unit Tests

Phil Hetzel of Braintrust argues that teams should stop treating evals for AI agents like unit tests meant to cover every possible failure. His maturity model starts with human judgments that record why an output failed, turns those justifications into scalable scorers, and then uses production traces to drive offline experimentation. The hard edge, he says, comes with tool-using agents, where useful evals must account not just for the final answer but for external system state and side effects at the moment the trace originally ran.
Evals are for shipping better agents, not exhaustively proving them correct
Phil Hetzel frames evals as a practical discipline in service of agent quality. The point is not to reproduce the mental model of unit testing, where teams try to enumerate every possible failure. For agents, he argues, that approach becomes infinite: teams would spend all of their time writing tests for hypothetical failures instead of improving and shipping the system.
The better starting point is known failure modes. A builder or subject-matter expert can often say what “bad” looks like for a particular agent: the answer is unkind, unhelpful, too expensive to run, too tool-heavy, too token-heavy, or otherwise misaligned with what the agent is meant to do. Evals should be built around those concrete ways the agent can fail.
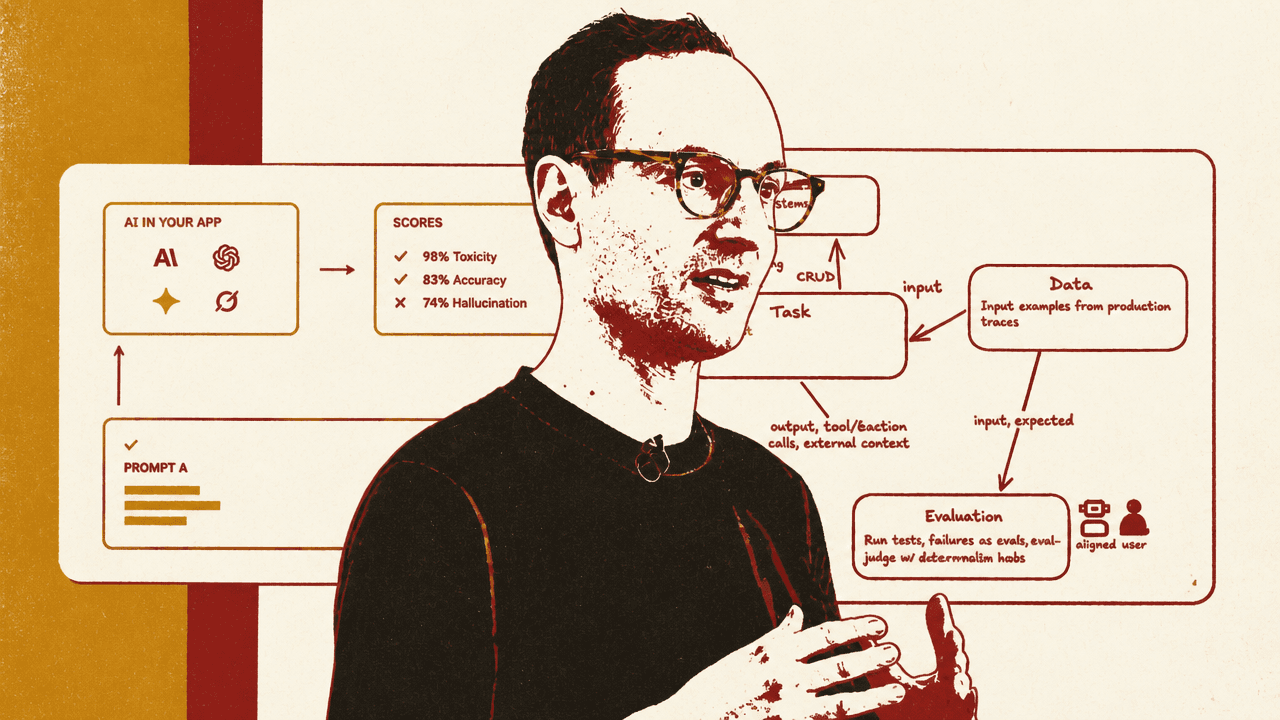
Hetzel distinguishes the task, the data, and the scorers as the core primitives of an eval. The task is the agent or prompt under test. The data is the set of inputs that initiate the task. The scorers are the functions that judge the result and execution of the task. Those scorers may be deterministic code, an LLM-as-judge, or human annotation, depending on the failure mode.
Evals are not unit tests.


The distinction matters because agent quality is not only a defensive concern. Hetzel names reputational risk, systems risk, and compliance or legal risk as reasons teams need confidence that an agent will behave appropriately with real users. But he also describes evals as an offensive tool: each change to an agent can be measured, so the team knows whether a tweak improved the application and by how much.
That measurement does not have to be perfect to be useful. Hetzel says LLM-as-judge techniques often will not return 100% reliable results every time, and that is acceptable when they are directionally useful and trending in the right direction. The standard is not mathematical certainty. It is whether the eval system gives the team enough signal to improve agent quality with less guesswork.
| Maturity level | What changes | Typical eval focus |
|---|---|---|
| Level 0 — Just get started | Human graders judge outputs and write justifications. | Good or bad, and why. |
| Level 1 — Measure to manage | Justifications become failure modes and scalable scorers. | Production-derived inputs, LLM judges, and deterministic code. |
| Level 2 — Accounting for complexity | Agents use tools and interact with external systems. | The full trace, including tool calls and external context. |
| Level 3 — Advanced evals | External system state and side effects have to be represented at scale. | Versioned queries, state represented in the dataset, sandboxes, and mock CRUD endpoints. |
The first useful eval is a documented human judgment
Hetzel is unusually permissive about “vibe checking,” at least as a starting point. When a team has no eval infrastructure, running an agent against a handful of examples and asking whether the outputs look good is not wrong. It is better than nothing. The mistake is stopping at an unexplained thumbs up or thumbs down.
The important move at this stage is to capture the justification. A human annotator should not merely mark an answer good or bad; they should write down why. Hetzel says the annotator might be the agent builder, but preferably should be a subject-matter expert who knows what a quality response should look like in the domain.
That written rationale is the seed of the later eval system. It extracts domain knowledge that otherwise remains in the reviewer’s head. In Hetzel’s maturity model, the thumbs up or thumbs down is only the first signal; the justification is what can eventually be converted into an automated scorer, including an LLM-as-judge.
At this stage, the workflow is deliberately simple: a trace goes to a human grader; the grader supplies a thumbs up or thumbs down and a justification; those justifications later inform LLM-as-judge scorers. The task may be a simple prompt or workflow tested against a short human-generated or synthesized dataset. The scoring can be manual. What matters is that the team starts producing structured evidence about quality.
He also emphasizes the interface given to human graders. A generic annotation platform is a poor fit if the agent traces have domain-specific structure. Reviewers know what the traces should look like and what parts deserve attention. Hetzel says annotation views should be specific to the users and the agent under review, because that specificity encourages useful evaluation.
The Braintrust example shown during this section illustrates the kind of material a grader might see: a customer-service conversation, scoring categories such as “Fail on unknown inputs,” “Format,” and “Tone,” and a place to add justification before submitting a score. The example user asks, “Can you lower my Apple Order plan?” and the assistant begins by checking active installment plans, listing an Apple Store order and an IKEA order with remaining balances and upcoming payments. The grader sees the trace in context and can judge the answer against criteria that matter for that agent.
Human justifications become scalable scorers
At the next level, Phil Hetzel says teams should use the justifications they have collected to identify the agent’s actual failure modes. He describes running those justifications through tools such as Cursor, Claude Code, or Codex to derive why annotators gave certain responses a thumbs down. Once those patterns are visible, the team can automate some of the judgment that previously depended on a few experts.
Subjective failure modes are candidates for LLM-as-judge. Objective failure modes are candidates for code. Hetzel says teams do not have to use LLMs to judge other LLMs in every case. If the agent uses too many tool calls or too many tokens, a coded scorer may be the right way to fail the eval.
Hetzel warns against treating an LLM judge as inherently reliable simply because it has been assigned the role of judge. “Just because you put a robe and a cloak on an LLM,” he says, it does not become more trustworthy. LLM judges themselves need evaluation. The session does not go deeply into judge evaluation, but his position is clear: LLM-as-judge is useful, not magic.
The final audience question presses on the same point: should teams favor deterministic graders, or embrace LLM-as-judge? Hetzel’s answer is that some things are subjective, which is part of why agents are useful. He would embrace LLM-as-judge, but evaluate the judge against what a human would decide in the same circumstance. When the audience member summarizes that as “eval the eval,” Hetzel agrees, adding that LLM judge outputs are discrete, which makes it easier to create a ground-truth dataset for them.
A concrete LLM-judge setup for “Response Conciseness” shows how this scaling works. The judge is instructed to evaluate whether an assistant’s response is appropriately concise: direct while still answering the user, free of unnecessary repetition or verbosity, and detailed enough without over-explaining. The rubric distinguishes a concise and complete answer from one that is slightly long, too verbose, or too short and incomplete, with the judge instructed to return only one letter.
That example also shows why the human justifications matter. A useful LLM judge is not just a generic preference prompt. It encodes the quality criteria the team has learned from review.
Production traces should become eval data
By the “measure to manage” stage, Hetzel argues, teams should stop relying only on invented examples. They should use real examples from production, or at least from user-acceptance testing, as eval inputs. His preferred framing is that evals are not “running tests” so much as “rerunning production.”
This is where Hetzel connects evals with observability. Braintrust, he says, treats evals and observability as essentially the same problem from a systems perspective. Evals are used before production to gain confidence in an agent. Observability is used after production to remain confident in it. The mature loop connects the two.
The flywheel he describes has four steps: observe, analyze, evaluate, and improve. First, log every input, output, trace, and failure. Then find patterns: what is breaking, for whom, and why. Then turn those failure patterns into new eval cases. Finally, improve the agent, ship, and repeat. In that loop, production traces become eval datasets, quality improves with each deployment, and debugging becomes proactive and data-driven.
Don’t think about evals as running tests, think about evals like rerunning production.
This is the point at which evals become more than a release gate. Production traces expose failures the team did not anticipate. Those traces can be brought back into an offline experimentation environment, replayed through an eval, and used to guide the next change. Hetzel describes this as “playing offense” with evals: the eval suite becomes a way to hill-climb toward better behavior.
The flywheel also changes what a good eval dataset looks like. Instead of trying to imagine every possible bad input in advance, the team accumulates cases from real usage. The dataset reflects observed failure patterns. When the agent changes, those cases are rerun to see whether the problem improved, regressed, or shifted elsewhere.
Tool-using agents force evaluation beyond the final answer
As agents become more complex, Phil Hetzel says the number of failure vectors grows. A simple model call can be judged largely by its final output. A tool-using agent may require evaluation of the entire trace: which tools it called, what context it gathered, what external systems it touched, and whether its intermediate steps were appropriate.
Hetzel divides tool calls into two broad categories. The first is context gathering: tools that retrieve information and inject it into the LLM. The second is CRUD-based interaction, where the agent creates, reads, updates, or deletes information in a database or external system. Both can improve agent usefulness. Both also create new ways for the agent to fail.
Context gathering raises the question of whether the agent retrieved the right information at the right time. CRUD raises a harder problem: the agent may be taking actions against live systems. During offline evaluation, a team usually cannot let an agent create, update, or delete production data. Even if the evaluation environment is isolated, the team still needs to represent the external system’s state as it existed when the original production trace happened.
That time-dependence is central. If an input was captured at one point in time, but the external system changed later, rerunning the same eval later may not mean what the team thinks it means. A different output could reflect different agent behavior, or it could reflect a different external state.
Hetzel says this is not completely solved. But he describes several emerging approaches. One is to include relevant external-system state inside the trace itself. Because agent traces can be arbitrarily large, they can hold substantial context: the state of external systems at the time the trace was created can be inserted into the trace and then injected into the task during evaluation. In his framing, this can reduce the need to create an entire test structure and infrastructure for every case.
Another approach is timestamped or versioned querying. If the underlying system supports it, the eval can query a data store as it existed at a particular moment. Hetzel gives the example of a vector database set up to support version queries, allowing the team to retrieve the state corresponding to the time the original input was added to the dataset. For context-gathering tool calls, the advanced stage also points to versioned queries similar to slowly changing dimension type 2 patterns in data warehousing.
For CRUD actions, Hetzel says teams will want mock endpoints. The agent can run in a sandbox where create, update, and delete calls point back to represented application state rather than touching live systems. In the advanced architecture he shows, a production trace becomes a potential eval case; optional human annotation may be added; the eval case includes application state; the task runs in a sandbox; scorers judge the result; mock API or CRUD calls point back to app state; and, if possible, timestamped queries retrieve data from a store.
This is the hard part of mature evals: not scoring a final string, but representing enough relevant external-system state to evaluate whether the agent’s behavior improved.
The next phase is better discovery, coding assistance, and simulation
Hetzel closes by pointing to emerging patterns for teams that have already built the basic flywheel. One is topic modeling across production traces to uncover failure modes at scale. Instead of relying only on individual reviewers to notice problems, topic modeling can help surface recurring categories in the traces the team is already collecting.
Another pattern is combining coding agents with an eval platform’s CLI. Hetzel mentions Claude Code and an eval provider’s CLI as a way to perform eval-driven iteration in a more automated way. He presents it as a pattern he sees emerging in the space.
A third idea appears in the forward-looking material: simulation. A simulated user agent can interact with the agent under evaluation, producing more dynamic cases than a static list of inputs. Hetzel mentions the idea only briefly. The direction is consistent with the rest of his talk: as agents become more interactive, stateful, and tool-using, the eval process has to evaluate behavior over a trajectory, not only a single response.