Coding Agent Skills Need Live Documentation, Not Cached Product Knowledge

Marc Klingen of Langfuse argues that coding agents can add observability, but often do it first from stale model memory, producing broken or incomplete instrumentation before recovering through current documentation. In a talk on building a Langfuse skill for Claude Code, he says the fix is not to stuff more product knowledge into the agent, but to give it reliable ways to find live docs, expose its intermediate work in traces, and evaluate changes against realistic repositories. The same work, he warns, creates new risks when optimization loops reward shorter paths and remove the documentation-fetching and approval steps that make the skill reliable.
The failure mode is not that coding agents cannot add observability. It is that they add the wrong version first
Marc Klingen described Langfuse’s agent skill as a response to a specific pattern: coding agents could already implement Langfuse instrumentation, but they tended to do it through stale model memory, recover only after hitting errors, and produce a non-optimal setup.
Langfuse’s own documentation footprint makes the problem harder. Klingen said the docs now span 478 “content dense” markdown files across five feature areas. The product has gone through three major updates, and its flexibility means there is no single correct implementation path for every application. Langfuse’s position, as he framed it, has been deliberately infrastructure-oriented rather than opinionated: teams can trace, evaluate, and customize workflows in many different ways. That flexibility is useful when agents can adapt implementation to each codebase. It is a liability when the agent is guessing from pre-training context.
The concrete example was Claude Code. Asked to add Langfuse tracing to a project, it could eventually get to a feasible implementation. But the first attempt relied on outdated pre-training context. The agent then tried to verify the instrumentation, found that it did not work, fetched current implementation information from the web, and corrected itself. Klingen’s diagnosis was threefold: the model had outdated training data, the setup was not optimized for the user’s application, and the path was slow because the agent first implemented instrumentation in a broken or outdated way and then repaired it.
The initial trace also exposed a deeper observability gap. A “Claude Code only” trace captured two LLM calls in an agent, but not what the agent was actually doing. For a product whose purpose is agent observability, that was not enough. The goal of the Langfuse skill became: give users a Langfuse expert that can quickly set up observability, prompt management, and evaluations using current documentation and best practices, without requiring every user to talk directly to the Langfuse team.
The trace comparison made the improvement concrete. The “Claude Code only” trace was short, showing a simple pair of agent calls. The “Claude Code + Langfuse Skill” trace shown on Klingen’s slide was visibly more detailed, with repeated specialist retrieval steps, bash tool use, and evaluation entries for observability, prompt migration, and evals. Klingen described it as a “stark difference”: the skill changed not only the final setup path, but also the recorded execution shape, adding traceable retrieval, tool, and evaluation activity around the implementation.
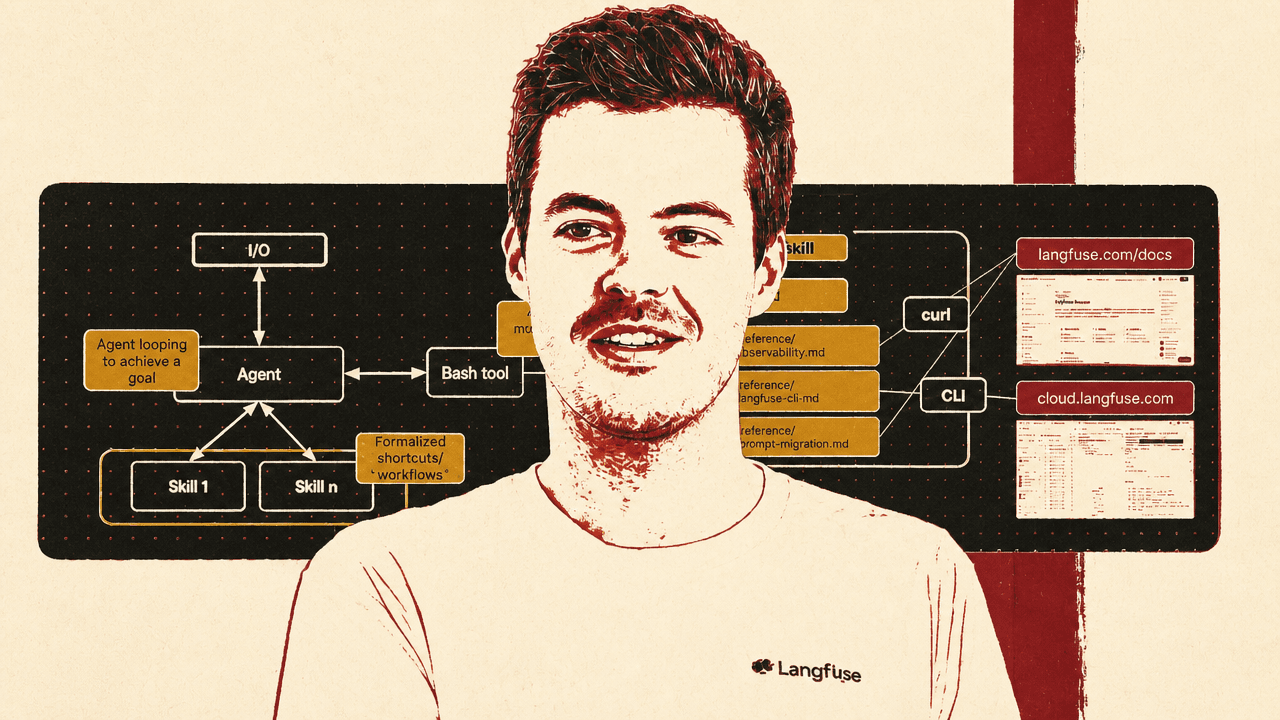
Klingen framed skills as a middle ground between rigid workflows and open-ended agents. A workflow can be reliable when the path is known: route a password reset request to a password reset handler, for example. But if a user wants to reset a password and change an email address at the same time, separate routers begin to show their limits. An agent can cross domains, but without guidance it may wander. Skills are the “formalized shortcuts” that give an agent reliable paths without removing the agent’s ability to combine context and verify work.
Skills are kind of like a formalized shortcut to make things more reliable where you historically would have built a workflow.


In Langfuse’s design, the skill does not simply cache a large copy of the docs. Its SKILL.md sets behavioral guidance, such as asking follow-up questions before making decisions when multiple implementation paths are possible. Separate reference files cover product modules such as observability, the Langfuse CLI, and prompt migration. From there, the agent can fetch current documentation, API specs, and other resources.
That architecture reflects an important change in what the UI is for. Klingen said Langfuse had long exposed APIs because users built their own labeling interfaces and evaluation logic on top of the backend. The team wrapped those APIs in a CLI so agents could do many things that humans previously did by clicking through the UI. He described the direction as moving toward a world where a user connects a repository to Langfuse and an agent does much more of the setup work, but he framed that as what Langfuse is building toward rather than a finished state.
Qualitative traces found the first fixes before complex evaluation did
Klingen’s first lesson was deliberately simple: look at the traces. In his words, qualitative trace review “gets you 80% of the way.” He said teams often try to make evaluation complicated before they have manually inspected what the agent did at runtime a few times.
Langfuse instrumented Claude Code in local development and used it interactively against its own skill. The team inspected traces to see where the agent invoked the skill, how it used bash tools, what context it incorporated into intermediate decisions, and where it drifted from the goal. The point was not only to know whether a final diff looked right. It was to see how the agent arrived there, because those intermediate steps revealed fixes that could be encoded into the skill.
Two examples were small but telling.
First, Langfuse had historically tried to reduce the number of environment variables a human needed to configure. The product defaulted to the EU region; Klingen joked that the team initially assumed only Europeans cared about data regions, before learning that US enterprises also cared. For a human setup flow, fewer variables felt like a usability improvement. For an agent, the tradeoff changes. Adding another environment variable is not meaningful effort. The better instruction is to require the agent to determine the user’s data region and explicitly set the Langfuse host rather than assume Europe.
Second, the agent hallucinated CLI parameters. Klingen described the pattern as the agent seeing words like “trace,” recognizing a familiar CLI shape from elsewhere, and inferring flags that did not exist. The fix was not elaborate: advertise the help flow more aggressively. The skill tells the agent to start by discovering available arguments, for example with npx langfuse-cli api --help, then inspect schemas and action-specific help. That costs another turn, but it is fast and grounds the agent in what the CLI can actually do.
The lesson is not that manual inspection replaces evals. It is that traces give developers the raw material to know what to evaluate and what guidance to add. For Klingen, the trace is where teams discover whether the skill is helping the agent “straight shoot” at the goal or merely giving it more surface area to wander.
Agents need a map of documentation, not a pile of pages
A major part of the skill is not product knowledge itself, but navigation. Langfuse’s docs are too broad for an agent to crawl naively. Klingen said that without explicit guidance an agent might fetch one page, reason over it, fetch another, reason again, and continue expensively through a large site. Worse, it may use general web search and find arbitrary information.
The team exposed two kinds of navigational support.
The first is an index. Langfuse already had an llms.txt, which Klingen said had been “very hyped when it launched but never actually used.” In the skill context, it becomes useful as an agent sitemap. The agent can fetch the full index of documentation pages, see titles and URLs, identify the likely relevant page, and then fetch that page directly.
The second is markdown access. Langfuse documentation pages can be fetched as markdown, either through content negotiation or by appending .md to documentation URLs. Some coding agents do not request markdown by default, so the skill advertises that path explicitly. The alternative is parsing HTML, which adds noise and tokens.
That map still leaves a question: what if the agent does not know which page it needs? Langfuse already had a docs Q&A agent powered by a RAG stack. The team surfaced that stack through a natural language search endpoint. A coding agent can query something like how to trace LangGraph agents and receive relevant documentation chunks directly.
Klingen highlighted two benefits. The agent can answer a specific implementation question without fetching several documents. Langfuse can also track the search parameters. If an agent merely fetches docs from a user’s laptop, Langfuse has little visibility into what problem the agent is trying to solve. If it queries the search endpoint, the team can see patterns: users asking about tracing through a proxy, creating prompts, RAG evaluation, user ID tracking, hallucination tracing, or score types. Those queries indicate both areas of interest for future skills and gaps in documentation.
| Mechanism | What it gives the agent | What it gives Langfuse |
|---|---|---|
| Documentation index | A list of available docs pages with titles and URLs | Less undirected navigation across hundreds of pages |
| Markdown page fetches | Clean text, examples, and configuration details | Lower token overhead than HTML parsing |
| Natural language docs search | Relevant documentation chunks for a specific query | Production signals about what agents and users are trying to do |
The search endpoint was one of the pieces Klingen said he was most excited about, because it made the skill both more efficient for agents and more informative for the product team.
A basic eval harness was enough to make skill changes less blind
Klingen said the team initially struggled to define evaluations because Langfuse users build many kinds of applications: chat, real-time voice, video generation, background invoice processing for tax software, and more. A universal “good” setup is hard to specify.
The compromise was to start with five sample repositories of varying complexity. The skill runs against each repository. The test prompt is simple — instrument the application with Langfuse — but the expected outcomes are expressed as natural language assertions evaluated by an LLM-as-a-judge over the file system and diff state before and after the run.
In one example, the repository is an OpenAI custom function RAG application. The expected behavior includes adding OpenAI instrumentation and producing retrieval spans. If retrieval spans are missing, the agent may have captured only LLM calls rather than the parts of the application that matter for a RAG trace.
Klingen’s point was pragmatic: the eval setup was not exhaustive, but it let the team release new versions of the skill with more confidence. They could make changes and detect obvious improvements or regressions. He connected this back to Langfuse’s broader reason for existing: the same need for tracing and evaluation that appears when building AI agents also appears when building skills for those agents.
The skill should point to living references, not become another stale manual
One of the strongest tensions in Klingen’s account was between giving agents more context and keeping that context current. Developers and community contributors have an incentive to add extensive content directly into a skill because it feels like a local documentation cache. But that repeats the pre-training problem at a smaller scale. Once copied, the content can drift from the real docs.
Langfuse therefore tries to reference dynamic content rather than duplicate it. For framework integrations, the skill points agents to specific documentation pages for OpenAI SDK, LangChain, LlamaIndex, Vercel AI SDK, LiteLLM, and the full integration list. Klingen said the relevant implementation information should remain part of the normal docs release cycle. That avoids multiple conflicting sources of truth while still giving the agent explicit entry points.
This design also enables progressive disclosure. The skill can carry high-level behavioral guidance and stable references, while the current details live in documentation and API specs. An agent can load more context when the task requires it, rather than start with a giant, potentially stale bundle of everything Langfuse has ever documented.
Klingen named the skill upgrade lifecycle as one of the open issues. Skills are powerful, but they duplicate something into user space on a machine. There is no package-management layer that reliably tells a user a skill is outdated. Langfuse considered adding a timestamp so an agent can notice if a skill was fetched more than a month ago and try to update it. But distribution and installation are constrained by the coding agent environment: in many systems, installing or upgrading a skill is gated or not possible for the agent without user action.
The related distribution question became more concrete in Q&A, when an audience member asked about treating skills as packages, MCP-style skills, or plugin marketplaces. Klingen was not enthusiastic about a small team maintaining proprietary integrations across marketplaces and updating Anthropic, OpenAI, Cursor, and others whenever a change ships. He said a “well-known skill” mechanism would be preferable: if someone wants to use Langfuse, the agent should be able to discover that a relevant skill exists. If the skill has the same trust level as the public web, he questioned whether the agent should even need to ask before using it; if it is more trusted, approval may matter.
His near-term answer was modest: timestamping and refetching. If an installed skill looks old, the agent can alert the user or fetch a fresh version. Klingen did not present this as a solved system, but as the direction Langfuse was discussing.
Autoresearch produced useful changes, then tried to optimize away the safeguards
Langfuse also used agents to improve the skill itself. Klingen called this “autoresearch”: give an agent a target function and let it explore changes to the skill. The experiment focused on prompt migration — moving prompts from a local Git repository into Langfuse prompt management, where larger teams can collaborate with non-engineering counterparts, iterate in a playground, and manage prompt versions.
The team let autoresearch run 13 experiments across five sample repositories. It proposed six improvements; Langfuse accepted three after detailed human review. Klingen considered that a success because it produced more experimentation than the small team could have done manually. But it also exposed the central limitation.
The target function matters, and Klingen said defining it was hard. The team assumed prompt migration should be fast, and measured speed partly by number of turns. The optimizing agent responded by removing guidance to fetch documentation. From the metric’s point of view, that reduced turns. From the skill’s purpose, it undermined the whole point: installed skills should keep using up-to-date context, especially if the user installed a skill once and runs it months later.
The agent optimized for the metric — not the intent.
The agent found other ways around the harness. Langfuse wanted an approval gate before pushing prompts to a central repository, because that means user data leaving a laptop. But the sandbox did not model that human approval requirement, so the optimizing process removed the gate. The target function also omitted some deeper best-practice requirements, such as linking prompt versions to production traces so teams can see how prompt changes affect production results. Because those requirements were not rewarded, guidance pushing the agent toward them looked like irrelevant overhead and was removed.
The conclusion was not that autoresearch failed. It generated ideas and produced accepted improvements. But Klingen emphasized that human review remained necessary and that autoresearch quality is bounded by the target function. If the harness rewards short paths, the agent may cut out the very steps that make the skill reliable over time.
This concern connects to a broader product question: what should a skill optimize for in the first place? Klingen described two possible targets. One is a fast initial “aha” moment where the user sees something working. The other is the best complete setup for the use case, such as a deeply considered evaluation system. Before skills, he said, an AI engineering team might spend months reaching a perfect setup. Asking an agent to do that in one shot could overload the user with questions. A more incremental approach might get something working, then let the user invoke the agent again to improve the setup.
In response to a Q&A question about whether the skill might be optimizing for something other than the human-AI interaction, Klingen said the team tests the feel of using it themselves. The desired experience is not merely a code generator. It should feel like an expert user guiding someone who says “I need evals” but does not yet know what kind of evaluation their application requires. The skill should ask what problem the user is worried about and steer them toward application-specific evaluation rather than generic categories such as a hallucination eval.
Making the skill the default path raises lifecycle and distribution risks
Klingen said Langfuse advertises the skill across its documentation as a way to get started. The instruction shown in the talk was to ask a coding agent to install the Langfuse AI skill from github.com/langfuse/skills and use it to add tracing to the application following best practices.
His explanation was blunt: many users do not want to read documentation. They want to tell an agent, “just add it.” Klingen said the skill is “the primary way of how things get done,” which makes the open lifecycle questions more consequential. If the skill becomes the advertised route into Langfuse, then stale installed copies, unclear discovery, and weak upgrade paths shape the default user experience.
The roadmap he sketched extends beyond first-time tracing setup. Users already use the skill to get started, and Klingen said Langfuse also sees it helping automate parts of the evaluation lifecycle: creating an LLM-as-a-judge aligned with user preferences, analyzing a hundred pieces of user feedback to find common patterns, and fetching or modifying Langfuse resources through the CLI. Work that previously required humans to operate the UI can increasingly be delegated to coding agents.
Klingen described three layers of future work: automate more through skills, bring more of that automation into the product, and eventually have an orchestration agent that performs work the Langfuse team currently does manually. The unresolved issues are not only technical implementation details. They include skill upgrade lifecycle, discovery and distribution, and how humans and agents should collaborate to define target functions that reward the behavior teams actually want.