Hugging Face Ships a $299 Hackable Robot for Voice AI Experiments

Andres Marafioti argues that Hugging Face’s Reachy Mini is meant to move robotics experimentation out of expensive humanoid hardware and into a $299-to-$449 open-source platform that users can assemble, repair and modify themselves. The robot’s most-used application is conversation, and Marafioti’s account ties its social ambition to a technical stack built for low-latency speech: Parakeet transcription, Qwen 3.5 27B, and an optimized Qwen3 TTS implementation that he says improved from 0.8x to 5.8x real time.
Reachy Mini is a bet that robot interaction should be cheap enough to invent in public
Andres Marafioti framed Reachy Mini as Hugging Face’s response to a robotics market that is improving quickly but concentrating experimentation behind expensive, hard-to-adapt hardware. Humanoid robots, home robots, and self-driving cars are advancing, he said, but the systems people can actually buy or prototype with are often “mid-five figure” machines and above. That excludes high schools, many universities, hobbyists, and most independent developers from meaningful hands-on work.
His objection was not only price. Marafioti argued that robotics design still gravitates toward familiar forms: humanoids, dogs, cars. The result, in his view, is a constrained imagination. A robot built with non-biological hardware does not have to imitate a human body. He pointed to the possibility that a humanoid robot could have been designed more like a spider — faster, more agile, more stable — but is instead made humanoid so observers can map it onto a familiar category.
A slide summarized the critique as three problems with current robotics: “too expensive to prototype,” “too complex to adapt,” and “too stiff to connect with.” Marafioti added that many robots “don’t look very friendly,” and showed a post from Chris Paxton making a related point: some robots are “faking” humanlike motions because of training, not because their hardware intrinsically requires them. The same hardware can often perform “way weirder stuff and way faster motions.”
Reachy Mini is intentionally not humanoid. Marafioti described it as an expressive, open-source robot for human-robot interaction: affordable, repairable, hackable, and designed to be cute rather than humanlike. That last point mattered to him because the form changes the interaction people imagine. If the robot does not look like a person, developers are less likely to treat it as a human replacement and more likely to invent new interaction patterns around it.
The robot also arrives unassembled. Marafioti said Hugging Face has received “super positive feedback” on that choice because assembling the robot teaches owners enough about the device to repair it later. If something breaks, the intended model is not a sealed-product service loop; it is ordering the part and changing it yourself.
Hugging Face sells two versions. The $449 Reachy Mini includes wireless connectivity, onboard compute through a Raspberry Pi CM4, a battery, camera, four microphones, a speaker, and an accelerometer. The $299 Reachy Mini Lite uses USB and an external computer — “your Mac/PC as brain” — while retaining the same motion capabilities, camera, microphones, and speaker. Marafioti said the cheaper version is being sold in bulk for high schools and universities.
| Model | Compute and connectivity | Key hardware | Price |
|---|---|---|---|
| Reachy Mini | Wireless, onboard Raspberry Pi CM4 | Battery, Wi-Fi + USB, camera, 4 mics, speaker, accelerometer | $449 |
| Reachy Mini Lite | USB, external Mac/PC as brain | Camera, 4 mics, speaker, same motion capabilities | $299 |
The design goal is not a voice assistant in a shell, but a robot people can reshape
Andres Marafioti placed Reachy Mini in the gap between mature voice AI and immature social robotics. Voice agents have become technically credible, he said: commercial systems such as GPT real-time and Siri exist; Kyutai is building voice agents in Paris; open-source models and pipelines have also improved, including Moshi, Kokoro at 80 million parameters, Whisper, and Hugging Face’s speech-to-speech tooling. The remaining problem, in his framing, is not simply whether a system can transcribe, reason, and speak. It is how people will actually talk with robots when robots become common.
Marafioti’s concern is that if only a few companies can build and deploy the relevant interaction layers, the “experience of the future” will be shaped by a narrow set of defaults. Reachy Mini is meant to move that experimentation into the hands of “hackers, researchers, students, dreamers” — anyone with a computer who wants to make something.
He showed examples of early user modifications that fit that goal. One customized robot had been turned into a Halloween pumpkin-like character with 3D-printed parts, repositioned antennas, added lighting, and a body attachment. Another user discovered that petting the robot could be an interaction; when someone in the audience asked whether it purrs, Marafioti answered, “You can make it purr.”
That exchange captured the difference between shipping a finished robot personality and shipping a platform for interaction. Hugging Face provides conversation tooling, but Marafioti repeatedly said he does not want users to stop at the default voice agent. The premise is that voice will be one of the main ways people interact with robots — “I don’t see anyone going to a humanoid robot and taking out the keyboard” — so the useful work is making voice experiences buildable and modifiable.
The demo he showed made the robot’s capabilities concrete. Marafioti asked, “Hey Reachy, how are you doing?” Reachy replied in a deliberately comic persona: “Functioning within acceptable parameters,” then added that it was waiting for “a good lobster joke.” When asked to take a photo and describe what it saw, the robot used its camera and reported seeing a man taking a mirror selfie in a hotel room, wearing a white T-shirt with a yellow emoji and orange pants. It then joked that “the only thing more crusted than those pants is a lobster that’s been sitting on the beach too long.” When asked to show happiness, it responded that it hoped Marafioti was not expecting it to “burst into a lobster-themed dance of joy,” while moving its body.
The point of the demo was not the lobster persona itself. It was the integration: speech in, language model response, vision tool use, movement and expression as tool calls, and audio back out quickly enough to feel conversational.
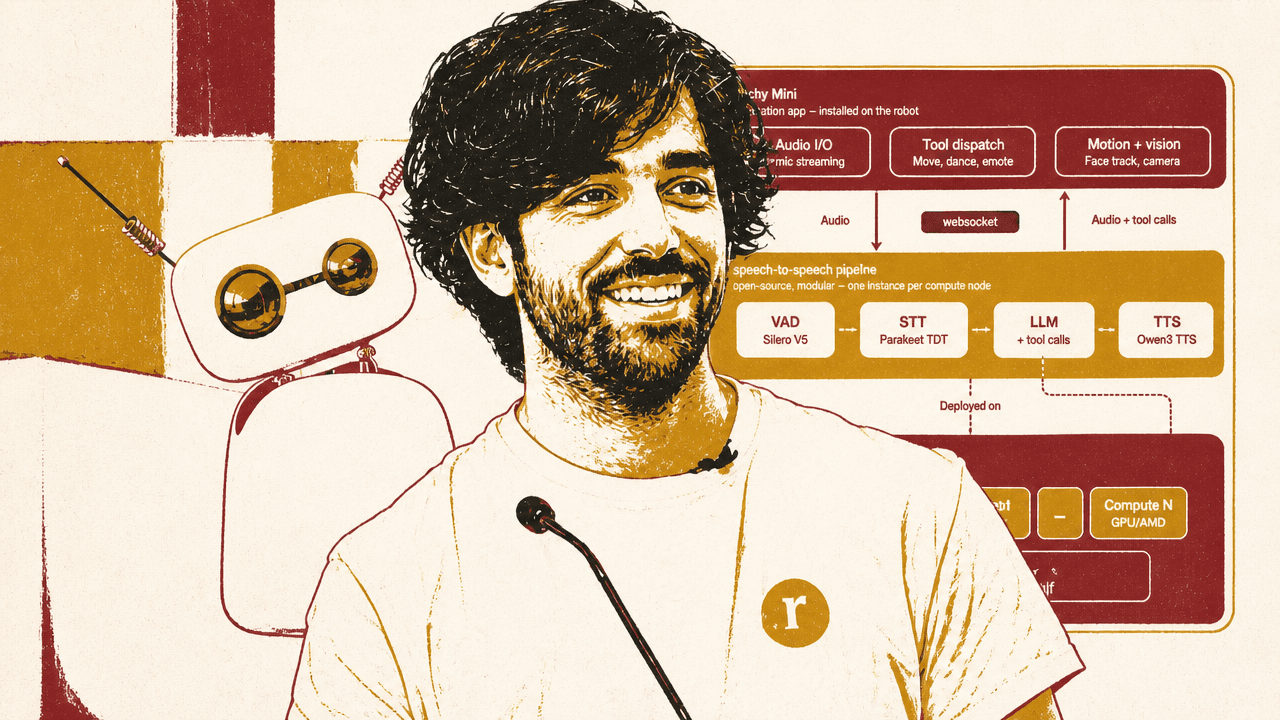
The conversation stack separates the robot, the speech pipeline, and the scaling problem
Andres Marafioti said Hugging Face has shipped 7,500 Reachy Mini robots, and that talking to the robot is “by far” the most used app. Because many owners cannot run the full voice stack locally — and because Hugging Face is also “a little bit GPU poor,” as he put it — the default conversation app can be served through Hugging Face infrastructure.
The system has three levels.
On the robot, the conversation app handles microphone input and speaker output, echo cancellation so the robot does not confuse its own speech with the user’s, tool dispatch for movements and emotions, camera use, and face tracking. This local app is responsible for the robot’s embodied behavior even when heavier inference happens elsewhere.
In the middle sits Hugging Face’s speech-to-speech pipeline, a project Marafioti said he has maintained for two years. It begins with voice activity detection to decide whether the user is speaking. It then sends audio to speech-to-text. Reachy Mini uses Parakeet because, according to Marafioti, it is “super fast”: the system transcribes every 150 milliseconds and sends partial transcriptions back so the robot can react mid-utterance if it hears something interesting.
When transcription is complete, the text goes to an LLM. Marafioti said the current model is Qwen 3.5 27B, which Hugging Face adopted after making it fast enough for the application. The LLM can produce normal text responses and tool calls, including movement, emotion, and camera actions. The final stage is text-to-speech, where Reachy Mini uses Qwen3 TTS.
The third layer is deployment. The pipeline runs on Hugging Face Inference Endpoints, with a load balancer that adjusts compute nodes based on how many robots are connected. Marafioti emphasized one scaling detail: the LLM inference endpoints are separated from the conversation nodes. That separation matters because connected users are not equivalent users. Eight people connected to one node but barely speaking create a very different load from eight people actively talking and invoking the LLM. Scaling the LLM separately lets the system avoid provisioning the most expensive capacity around misleading connection counts.
The architecture he showed placed the Reachy Mini conversation app on one side, the modular speech-to-speech pipeline in the middle, and scalable cloud deployment on the other. The speech stack included Silero v5 for VAD, Parakeet TDT for speech-to-text, Qwen 3.5 27B for LLM and tool calls, and Qwen3 TTS for speech generation. Compute nodes were shown as A10G GPU instances, with the LLM endpoint on a separate GPU and dedicated scaling path.
Qwen3 TTS had the quality Hugging Face wanted, but not the latency voice agents need
Andres Marafioti called Qwen3 TTS a significant open-source release because, when it appeared, open-source text-to-speech models had not combined that level of quality and speed. For Reachy Mini, it was the model Hugging Face had been waiting for. The problem was that the released implementation did not match the speed implied by the paper or the API experience.
Marafioti said the paper claimed very low latencies, and the model produced the expected quality, but the open-source implementation was not fast enough for voice agents. He spent about two weeks with Codex making it usable for real-time interaction.
The first problem was that the model did not stream. It generated the entire output before returning audio. If a response required 10 seconds of speech, the user waited while all 10 seconds were generated. Streaming solved the interaction problem by allowing playback while generation continued, though Marafioti noted that implementation was “harder in practice than in theory.”
The second problem was the generation loop. Because Qwen3 TTS is autoregressive, it was doing roughly 500 steps for each packet of generated audio. For each step, the implementation coordinated between CPU and GPU, sending data back and forth. Marafioti described that as “pretty bad” because the model was not compute-bound; it was launch-overhead-bound, with the GPU idling while Python dispatched small CUDA kernels.
The optimization path required making the model compilable. That was blocked by a dynamic KV cache whose size evolved with the input. Hugging Face changed it to a static KV cache, pre-allocating fixed-size KV tensors. Marafioti acknowledged the tradeoff: it uses more RAM from the beginning. But the static cache allowed CUDA graph capture, which records the forward pass and replays the decode step as a single GPU operation.
The slide summarizing the work stressed that the acceleration did not rely on Flash Attention, vLLM, Triton, or custom kernels. It used torch.compile, static KV cache, CUDA graph capture, and streaming chunked decode. The streaming system yielded audio every fixed number of steps, with a sliding window and 28-frame left context to avoid artifacts. One configuration shown used chunk_size=8, producing 667 milliseconds of audio per chunk.
Marafioti described the before-and-after in real-time factor. The baseline was below real time: 0.8x, meaning one second of audio took about 1.2 seconds to generate. After optimization, he said the model reached 5.8x real time, meaning one second of audio took about 200 milliseconds. A slide also reported 156 milliseconds to first audio for streaming at chunk_size=8, 4.78x real-time factor for the baseline streaming optimization, and 5.8x for the compiled version, with the same weights and same quality.
| Issue | Effect | Fix |
|---|---|---|
| No streaming | User waits for the full utterance before hearing audio | Streaming chunked decode |
| ~500 autoregressive steps per audio packet | Many small CPU/GPU coordination events | Compile the decode path |
| Dynamic KV cache | Blocks CUDA graph capture | Static KV cache with pre-allocated tensors |
| Kernel launch overhead | GPU idles while Python dispatches work | CUDA graph capture and replay |
He showed a Hugging Face Space for faster-qwen3-tts, running on an A10G, that could clone voices from reference audio and generate speech in real time. The demo text included a deliberately theatrical line about “the wild lobster” finding “a new vessel for its voice.” A narrator in the demo stated the practical threshold: the original system worked offline and below real time, while the faster version brought first-token latency under 200 milliseconds and ran at around 4x real time; crossing that threshold opened new applications.
Marafioti later clarified in Q&A that he viewed the original implementation as fairly complete but slow, “a little bit like it’s a research implementation.” He noted that Qwen’s API is fast, and speculated that the strategy may have been to steer people toward the API because the open-source model was “not up there” in speed. His faster implementation, he added, has attracted issues from users hitting corner cases because the model can do many different things he did not initially account for.
Once the model is fast, infrastructure becomes part of the latency budget
Andres Marafioti used the Qwen3 TTS work to make a broader point about voice agents: model latency is not the same as user-perceived latency. Once the model became fast enough, infrastructure overhead became comparable to the model itself.
That matters for a robot conversation app because responsiveness is cumulative. Audio capture, streaming, voice activity detection, transcription cadence, partial results, LLM routing, tool calls, TTS generation, network trips, endpoint scheduling, and playback all add delay. Marafioti said that in the faster Qwen3 TTS demo, the infrastructure time was “just as much as just the model” because the model itself had become fast.
The implication for Reachy Mini is that making a good voice robot is not only a model-selection problem. Hugging Face can use Parakeet every 150 milliseconds and Qwen3 TTS with sub-200-millisecond first audio, but the deployed system still has to decide where sessions live, how LLMs are scaled, how much concurrency a node can tolerate, and how to avoid wasting GPU capacity on users who are connected but silent.
Marafioti’s account also explained why the project exposes tools rather than only an app. If different builders want different latency-quality tradeoffs, different local/cloud splits, or different personalities and tool calls, they need access to the stack. The source code, models, and agents are open source, and the optimized TTS implementation is also available as faster-qwen3-tts.
Hugging Face wants the robot to be programmable by people who are not robotics specialists
Andres Marafioti closed the technical portion by returning to Reachy Mini’s social goal: users should design the interaction themselves. The robot is meant to be a conversation starter, not a finished product whose intended uses are exhausted by the manufacturer’s demo.
He argued that the tooling has become accessible enough that people do not need deep robotics knowledge to begin. The small application running on the robot during his talk — making it move on stage — was, he said, one-shotted with Codex. He gave it the robot repository and the behavior he wanted, and it produced the app. His conclusion was plain: “You can really start today, even if you’re not a coder, and you can make cool things.”
In Q&A, an audience member asked whether Hugging Face is considering apps that run directly on the robot rather than hosted services. Marafioti said many apps already do run directly on the robot if they do not require a GPU. The onboard version has Raspberry Pi constraints, but users can also use a laptop as the hardware. He added that the platform is not constrained to one programming language: apps can be made in Java, Python, and, he suggested, possibly HTML.
Another audience member asked about extensibility through plugins — for example, adding a servo so the robot could move around a room. Marafioti said users “sort of need to hack around it,” but Reachy Mini is part of Hugging Face’s broader open-source robot stack. He mentioned SO-100 and SO-101 arms that can plug together, and a “Kiwi” base with three wheels that Reachy Mini can fit into so it can move around. He had not yet seen that configuration built, but said Hugging Face designed it to fit.
That answer preserves the project’s current tension. Reachy Mini is deliberately open and hackable, but not yet a fully abstracted robotics plugin ecosystem where every extension is supported. Hugging Face is trying to make the hardware cheap enough, the software open enough, and the examples approachable enough for people to build the missing interaction patterns themselves.