Spotify Uses Semantic IDs to Make LLMs Recommend Catalog Items
Spotify’s Shivam Verma argues that LLM-era personalization requires translating both users and catalog items into forms a model can process alongside language. In his account, Spotify combines long-term user embeddings, Semantic IDs that turn tracks and episodes into token sequences, and soft tokens that project a listener’s profile into an LLM’s embedding space. The aim is a generative recommender that can produce catalog-native recommendations without full fine-tuning, while still relying on traditional ranking layers for production use.
Spotify is adapting recommendations to work inside LLM-style systems
Shivam Verma describes Spotify’s personalization work as a shift from conventional recommender-system pipelines toward a model stack that can combine user history, catalog knowledge, and natural-language steerability inside LLM-style systems.
The goal is not simply to place a chat interface beside existing recommendations. Verma frames the work as “context engineering on the modeling side”: turning user behavior and catalog items into representations that a model can use in the same computational space where it processes prompts and tokens.
Spotify’s scale is the operating constraint. Verma cites more than 750 million monthly active users, more than 100 million music tracks, roughly 350,000 to 400,000 audiobooks, millions of podcast titles, 250,000 video podcasts, and availability across 184 markets. A personalization system at that scale has to represent both sides of the marketplace: what a user tends to like, and what the catalog contains.
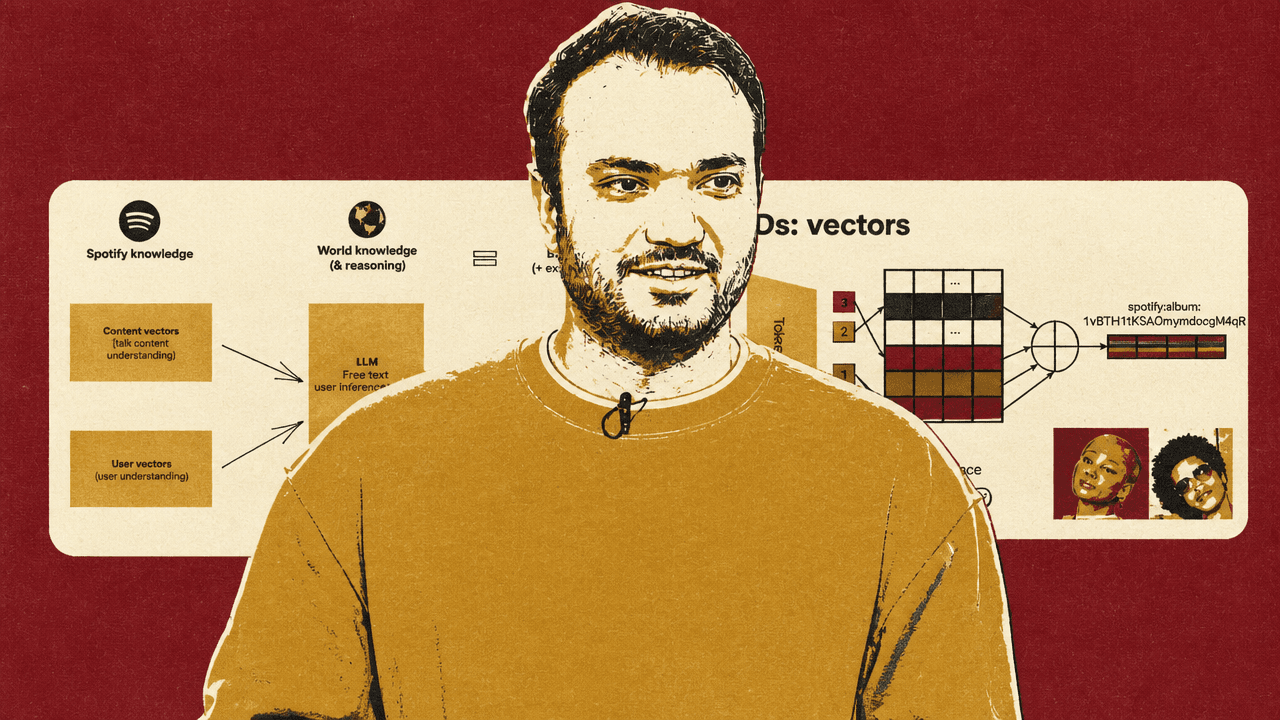
He breaks Spotify’s LLM-era recommendation architecture into three pieces. First, foundational user modeling turns sequences of user actions into vectors. Second, catalog grounding turns content vectors into tokens that an LLM can consume and generate. Third, a soft-token personalization layer projects a user representation into the LLM’s token space, giving an adapted model user-specific context at generation time.
That sequence — actions to vectors, vectors to tokens, vectors plus tokens to LLMs — is the through line. It is how Verma says Spotify is moving from product-specific recommendation systems toward a more unified, steerable, personalized generative recommender.
Traditional recommenders narrowed millions of items before ranking; Spotify wants a more unified model
Verma contrasts the new direction with what he calls “TradRecs,” the traditional recommender-system paradigm that has dominated large-scale recommendation products. In that setup, a massive item catalog is narrowed through candidate generation, reducing millions of possible items to hundreds. A ranking stage, sometimes with multiple rankers, then orders those candidates into the final set shown to the user.
At Spotify, Verma says this pattern has been used across surfaces including home shelf ranking, personalized playlists, search, music and podcast feeds, audiobook feeds, the now-playing view, autoplay, promotions, ads, and premium conversion. But it has also tended to produce organizational and modeling silos: each product has its own team, its own model, its own feature set, and uneven model quality.
The LLM-era direction is different. Verma says Spotify is moving toward “this single unified model” with an LLM backbone, in which the user can steer recommendations more directly. That steerability already appears in product surfaces such as AI DJ and prompted playlists. He says prompted playlists can generate custom playlists from user prompts, and that as of the week of the talk the feature also supports podcasts, allowing a user to ask for a playlist of episodes.
Taste Profile is the more explicit control surface. Verma describes it as a way to expose what Spotify knows about a user and then let the user decide which parts Spotify should keep or forget. The feature was available only in a few markets at the time of the talk, with planned expansion later in the year. The product idea is tied to the modeling idea: if users can express preferences in natural language, the recommender should be able to absorb those edits into its representation of the user.
User embeddings are Spotify’s base layer for personalization
The first technical component is user modeling. Verma’s team, User Representations inside Spotify’s AI Foundation organization, builds user embeddings: vector representations of a person’s taste based on their history across Spotify sessions and surfaces.
Those embeddings are not a side feature. Verma describes them as the foundation for downstream models that recommend content or support search. A slide says Spotify generates user embeddings for more than a billion users daily; Verma explains that this count includes users beyond the monthly-active-user population. He calls the pipeline massive and expensive.
The earlier paradigm was a generalized user representation model. Verma points to an autoencoder-style architecture described publicly by Spotify’s team: features about a user are compressed into a smaller vector and then reconstructed. That compression-decompression process forces the model to learn a compact representation of user interactions. Verma notes that this pattern is familiar from NLP, computer vision, and recommendation systems more broadly.
Spotify is now moving toward sequential user models built with transformers. In this frame, the user’s interactions become part of the prompt-like context. The model also receives request context, the query or prompt, the product surface, and the item being considered. Verma describes the setup as training over millions or hundreds of millions of users’ data with transformer layers and task heads.
The result, in one visualization he shows, is a shared embedding space containing users, tracks, and podcast episodes. The slide plots tracks, podcast episodes, and users as colored points in the same projected space, with callouts for specific podcast episodes and a user node. Verma uses his own embedding as an example: as a machine-learning engineer who follows Anthropic and the technology industry, his user point appears close to a Big Technology Podcast episode about Dario Amodei and AI. The point of the visualization is not the exact two-dimensional layout, but the claim that the model learns a joint space where users and content can be compared, clustered, and explored.
This is the first piece of the personalization stack: a vector that represents a user’s long-term behavior, rather than only the most recent items that can fit into a prompt.
Semantic IDs let an LLM treat catalog items like tokens
The second component is catalog grounding: teaching an LLM what Spotify’s catalog items are, in a form that the model can use natively.
Spotify already has content vectors for tracks, artists, podcast episodes, and other entities. Separately, open-weight LLMs such as LLaMA or Qwen bring world knowledge and language reasoning. Verma says Spotify fine-tunes these models so they can combine that world knowledge with Spotify-specific knowledge. The benefits he names are steerability, better recommendations, and explainability. He also names the tradeoff: catastrophic forgetting can be an issue when models are adapted.
The mechanism he emphasizes is the Semantic ID. A Semantic ID compresses a high-dimensional content vector into a short sequence of discrete token IDs. Verma compares the process to how LLMs tokenize words, except the thing being tokenized is not text but a content embedding for a track, artist, album, or podcast episode. He attributes the concept’s earlier use in a YouTube context to a Google paper, but does not make that origin central to Spotify’s implementation.
In one example, Spotify represents Ariana Grande and Bruno Mars as six-token sequences:
| Artist | Semantic ID tokens |
|---|---|
| Ariana Grande | 2779, 1233, 2414, 2003, 2161, 1945 |
| Bruno Mars | 2779, 1233, 2649, 1224, 2335, 2673 |
The first two tokens are shared because, as Verma explains it, both are pop artists and share something semantically. The remaining tokens diverge to capture more specific distinctions. He describes the structure as hierarchical: a content embedding is compressed into a short token sequence whose prefix can represent broader similarity and whose later tokens capture narrower differences.
That matters because the LLM can then be trained autoregressively over catalog-native tokens. Instead of predicting only the next word, it can learn to predict the next song, artist, or episode as a sequence of semantic tokens.
The next token is not a word but it's the next song or it's the next episode that you're going to be listening to.
Verma describes this as continued training or post-training of open-weight LLMs on Spotify data. The model learns “to speak Spotify’s language”: user context comes in, recent listening history is represented as Semantic IDs, and the model outputs valid and coherent Semantic IDs that can be mapped back to Spotify URIs. Downstream ranking can still apply business-specific policies after the model generates candidates.
He gives an Italian podcast example. A conventional prompt might include raw Spotify episode URIs in a user’s listening history, along with country, age, and language. Spotify converts those item references into Semantic IDs, which are the tokens the model actually attends to, and asks the model to recommend the next episode the user would like to stream. In the slide example, the user is from Italy, age 36, speaks Italian and English, and the output is an Italian podcast episode.
The catalog-grounding process has three steps in Verma’s account: create embeddings from content text such as a title and description; quantize the vector into a Semantic ID; place those Semantic IDs in the LLM context so the model can generate text and new item tokens.
Personalization still requires user context the LLM cannot memorize
Catalog grounding alone is not enough. Verma argues that an LLM needs user context to generate the “right” tracks or episodes for a particular person. A generic prompt such as “the best R&B pop covers” can produce plausible but non-personalized results. With user context, the result can shift toward what a particular listener is likely to prefer.
The difficulty is scale. Verma says the model cannot be trained on every detail of more than 750 million users. Some collaborative-filtering-style generalization is possible, but individual personalization requires a compact user signal at inference time.
Spotify’s answer is to bring back the user embedding — the long-term vector representation trained from months and years of consumption history — and project it into the LLM’s embedding space. Verma calls the result a soft token: a token-like representation of the user that is inserted into the prompt, but derived from a vector rather than a text token.
The soft token is meant to solve the prompt-budget problem. An LLM prompt can include recent listening, explicit user context, a query, and Semantic IDs, but it cannot contain a user’s full long-term history. The user representation is a lightweight substitute for that history. It can sit inside a prompt structure alongside text fields such as topic and recent listening.
Verma’s schematic is simple: a user vector passes through a projection layer; text passes through the tokenizer; both enter the LLM; the model produces a target recommendation. Because the projected user vector is present when the recommendation is generated, the LLM’s output can be personalized for that user.
This is also where Taste Profile fits technically. Verma describes Taste Profile as text representing who the user is, exposed back to the user. If a user says they want to listen to more Justin Bieber, or that they dislike a particular podcast recommendation, that edit can return to the generative model and improve its understanding of the user.
Early next-episode results show gains from prompts and soft tokens together
Verma presents internal early results for next-episode recommendation, using a podcast discovery feed dataset with 2 million episodes. The task is structured around previous episode, user-context prompt, and next episode. The evaluation metric is HitRatio@30. The base model is PRISM v3 1B, fine-tuned for next-episode recommendation, with supervised fine-tuning for two epochs on the 2 million-example dataset.
The user-context prompt format includes country code, age, spoken languages, and top recently streamed podcasts represented with Semantic IDs and artist lists.
| Context | HR@30 | Vs. without context | Vs. random context |
|---|---|---|---|
| Baseline | 16.10% | - | 0 |
| Soft token | 16.46% | 2.23% | 1.60% |
| Prompt | 17.76% | 10.31% | 12.40% |
| Soft token + Prompt | 18.30% | 13.66% | - |
The table supports a narrow claim: in this setup, both prompt context and soft-token user context improve HitRatio@30 relative to the baseline, and the combination performs best among the shown configurations. Verma characterizes the results as “pretty positive” on internal metrics.
He also says this is not only a research prototype. If a listener uses Spotify’s podcast next-episode recommendations, Verma says the recommendation is coming from “something like this.” He does not present the production system as identical to the tabled configuration, but he does say the next-episode recommendation capability has been productionized.
The new stack does not eliminate traditional ranking
Verma’s final position is not that LLMs replace recommender systems wholesale. His summary keeps traditional recommender and sequential modeling in the picture for real-world, real-time ranking.
The architecture he presents has three modern building blocks. User embeddings represent listener taste. Semantic IDs represent compressed catalog items in a form LLMs can consume and generate. Soft-token approaches project user vectors into the model’s token space so an LLM can condition on a person without needing their full history in text.
But after an LLM generates catalog-native IDs, a receiver maps them back to Spotify URIs, and downstream ranking applies business-specific policies. That leaves room for the existing recommender-system machinery: constraints, ranking, policy, product requirements, and real-time behavior.
Verma’s larger claim is that personalization is moving toward generative recommendation: systems that understand both language and catalog structure, accept user steering in natural language, and generate recommendations conditioned on compact user representations. Spotify’s work, as he describes it, is an attempt to make open-weight LLMs reason over a music and podcast catalog using token-like catalog representations — while still preserving the practical recommender-system layers needed to serve hundreds of millions of users.