Apple-Device AI Is Becoming Viable Without Cloud Inference

Prince Canuma presents MLX, Apple’s array framework for Apple Silicon, as a practical foundation for running AI agents locally rather than through cloud services. His case is rooted in accessibility and unreliable connectivity, but extends to product constraints for voice agents, robots and multimodal apps: vision, speech, video generation and long-context inference can increasingly run on Macs, iPhones and iPads without a network call. Canuma does not argue that local models replace every frontier cloud system, but that the boundary has moved far enough to make on-device AI a serious deployment option.
On-device AI is a product constraint, not a hobbyist preference
Prince Canuma framed MLX as a way to deploy and manage AI agents, including voice agents, entirely on Apple devices. The point was not only technical independence from cloud services. His argument began with a use case where cloud dependence is structurally weak: accessibility for someone who cannot count on reliable connectivity or affordable subscriptions.
Canuma described his father losing his sight in 2020, the same year Apple released the M1. His father lives in Africa, where, in Canuma’s telling, internet access and subscription plans are not as straightforward as they are for many developers in Europe or the United States. He had promised his father he would find a way to help him read again. That pushed him toward the view that “compute on the cloud doesn’t necessarily solve all of these use cases.”
The argument for on-device inference, then, was practical before it was ideological. A blind user may need a system that can describe the world through a phone camera and respond to speech. A local agent may need to keep running without a network call. A robot may need to hear, see, and reply with low latency. Canuma’s pitch was that some of the spending and dependency associated with cloud AI can now be moved onto hardware users already own: “all you need to pay is your energy bill.”
MLX is the technical foundation for that claim. Canuma described it as “an array framework for Apple silicon,” analogous to PyTorch or TensorFlow but built for Apple’s hardware. He said he found MLX on GitHub in 2023, saw in the initial examples “a future,” and began contributing.
The slide behind that claim listed “6 Frontier Labs partners,” “1.5M+ downloads,” and “4,000+ Models ported.” Canuma said the project now works with frontier labs to provide day-zero support for open-source models, giving Gemma 4 as an example. In his formulation, the promise is that the best open-source frontier models can run on a MacBook, iPhone, or iPad rather than requiring a remote service.
Vision is the first accessibility layer
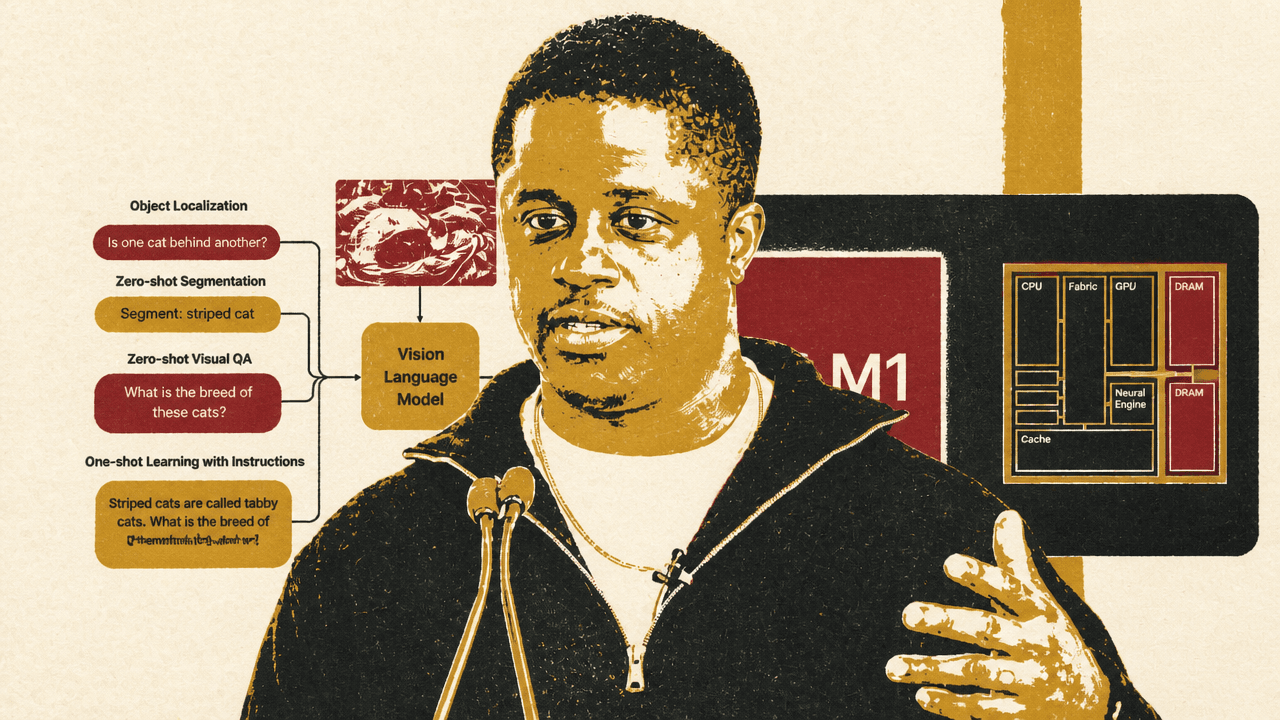
For Prince Canuma, vision was the most immediate on-device application because it addressed his father’s loss of sight. He described an earlier hackathon project involving goggles that could identify what was in front of a user. MLX VLM became, in his account, a second iteration of that idea: instead of specialized hardware, a user could point an iPhone at the world and ask what it sees.
The MLX-VLM slide placed this in the broader category of vision-language models and omni models. The visual examples included object localization, zero-shot segmentation, visual question answering, and one-shot learning with instructions. The slide’s sample tasks included asking whether one cat was behind another, segmenting a striped cat, and identifying cat breeds. The visible model response described visual relationships and recognized “Tabby cats” from an instruction.
Canuma emphasized that a blind user may not be able to type comfortably, but can speak. That makes an audio-controlled camera part of the interface, not a separate feature. He described the intended loop as speech controlling the camera, the model understanding what is in front of the user, and the system helping them decide what to do next.
He also situated MLX VLM inside existing tools. He said that if someone uses LM Studio, MLX VLM is one of the main engines powering it, and that it powers Liquid AI models and other models. The substance of the claim was not merely that image understanding can run locally, but that local multimodal inference is becoming infrastructure for developer-facing AI products.
Canuma challenged the assumption that local models must be small. He said users can now run “models of hundreds of billions of parameters” even on an initial M1 MacBook, because of community improvements, and gave the example of running Gemma 4 26B on an iPhone using storage while still getting “reasonable speeds.” He did not present this as a universal experience across all hardware, but as evidence that the practical ceiling for local inference has moved.
Audio turns local inference into an agent interface
Prince Canuma described MLX-Audio as the next step after vision. Part of the motivation was accessibility for people without full sensory ability. Part was personal: he wanted to control his computer without sitting in front of it, “the Jarvis vision of the world,” where a user can speak to a machine and have actions performed.
The MLX-Audio slide showed a modular pipeline: microphone input, speech-to-text model, language model, text-to-speech model, and audio player. It also listed TTS, STT, STS, and Python and Swift support. Canuma said the project started with text-to-speech, then led to Marvis, a custom model that can generate audio in less than 100 milliseconds. Speech-to-text allows real-time transcription. Speech-to-speech adds the computer’s ability to answer back.
Canuma argued that the modularity matters because not every device has the same budget. A developer can choose the automatic speech recognition model, the language model, and the text-to-speech model, rather than being forced into a single monolithic speech system. That allows the same general architecture to scale down to a first-generation M1 or up to newer Apple hardware.
He also made a developer-experience claim. For applications similar to Whisper Flow or Super Whisper, he said a developer could point Claude Code or Cursor at MLX-Audio and ask it to build the app, producing a version “in like 10 minutes.” The important point was not that the resulting app would be polished, but that the primitives for local speech capture, transcription, generation, and playback are now accessible enough to compose quickly.
Swift support was central to his view of the next stage. Canuma said the team began with Python because it is easier and scales faster for development, but “native experiences matter.” With Swift, he said developers can build fully native applications using audio intelligence and vision intelligence rather than wrapping everything in a prototype stack.
The demos were meant to prove locality, latency, and composability
The live demonstrations from Prince Canuma focused on what could run on his Mac without relying on a cloud service. The first was real-time image analysis using an RF-DETR model from Roboflow through MLX VLM. The command shown in the terminal ran a Python module with a real-time task and the model mlx-community/rfdctr-osp-small-fp32.
A live camera feed appeared with a bounding box around Canuma labeled “person 0.96.” He said it was running entirely on his computer, then showed object detection continuing as he held up a glass. The model labeled it as wine, which he joked was wrong because he was sober. The point of leaving the error visible was useful: local perception can be real-time without being perfect.
He then showed a related background-blur use case, comparing it to meeting software that blurs a user’s background. The camera feed showed him segmented with the background blurred, and the same detection label around him. Canuma said developers could build this kind of native experience into products.
The second demo used the MLX-VLM Chat UI in a local browser interface. The visible command launched mlx_vlm.chat_ui with mlx-community/gemma-4-26b-it-4bit. After some demo friction involving model files and a restart, the interface loaded a Gemma 4 26B model. Canuma said he would turn off the internet again to show it was not running remotely, though his wording briefly inverted itself: “to show you that this is not running completely on device.” The surrounding demonstration and his repeated claims made clear he intended the model to run locally.
He uploaded an image of his X profile and prompted: “Describe this image in detail.” The response identified the page as a profile for Prince Canuma and reproduced many visible details: the name, blue checkmark, post count, profile image, “Edit profile” button, handle, bio, location, GitHub link, join dates, and follower counts. Canuma noted that it was picking up his bio and other page details while running on device and using the GPU.
He also disclosed the hardware context: the machine he was using had “like 96 gigabytes of VRAM,” which he said allowed him to run all of the models he had shown so far in real time, at the same time. That caveat matters. The demo established that this class of workload can run locally on high-end Apple silicon; it did not imply the same simultaneous workload would run identically on every Mac.
Community projects show the same primitives moving into products
Prince Canuma used community examples to show that MLX is not limited to command-line demos. The first was “grounded visual reasoning using mlx-vlm.” The video montage showed object detection and segmentation across aerial clips: detecting fires, segmenting a helicopter, detecting vehicles at a traffic intersection, tracking an airplane, finding people around a car, and segmenting jets flying in formation.
Canuma said the same approach could support security systems running on a MacBook at home, or post-hoc analysis of dash-cam footage. He mentioned having his own dash-cam videos and using a system he built to analyze footage after “crazy experiences.” The examples stayed close to perception: locate, segment, track, and ask for particular objects in video, without relying on internet access.
The second example was MLX-Video. Canuma described it as an honorable mention and one of his recent projects. A generated 3D cartoon showed children playing in the snow outside a large building. He said it was generated completely on device from a simple text prompt.
The more interesting part was the workflow: the user did not generate one entire video in a single shot. Instead, Canuma said the user chained a system that could continuously generate from the previous video, allowing a more cohesive story across generations. He said that system could run even on a MacBook with 16GB of VRAM.
A third example came from an attendee, Adrian, who built an application called Locally. Canuma showed a phone app with a pulsating blue circle and synthesized male voice reading text. He said Adrian used MLX-Audio and Marvis TTS to give the application the ability to speak back to users. Canuma held it up as evidence that local AI can support “beautiful native experiences” when paired with good design.
The final example was robotics. Canuma said he had acquired a Ritchie mini robot the previous year and powered it with MLX-Audio and MLX-Vision to provide perception through camera and audio input. The video showed a small tabletop robot with display eyes. Canuma said it was using real-time voice cloning of the Iron Man Jarvis voice. When he said, “Hey Jarvis,” the robot replied, “Hey there. Great to see you. How’s it going?”
His conclusion from these examples was compositional: developers can chain capabilities to build agents that hear, see, and sound like a user or a loved one, running on an iPhone, iPad, Mac, or robot.
MLX uses the GPU today, not the Neural Engine
A questioner challenged the Apple hardware story directly. Apple promotes the Neural Engine, the questioner said, but in their experience with MLX the Neural Engine usage is “almost zero.”
Prince Canuma answered plainly: MLX uses the GPU, not the Neural Engine. To use the Neural Engine, he said, developers need Core ML, and Core ML “does not really run well” as an easy developer experience. He said he hoped Apple would address private API issues at WWDC. If that happens, he said, the team has internal projects that could allow hybrid inference across both the GPU and Neural Engine.
He also said the direction of Apple’s architecture is not fully clear from the outside. He speculated that Apple might be changing the Neural Engine and moving some components into the GPU, pointing to the M5 series as an example where he saw some components already present. But he treated that as uncertain: “we just don’t know what direction they’re heading.”
The practical monitoring answer was simpler. Asked whether there is a tool to see GPU usage directly on a Mac, Canuma opened mactop, which showed CPU, memory, GPU, power, network, disk, and process information. He credited Carson as the creator and described it as one of the easiest ways to track performance.
He then ran local inference while mactop remained visible. When the MLX-VLM Chat UI generated short responses to “Hi” and “How are you,” the GPU usage rose. The visible terminal showed GPU usage increasing first to 21% and then to 58%. The point was not a formal benchmark; it was a direct demonstration that the workload was hitting the GPU on the local machine.
Omni models are available, but expectations still need calibration
Asked which omni models he would recommend, Prince Canuma named two families. First, he cited Gemma 4 “E” variants, such as E4 and E2, which he said take image, audio, and text as input, or any variation of the three. Second, he named Qwen 3 Omni, which he described as a larger model around 30 billion parameters that can also run on device. Those were “the top ones” he knew.
The follow-up question was about limitations. Canuma’s answer distinguished capability from frontier-cloud parity. He said limitations depend on the use case, and that there are things the models “just cannot do.” Users should not expect the performance of Claude Opus today, though he suggested open-source models may reach that level in perhaps six months. His advice was to adjust the experience to the expected performance.
Outside that quality caveat, he said he did not see many limitations. He claimed users can run inference on hundreds of images in parallel and on many documents. He also said models can now reach context lengths up to one million tokens on device because of TurboQuant, depending on model size and hardware.
That qualification was important. The argument was not that every open-source omni model now equals the strongest cloud models, or that every Apple device can carry every workload. It was that the constraint space has changed: local multimodal systems are good enough for useful product categories, and their memory and context limits are moving quickly.
TurboQuant is presented as a KV-cache bottleneck breakthrough
TurboQuant entered through a question about a recent Google paper and whether the approach could be implemented generally. Prince Canuma said he was one of the first people to implement TurboQuant publicly: about 30 minutes after the paper came out, he said, he had an implementation and posted about it at around 3 a.m.
The tweet shown on screen, attributed to @Prince_Canuma, described KV-cache memory as the main bottleneck limiting sequence-length scaling. Its visible text claimed “Head-to-toe comparisons against Google’s TurboQuant-v0.2,” “6/6 exact match on every quest-level,” and “Using Up to ~5X less KV cache RAM.” Canuma said the post received about 700,000 views.
The table shown in the tweet compared a full model with TurboQuant configurations:
| Config | Exact match | Average cache GB | Vs full |
|---|---|---|---|
| Full | 6/6 | 0.703 | 1.0x |
| TurboQuant 2.5 | 6/6 | 0.143 | 4.9x smaller |
| TurboQuant 3.5 | 6/6 | 0.185 | 3.8x smaller |
Canuma explained the quality column by saying that “exact match” means the responses matched the full model’s performance in that comparison. When asked whether quality was the same, he said “similar quality,” pointing again to the exact-match result.
He also gave a throughput example. In the visible chart for larger contexts, the table compared baseline and TurboQuant across decode speed, KV cache size, and peak memory up to 275K context. Canuma said that at around 300,000 context, performance “almost doubles” in throughput. He presented TurboQuant as one of several techniques he is pursuing to push on-device inference further, specifically by reducing the KV-cache memory pressure that makes long-context generation expensive.
The strongest claim came with caveats: he said one million context is now possible completely on device, but “depending on the size of the model and your hardware.” In the context of the rest of the talk, TurboQuant functions as a response to the recurring objection that local devices cannot hold enough memory for serious models. Canuma’s answer was that the memory bottleneck is being attacked directly, not merely accepted.