Comprehension Made Up 67% of One Engineer’s Claude Coding Sessions

Priscila Andre de Oliveira, a senior engineer at Sentry, argues that the most useful daily AI skill in a large production codebase is not code generation but comprehension. After analyzing 116 of her own Claude sessions, she found that 67% of her prompts were about understanding code and just 2% were generation. Her workflow, built around a local “catch me up” skill, uses AI to trace architecture, conventions, tests, history and behavior before any planning or implementation begins, because she says slop starts when the engineer’s mental model is wrong.
The bottleneck is not typing code
Priscila Oliveira says her work at Sentry has changed in a way that sounds extreme but, in her telling, has become practical: since December 2025, she has “only prompt[ed].” She showed recent pull requests co-authored with Claude, with a slide describing them as reviewed by Cursor, Seer, and humans. The examples included bug fixes, features, refactors, and cross-repository work.
The sharper claim was that generation is not where the leverage usually comes from. In a large production codebase, Oliveira argued, the daily unlock is comprehension: using AI to explore, explain, trace, and clarify code before asking it to plan or implement changes.
Sentry, as Oliveira described it, is not a small greenfield project where an agent can safely guess its way through a task. It is an observability platform with error monitoring, logging, session replay, tracing, metrics, profiling, agent monitoring, and an “AI Debugging Agent.” It was founded in 2010, has more than 15 years of accumulated code, roughly 400 employees, and more than 100,000 organizations depending on it. Oliveira framed that scale as the reason AI assistance has to be disciplined rather than performative.
Her formulation was blunt: she does not want to “just ship slop code” into the codebase that pays her salary. Vibe coding may be useful, and Sentry uses it internally, but quality still matters. For Oliveira, the safe path is to use AI first as a codebase exploration partner — then as a planning and implementation partner only after the human has aligned their mental model.
Sentry is using agents, but not treating quality as optional
Priscila Oliveira described herself jokingly as having promoted herself from senior software engineer to “agent manager.” A slide showed her at a desk with three monitors, managing multiple agents at once; another compared the work to conducting an orchestra. The joke carried a real workflow shift: she now orchestrates tools as part of ordinary engineering work.
Sentry has also built and adopted internal AI tools. Oliveira mentioned Abacus, an open-source tool for tracking internal AI coding usage; Warden, a code review agent for pull requests; Junior, a Slack bot that can investigate a thread and create a pull request for a bug or requested UI change; and an open-source AI SDK testing repository used to test Sentry’s AI integrations. Some came out of a hackathon intended to help employees get familiar with AI. The testing repository predated the hackathon, but became one of the places where Oliveira was asked by her team not to code directly: she should prompt until she got a good result.
That did not make the work casual. Oliveira paired the description of Sentry’s AI adoption with a reminder that the company had also run a “quality quarter” the previous year. During that period, the team focused on improving the codebase: removing TypeScript any types, cleaning up TODOs, simplifying code, and removing unused feature flags. She called this work technical debt reduction, and placed it beside AI adoption rather than against it.
Oliveira is not arguing for a purist rejection of agentic coding. She said “vibe coding is great” and that Sentry does it. But she separated experimentation from the responsibility of maintaining a complex, active product. In her words, a vibe-coded project may be fine as a context for not understanding every detail; a serious work codebase is different.
A moving codebase makes comprehension a daily practice
Sentry’s codebase changes quickly enough that understanding it is not a one-time onboarding task. Oliveira said roughly 100 pull requests are merged every day. The company has four offices across time zones, external contributors because Sentry is fair source, evolving patterns and standards, deprecated components, new components, new lint rules, cross-repository dependencies, and 15 years of accumulated code.
The consequence is that even long-tenured engineers have to keep re-aligning. Oliveira has worked at Sentry for more than six years, but she said she can go on vacation, return, and find her pull request full of conflicts. Resolving those conflicts requires understanding what changed while she was away.
She connected this to a longstanding property of software engineering: developers spend a large share of their time reading and navigating existing code. A slide cited Minelli, Mocci, and Lanza’s 2015 IEEE ICPC work for the figure that about 70% of developer time is spent reading and navigating code rather than writing new code. Oliveira’s point was that AI does not remove this work. It changes how quickly a developer can do it.
Before AI, her examples were familiar: search the codebase to find where a function is used; open multiple pull requests to infer a pattern; ask a colleague in another time zone and wait; reconstruct a change through git blame, commit by commit. With AI, she can ask direct questions: “Why do we not have an error boundary there?” “Where is ModelsTable used?” “How does the conversations table work?” The goal is the same: align the engineer’s mental model with the codebase. The difference, she said, is that it can now happen in minutes rather than hours.
I don’t use AI to write code faster. I use it to understand code faster.


That distinction shaped the rest of the talk. Oliveira’s agent is not valuable because it can type a patch. It is valuable because it can read, trace, summarize, and answer follow-up questions without getting tired.
Her own Claude history contradicted the generation narrative
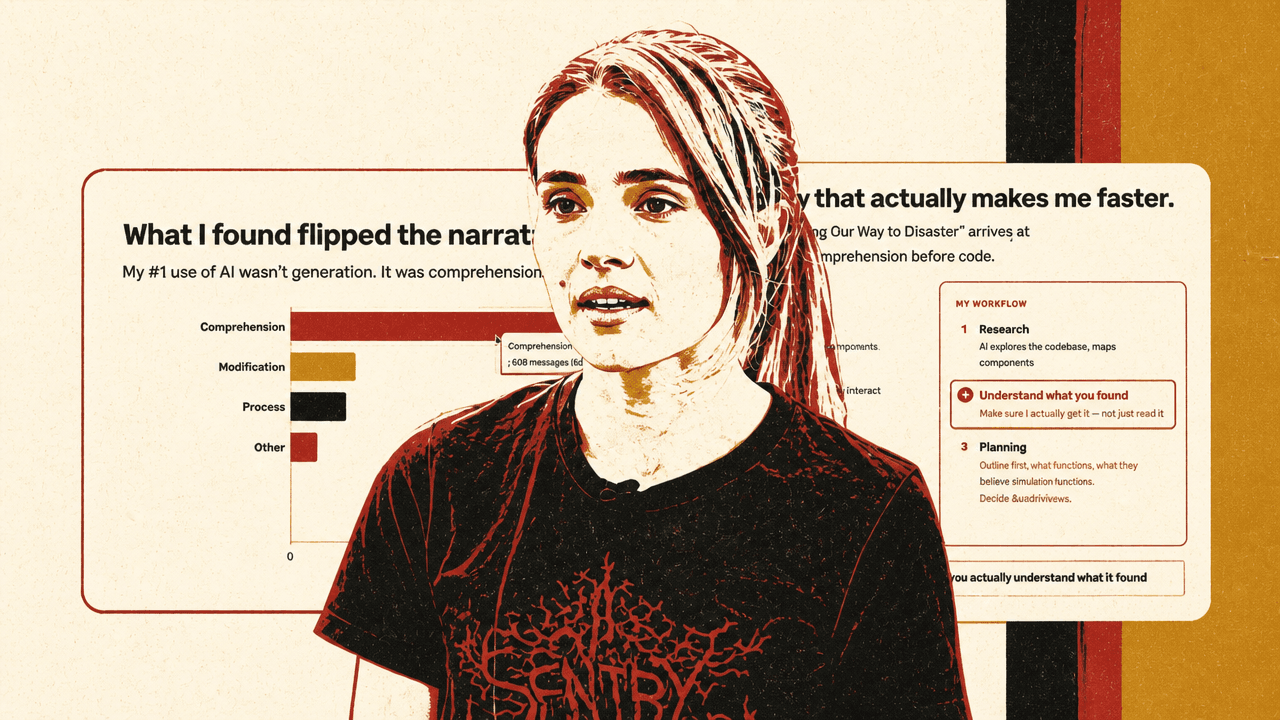
Priscila Oliveira did not present this as a vibe or belief. She analyzed her own Claude Code history from February 13 to March 14, 2026. Claude reviewed 116 sessions and classified 929 prompts into six categories: comprehension, modification, process, review, generation, and other. Across those sessions, AI read 1,435 files.
The result surprised her: comprehension dominated.
| Measure | Value |
|---|---|
| Claude Code sessions analyzed | 116 |
| Prompts sent | 929 |
| Files read by AI | 1,435 |
| Prompt categories | Comprehension, modification, process, review, generation, other |
| Comprehension messages | 618 messages, 67.0% |
| Generation messages | 19 messages, 2.1% |
The finding “flipped the narrative” for her because her number-one use of AI was not asking it to produce code. It was asking it to explain code. Only 2.1% of the analyzed messages were code generation prompts.
That observation became the basis for a personal workflow tool. Her prompts kept repeating: walk me through this component, explain this pattern, trace this behavior, clarify why this was changed, show me how this is tested. Rather than keep writing variants of the same prompt, she turned them into a structured local skill called /catch-me-up.
The catch-me-up skill turns repeated questions into exploration modes
The /catch-me-up skill is not a productized system in Oliveira’s account. It is a markdown file on her computer: ~/.claude/skills/catch-me-up/skill.md. She said she could share it if she wanted, but she built it for herself.
The skill’s stated purpose, shown on the slide, is to “build the user’s mental model of unfamiliar code, architecture, or technology.” Its instruction is to prioritize comprehension over generation: explain before suggesting changes.
It organizes exploration into six modes:
| Mode | Trigger signals shown |
|---|---|
| Architecture | “how is this structured” |
| Convention | “what patterns”, “what’s the standard” |
| Feature trace | “how does X work”, “trace”, “walk me through” |
| Syntax / API | “what does this syntax mean” |
| Testing | “how is this tested” |
| History | “why was this changed”, “who changed this” |
The visible skill file also included depth guardrails. For architecture exploration, for example, the slide showed a sampling limit of top-level plus depth-two exploration across three to five files. The point is not to ask the agent to swallow an entire repository indiscriminately, but to shape how it samples, traces, and reports.
Oliveira said she is a visual person, works heavily on Sentry’s frontend, and likes to see structure. The skill therefore asks for outputs such as organizational structure and tables that make the codebase easier to reason about. The format is part of the value: the agent is not just answering; it is arranging evidence so the human can form a mental model.
The demo showed comprehension before permission to modify
In the demo, Oliveira used the skill on Sentry’s testing-ai-sdk-integrations repository — the same repository where she had been told to prompt rather than code directly. Her prompt was: “I’m a new contributor. Catch me up on how this repository works, and clarify whether it simulates a Sentry envelope and intercepts it during tests.”
Claude Code, running Opus 4.0 in Claude Enterprise, explored the repository. The displayed Claude response summarized the project as a testing framework for Sentry’s AI SDK integrations. In that on-screen response, Claude said Sentry auto-instruments popular AI libraries such as OpenAI, Anthropic, and LangChain in both JavaScript and Python, and that the repository ensures those integrations produce correct tracing data and catch regressions when new SDK versions ship.
The response laid out a core flow: a TypeScript test definition is rendered through a Nunjucks template into a runnable JavaScript or Python test file; the runner executes it with SENTRY_DSN pointing to a local HTTP server; the real Sentry SDK sends envelopes to that server; a validator checks captured spans; and a reporter outputs pass or fail results.
Oliveira had asked whether the repository simulated Sentry envelopes or intercepted them during tests. Claude’s on-screen answer was direct: “Does it simulate envelopes? No — it intercepts real ones.”
The displayed explanation said the SDKs are not modified. A unique DSN is generated per test and points to localhost, so the SDK believes it is talking to Sentry while the local span collector receives and parses the envelopes. The important clarification for Oliveira was the mental model: according to the Claude output she showed, the tests use real SDK behavior and intercept the resulting data locally rather than simulating the envelopes.
For Oliveira, that output was the value of the skill. Without AI, she said, she would have had to reconstruct that understanding herself. With AI, she still had to understand the explanation; she did not treat the summary as a substitute for knowing what she was changing. She also uses the skill for pull request review when she has some context, but not enough to approve a colleague’s change responsibly.
Research and planning are not enough if the human skips understanding
Priscila Oliveira compared her workflow with a three-phase methodology from Jake Nations’ “Vibe Coding Our Way to Disaster,” which she said draws on Rich Hickey’s “Simple Made Easy” philosophy. The three phases are research, planning, and implementation. In that model, AI explores the codebase and maps components; then it plans which files and functions are involved and how they interact; then it translates the plan into code.
Oliveira said she agrees with that structure, and noted that planning modes already exist in tools such as Claude Code. Her amendment is a separate human step between research and planning: understand what the agent found.
That step matters because the agent’s research can be misdirected. If the agent went in the wrong direction, the developer has to notice. If the agent missed a relevant path, the developer has to steer it. In her workflow, the agent can perform research, but the human needs to understand the research before asking for a plan and implementation.
She reinforced the point with a quote from Armin Ronacher’s “The Final Bottleneck”: “When more and more people tell me they no longer know what code is in their own codebase, I feel like something is very wrong here.” Oliveira said she agrees. Her concern is not that AI makes typing too easy; it is that engineers may stop knowing what is in their own codebase.
The agent can answer endless questions, but alignment remains the engineer’s job
Oliveira’s closing advice was practical: track your own AI usage, because the pattern may surprise you. Her own analysis showed 67% comprehension and 2% generation, which led her to improve the repeated part of her workflow instead of optimizing for code output.
She described AI as the teammate who “never gets tired of your questions” and “the cheapest senior engineer out there.” That framing explains the strength and the limit of the approach. A patient assistant can accelerate code reading, answer background questions, trace behavior, and reduce dependence on colleagues in other time zones. But it does not remove the need for the developer to understand what is being changed.
The operating rule is simple: align the mental model first; the code follows naturally. In Oliveira’s version of AI-assisted engineering, the agent explores, summarizes, and eventually implements, but the human engineer still has to comprehend first.