Declarative UI Is Emerging as the Practical Path for Agent Interfaces

Ruben Casas of Postman argues that agent interfaces have not caught up with the frontend code models can now generate. In his talk, he contrasts static component systems with declarative UI, where an LLM produces JSON or YAML for a renderer, and fully generative UI, where the model writes HTML, CSS and JavaScript directly. Casas says declarative UI is probably the right balance today, while MCP apps matter because their sandboxing offers a way to contain runtime-generated interfaces.
The models crossed the frontend threshold before the interface paradigm changed
Ruben Casas frames the problem as a mismatch between model capability and product interface architecture. In late 2022, the common pattern was to ask ChatGPT for a component, request code blocks, copy and paste the answer, fix it, and repeat. Casas calls that “poor man’s vibe coding”: exciting because it could produce UI at all, but still recognizably a developer-assisted workflow.
The model side of that equation changed faster than the interface side. Casas points to a recent acceleration in long-horizon software work and high-fidelity UI generation, specifically citing GPT 5.2 and Opus 4.5 as important model releases. His point is not only that models became better at coding tasks, but that they became capable of producing “thoughtful” and “really, really good” working interfaces quickly.
His personal test was deliberately ordinary: he prompted a model to rewrite his blog. He did not ask for interaction design details. The model nevertheless produced a search box, a blur animation, and accessibility support. That was the moment he says his view changed. In roughly three years, the field had moved from celebrating a few generated lines of code that ran to models writing frontend code better than he does.
And then that's when I realized that in the space of, of three years, uh, from when ChatGPT was released to today, we went from, uh, you know, 'few lines of code, is great, uh, it can, it runs', 'oh, it now can write better frontend code than me'.


The consequence is the talk’s central question. If models can generate competent UI code, why are agent interfaces still dominated by static components, predefined layouts, and chat boxes? Casas uses the familiar “Jarvis” image — floating windows that appear and disappear around the user — not as a literal design target, but as shorthand for the missing interface leap. The models have become more capable, but the prevailing UI still looks like an incremental extension of familiar application patterns.
Chat is the terminal, not necessarily the GUI
Ruben Casas borrows Andrej Karpathy’s analogy that interacting with the new computer through chat is like talking to a terminal. The user has direct access to the operating system, but the graphical interface has not yet been invented. In Casas’s phrasing, “we have intelligence without a mature interface language.”
That distinction matters because much of today’s product response has been to put chat everywhere. Casas cites recent criticism that SaaS companies are adding chat boxes to their home pages and dashboards. He does not reject chat outright. It is “fine” and “okay for now.” But he rejects the assumption that chat is the final user interface for intelligent systems.
The question is, if it's not chat, then what is the interface for this computer?
The alternative pattern he identifies is the “one app to rule them all” model: instead of every SaaS product embedding its own chat window, a user might interact with third-party UIs from inside a super app such as ChatGPT, Claude, or Gemini. MCP apps are relevant here because they allow third-party UI to render inside an agent environment.
These are two separate questions that are often collapsed into one. The first is where the UI runs: inside each product, inside a super app, or somewhere else. The second, more important question for this talk, is what the model generates. Static components, declarative UI, and fully generative UI are different answers to that second question.
Casas is explicit that he does not know which option will become the final one. “Consumers will tell us,” he says. But the generation model is already changing underneath those distribution choices.
Static components keep the agent close to the familiar client-server pattern
Ruben Casas describes the most common agent UI pattern today as static component rendering. The agent acts as an orchestrator. It makes a tool call through MCP apps or another tool interface. That tool call returns parameters and data. The client maps those values into predefined components that developers have already built.
This is close to the web UI pattern developers have used for decades. A server sends data; the client renders it with existing components. The novelty is that an agent is now producing or selecting the props. The interface itself remains bounded by the component set.
Casas’s diagram for this pattern shows an agent making a tool call, passing parameters and data, and a client rendering predefined static components. The visual point is important: the agent sits where a server might once have sat, but the UI layer is still a fixed client-side component system.
AG UI is one example. In that model, a developer can register a client tool that maps to a React component. The model calls the tool, passes props, and the registered component renders. The LLM is not inventing the UI; it is filling a predefined shape.
Goose’s auto visualizer is another. Goose, an MCP client, can accept arbitrary data, organize it, and match it to a set of predefined visualization components created by the Goose team. In the example shown, Goose renders a radar chart. Casas presents this as a useful capability, but still within the static paradigm: the agent chooses or supplies data for components, while the component vocabulary remains fixed.
The advantage of this approach is control. Developers own the interface vocabulary, the design system, and the behavior. The limitation is equally direct: the agent can orchestrate, but it cannot invent the interface at runtime. Casas’s critique is not that static components are broken. It is that they leave much of the model’s frontend-generation capability unused.
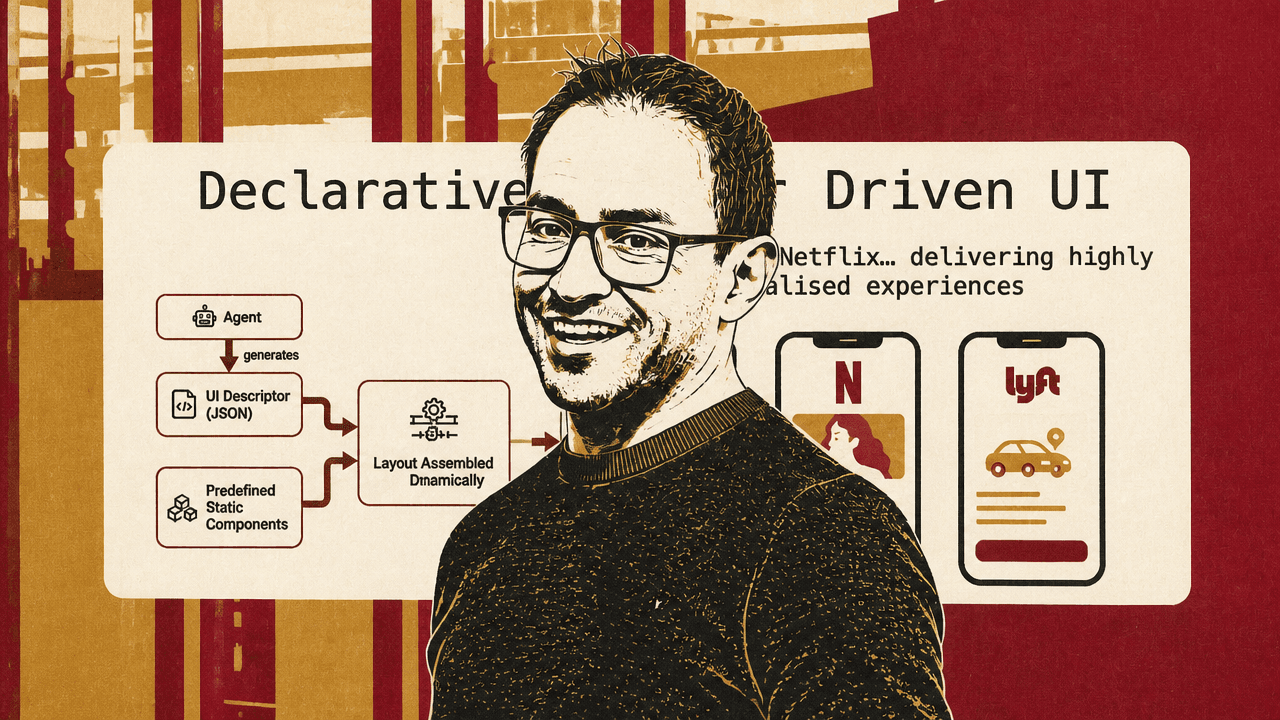
Declarative UI is probably the current balance between flexibility and control
Ruben Casas says declarative generative UI is “probably the perfect balance today” in terms of flexibility and consistency. It still depends on predefined components, but changes what the model produces. Instead of passing only props to a known component, the agent generates a descriptor — JSON, YAML, or, in FastMCP examples he has seen, Python — that describes the interface. A rendering engine then translates that descriptor into the final UI using the application’s component library.
The result is more dynamic and personalized than static component calls, while still constrained by an approved design system. Casas emphasizes that this is not an entirely new idea. Server-driven UI and personalized interfaces have existed for years. Netflix is his example: the homepage can be “completely personalized” for each user while still being built from Netflix’s own components and interface elements.
The difference in the agent era is that an LLM can generate the descriptor dynamically. The model is not writing arbitrary frontend code. It is writing a structured representation that the runtime knows how to interpret.
Vercel’s JSON Render is Casas’s strong recent example. It maps components using JSON and, more recently, YAML. In the demo he references, the system renders dynamic interactions including 3D crystal-structure models, charts, and quiz-style UI. The model generates the JSON; the runtime renders the UI through registered components.
For Casas, that constraint is the point. Declarative generative UI gives teams personalization and flexibility without abandoning consistency. It keeps the design system intact, makes the output more predictable, and can be faster and cheaper than asking a model to generate full HTML, CSS, and JavaScript every time.
| Pattern | What the model generates | What developers still control | Casas’s assessment |
|---|---|---|---|
| Static components | Props and data for predefined components | Component set, layout behavior, design system | Most common agent UI pattern today |
| Declarative UI | A JSON, YAML, or FastMCP-style Python descriptor | Rendering engine and predefined components | Probably the best current balance of flexibility and consistency |
| Generative components | HTML, CSS, and JavaScript at runtime | The sandbox and delivery boundary, if implemented | Next level, but needs containment |
His assessment is pragmatic rather than purist. Declarative UI is not the maximum possible expression of model capability. But today, he argues, it is probably the right compromise: dynamic enough to matter, constrained enough to ship.
Fully generative UI removes the component layer and introduces a containment problem
Ruben Casas defines the “next level” as generative components: letting the model write frontend code on demand at runtime. If models are good at React, JavaScript, CSS, and interface composition, the obvious question is why an agent should be limited to descriptors or predefined components.
In this architecture, the agent can call a model — potentially the same model through reverse sampling, or another model specialized for code generation — and ask it to produce HTML, CSS, and JavaScript. That generated code is then passed to the client and rendered directly. There is no component mapping layer and no translation engine between the model’s output and the user-facing interface.
Casas built a weather-agent experiment at Postman to test the idea. The agent calls a weather API, creates a joke, and generates the HTML, CSS, and JavaScript in a single tool call. The resulting Paris weather UI is not selected from a library; it is produced by the agent. The example displayed “Paris - Station Température,” a temperature of 12.4°C, “Patchy rain nearby,” and a generated line comparing the weather to “waiting for the next train in a windy Métro tunnel: brisk, with a touch of Parisian drizzle.”
That example carries the appeal of fully generative UI: the interface can be random, imaginative, and tailored to the task in a way a fixed component set cannot anticipate. But Casas immediately names the problem. If developers do not trust arbitrary third-party code, they should not trust code generated by an LLM and simply present it to users.
Generative UI at this level needs a distribution model. That model needs a boundary. It needs containment. It needs a sandbox.
This is where MCP apps become especially important in Casas’s account. They provide tool calling, authentication, and message passing between the UI and the agent. They are sandboxed by default through a double iframe. Casas calls MCP apps the default for third-party UI delivery today and says they can also be used for first-party UI.
The slide he uses for this claim is blunt: MCP apps are a delivery mechanism, include MCP features such as tool calling and auth, are sandboxed by default, are used for third-party UI, and can also be used for first-party UI. The double-iframe boundary is not a decorative implementation detail; it is central to Casas’s argument for why runtime-generated interface code needs a container before it reaches a user.
Casas interprets Anthropic’s MCP-apps direction as strategically interesting for that reason. He says Anthropic could have created its own rendering and architecture mechanism for delivering the visualizer interaction in Claude, but instead used MCP apps, which provide many of the relevant capabilities out of the box. His conclusion is framed as a question for other teams: if MCP apps can be used for first-party UI in that context, why not use the same delivery mechanism elsewhere?
The significance of MCP apps, in this argument, is not just interoperability. It is that they provide a plausible containment and delivery layer for UI generated on the fly by agents and coding models.
The future may be collaboration, not better visualization
Ruben Casas does not present MCP apps or chat as final forms. He repeatedly says the field does not know the final interface for the “new computer.” The obvious guess is the Jarvis-style environment: floating windows, fluid overlays, interfaces that appear and disappear around the user. But he warns that the obvious future may be too obvious.
His analogy is early television. When television first appeared, the first TV shows resembled radio shows with cameras because creators had not yet imagined what the new medium could do. Casas believes agent interfaces are in a similar stage. Current designs may be carrying over patterns from older media because the new interface language has not yet emerged.
That leads him to a different hypothesis: the future beyond components may be less about output visualization and more about shared human-agent workspaces. His concrete example is the Excalidraw MCP app. He describes it not merely as a way for an agent to output diagrams, but as a shared artifact: a canvas where a human and an agent can collaborate.
In that mode, the user can ask the agent to change a diagram, but can also click, drag, and modify the artifact directly. The UI is not just an answer displayed by the model. It becomes the shared surface of collaboration, combining direct manipulation with agent instruction.
For Casas, that is closer to a meaningful new interaction model than using an agent as an orchestrator that occasionally shows visualizations. Agents are too powerful, in his view, to be reduced to dispatchers for predefined components. The stronger interface direction is likely to be personalized, generative, and collaborative.
This remains speculative in his telling. He does not claim to know the answer. His position is narrower and more useful: the industry is still early, the current chat-and-component patterns are transitional, and the interface for agentic systems is still available to be shaped.