Semantic Search Cut Claude Code’s Wasted File Reads to One in Eight

Kuba Rogut of Turbopuffer benchmarked Claude Code on 50 ContextBench tasks to test whether it found the right code context, not whether it solved the tasks. He argues that adding semantic search to windowed grep made Claude Code’s file reads much more precise, cutting irrelevant reads from about one in three to one in eight, but did not make semantic retrieval a blanket replacement for grep. In Rogut’s results, semantic search helped when related code shared behavior rather than keywords, while grep remained stronger when the relevant term or import path was explicit.
Semantic search reduced wasted file reads, but it did not simply dominate grep
Kuba Rogut tested whether Claude Code could retrieve more relevant code context when given a semantic search tool, not whether it could ultimately solve a programming task. The benchmark was built around a narrower and more diagnostic question: as an agent works through a task, does it find the files, lines, and symbols that human labels say it should have found?
The main result was strongest on precision. Raw Claude Code, using its default agentic search behavior, reached 65% file precision in Rogut's 50-task subset. Adding a 50-line read window lifted file precision to 75%. Adding semantic search on top of that lifted file precision to 87%.
Rogut translated those percentages into the operational version of the result: by default, roughly one in three Claude Code file reads was irrelevant to the task; with windowed grep, about one in five was irrelevant; with semantic search, about one in eight was irrelevant.
| Condition | File precision | Line precision | Symbol precision | Plain-language reading |
|---|---|---|---|---|
| Baseline Claude Code | 65% | 33% | 43% | About 1 in 3 file reads wasted |
| Windowed grep | 75% | 42% | 47% | About 1 in 5 file reads wasted |
| Windowed grep + semantic search | 87% | 51% | 44% | About 1 in 8 file reads wasted |
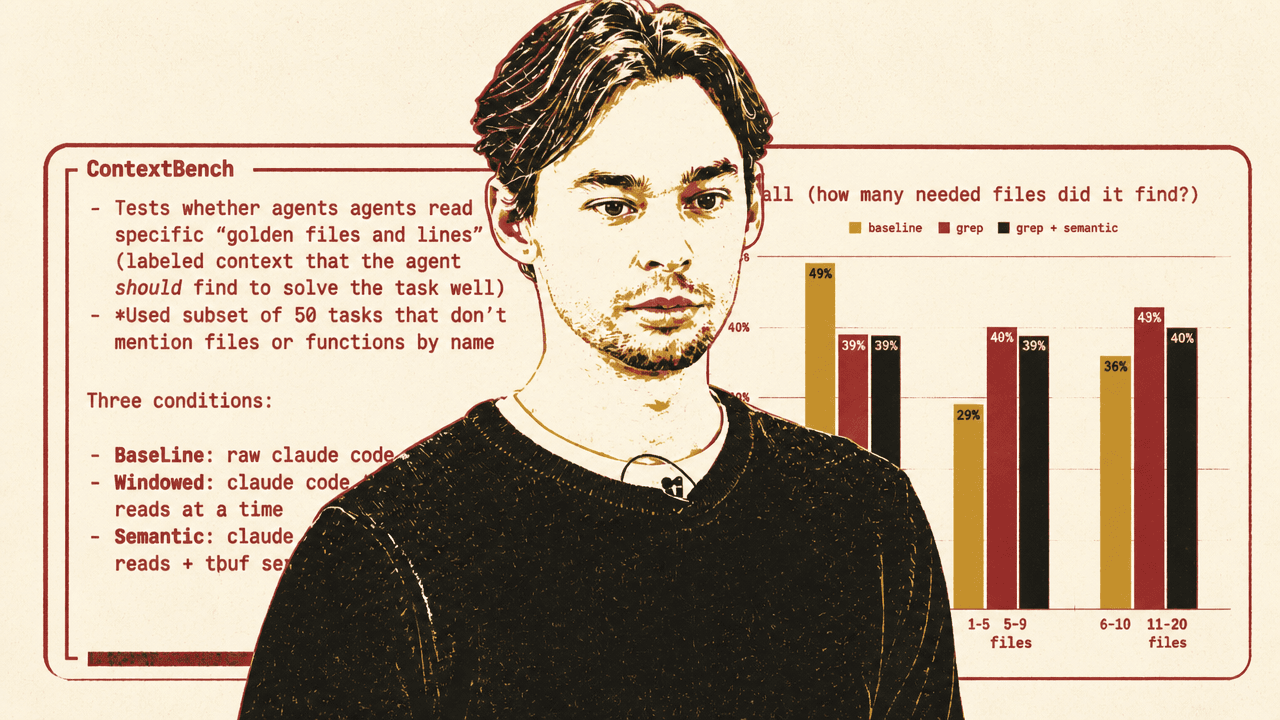
That precision gain came with a more complicated recall picture. Recall measured how many of the needed files, lines, and symbols the agent found at all. On file recall, baseline Claude Code was best: it opened more files and therefore found more needed files by volume. Rogut's explanation was not that baseline was more disciplined, but the opposite. Claude Code is "really exploratory"; it likes to read broadly, and that behavior inflates the chance of touching needed files while also wasting reads.
On line recall and symbol recall, the picture narrowed. Windowed grep and windowed grep plus semantic search produced similar recall overall, with semantic search slightly worse in the aggregate. Rogut treated that not as a clean loss for semantic retrieval, but as evidence that grep and semantic search are good at different retrieval problems.
| Condition | File recall | Line recall | Symbol recall |
|---|---|---|---|
| Baseline Claude Code | 49% | 43% | 40% |
| Windowed grep | 45% | 29% | 42% |
| Windowed grep + semantic search | 41% | 29% | 39% |
When Rogut split the tasks by which retrieval mode "won," the difference became clearer. Semantic search performed better on tasks that required finding behavior-adjacent files and modules: related code that did not necessarily share the same literal keywords. Grep performed better on tasks that were mostly import tracing or finding function names near bugs, where the relevant term was already available and keyword search could follow it.
Rogut's example for the semantic-search side was a task involving code that handled multiple ORMs across different libraries. Keyword search did not naturally gather all of the relevant files, while semantic search was able to group files by related behavior. On the grep side, he described tasks where the agent could find the right keyword in the first or second tool call and then trace directly through imports or function names.
The benchmark measured context retrieval, not task completion
The evaluation used ContextBench, which Rogut described as a benchmark for whether agents read labeled context while working: the files, lines, and symbols that the agent should find to solve a task well. Rogut used a subset of 50 tasks that did not mention file names or function names, so the agent had to discover the relevant context rather than simply follow explicit pointers.
The three tested conditions were baseline Claude Code out of the box; Claude Code with file reads capped at 50 lines at a time; and the same 50-line windowed setup plus a tpuff search semantic retrieval tool.
The 50-line read cap mattered because unrestricted reads made the benchmark noisy. If an agent reads an entire thousand-line file, Rogut said, it becomes harder to distinguish whether it meaningfully found the relevant context or merely consumed enough surrounding text to include it. Windowing made the retrieval behavior more legible.
Precision asked what share of the agent's retrieved context was actually labeled as needed. If Claude read 10 files and eight were needed, that was 80% file precision. Recall asked what share of the needed context the agent found. If a task had 10 needed files and Claude found three of them, recall was 30%.
That choice of benchmark separates two questions that are often collapsed in coding-agent evaluation. A model may arrive at a plausible answer while reading too much irrelevant code, or it may miss context that would have made the answer more reliable. ContextBench scores the retrieval path: the files, lines, and symbols consulted along the way.
The tool was intentionally simple: raw code chunks, Voyage embeddings, Turbopuffer retrieval
Rogut built a CLI tool for Claude Code called turbogrep, or tpuff in the command shown during the demo. The implementation walked the file system, parsed and chunked code using tree-sitter, embedded chunks with Voyage's code model, and uploaded them to Turbopuffer. Search embedded the query, sent it to Turbopuffer, and returned ranked code chunks to Claude Code.
He described the semantic search used in the benchmark as "just doing vector search": embedding the query sentence or tokens with Voyage Code 3 and retrieving against the embedded code. In response to an audience question, he said the benchmark used raw code as the target data, not a more elaborate representation with generated summaries or parent-child structures.
The on-screen directory structure for turbogrep-v2 showed the components Rogut treated as necessary for the experiment: a CLI entry point, tree-sitter chunking, a Voyage AI HTTP client, a Turbopuffer HTTP client, an indexing pipeline, search, filters, project-root and git helpers, branch overlay logic, and a terminal UI for search and indexing progress. Rogut said a v1 version had an open-source library and that v2 would be open sourced later.
In the demo, Claude Code was working inside the Django repository. Asked how Django handles password reset token generation and validation, it called:
tpuf search "password reset token generation validation" --hybrid --json
The on-screen trace showed a returned chunk from a password-reset test, then Claude reading django/contrib/auth/tokens.py. The answer visible on screen discussed PasswordResetTokenGenerator, token generation with make_token, validation with check_token, and security properties including single use, time limits, HMAC with SECRET_KEY, constant-time comparison, and Referer-leak protection in PasswordResetConfirmView.dispatch.
The demo illustrated the tool call path Rogut wanted to measure at scale: Claude could call semantic search, receive chunks, read a relevant file, and construct an answer. The benchmark then quantified whether that changed retrieval behavior across tasks.
Embeddings were framed as cached compute
The deeper argument for semantic search was not that embeddings are magic, but that they move repeated discovery work out of each agent session. Kuba Rogut described embeddings as "cached compute": the codebase is chunked, embedded, and indexed once, so that future agents can retrieve semantically relevant chunks without rediscovering them through repeated grep-read-assess loops.
Embeddings are cached compute.


The slide example contrasted two paths for the same kind of task: understanding how metadata filtering works. In a per-session discovery loop, the agent might grep for "metadata filter", read the wrong section of indexing.py, grep for "ingest pipeline", read part of api_client.ts, then read types.ts for context. The slide counted 6,314 tokens spent in that illustrative process, repeated across every session and every agent.
In the amortized version, indexing happens once: the codebase is chunked, embedded, and indexed, with semantic meaning encoded upfront. At runtime, the agent asks, "How is metadata filtered?" and receives ranked chunks from indexing.py, api_client.ts, and types.ts, totaling 424 tokens in the slide's example.
A few thousand tokens saved in one session may not sound like much. The point is the multiplication factor: repeated sessions, repeated agents, and repeated tasks against the same codebase. Rogut noted that he personally runs multiple agents at once. Under that pattern, rediscovering the same semantic relationships every time becomes wasteful.
Cursor's larger gains may come from models that know how to use retrieval
Kuba Rogut used Cursor as the production counterexample to Claude Code's default design. Claude Code, he said, does not use semantic code search by default. He cited a post from Boris Cherny saying early versions of Claude Code used RAG and a local vector database, but the team found agentic search worked better, was simpler, and avoided issues around security, privacy, staleness, and reliability.
Cursor, by contrast, does use semantic code search and indexes codebases into Turbopuffer, according to Rogut. A slide excerpting a Cursor blog post showed reported gains from semantic retrieval. The slide listed a 23.5% relative improvement for Composer on Cursor Context Bench and described an average 13.5% higher accuracy in answering questions across the models shown. Rogut summarized the across-model figure in speech as roughly 12.5% or 13%. The same slide also showed a 2.6% increase in code retention in large codebases and a 2.2% decrease in dissatisfied user requests.
| Model or metric | Reported effect from Cursor slide |
|---|---|
| Composer | 23.5% relative improvement on Cursor Context Bench |
| Gemini 2.5 Pro | 8.7% relative improvement |
| GPT-4 | 6.5% relative improvement |
| Grok Code | 11.9% relative improvement |
| Sonnet 4.5 | 14.7% relative improvement |
| Accuracy in answering questions | Average 13.5% higher accuracy, per the visible slide text |
| Code retention in large codebases | +2.6% |
| Dissatisfied user requests | -2.2% |
The smaller online A/B numbers should not automatically be read as trivial. Not every request needs semantic search. A simple tool call or simple query may never benefit from it, so an aggregate metric across all user requests dilutes the effect of retrieval-heavy cases.
Rogut's explanation for why his own benchmark gains were not as large as the Cursor figures was about tool use. Claude Code is built around grepping. In his experiment, semantic search was added as another available tool with instructions that Claude should use it sometimes. That is different from a product where semantic search is a built-in capability and the model knows when and how to use it.
It's very hard for it to have a true understanding of when to use it, why to use it.
The summary slide named "effective tool use" as dependent on RL and embeddings, and Rogut's spoken explanation focused on the agent's policy for calling the tool. The search backend can exist, but the agent still has to select it appropriately. Cursor's stronger reported results, in Rogut's view, are partly because semantic search is built in and the model understands when and how to call it, rather than seeing it as an extra command in a list.
Semantic retrieval depends on what meaning is present in the code
The audience questions exposed an important limit in Rogut's setup: semantic search is only as good as the representation being searched. Asked how it performs on "shit code," Kuba Rogut said it was hard to say, but that it works best when code contains comments, especially inline documentation or comments above functions. Those comments give the embedding model more semantic material to work with.
He described looking through trajectories and seeing stronger performance in repositories where good comments helped the model understand the chunk. The harder part, he said, is not merely embedding the text; it is figuring out the meaning of the chunk.
An audience member pressed on the mismatch between natural-language queries and raw code. Semantic search is similarity search, so if the query format does not match the target format, there is an inherent distance problem. The questioner asked whether Rogut used preprocessing such as a parent-child structure, where the parent is more query-like and the child is the real code.
For this benchmark, Rogut said no: it was just raw code. He did not claim to know the details of more sophisticated customer systems. He said it was plausible to provide not only code-level meaning but also a parent-child relationship, such as an "authentication flow" representation that is more naturally matched to a human query while still pointing back to raw code.
Another audience member speculated that Cursor may create synthetic comments above code and embed the code with those comments. Rogut did not confirm that as Cursor's implementation. He said something like that could work, and separately noted that Cursor has its own embedding model, which he thought helps with translating code into more of a human-level query.
That exchange narrows the benchmark's interpretation. Rogut's semantic condition was simple vector search over raw code chunks, without generated summaries or parent-child preprocessing. The fact that it improved precision under those constraints was one result; the fact that recall did not uniformly improve was another.
Vector databases become more compelling when the corpus is not just local code
In the final audience exchange, Kuba Rogut was asked how vector databases relate to longer-term memory and reducing the size of file indexing. His answer distinguished local grep's appeal from the broader retrieval problem. People like grep, he said, because it has zero cost when all the data is local and text-based. If you can download everything to a local file system and grep through it, that works.
Vector databases become more useful when the data is multiplayer, distributed, large, or semantically complex. Rogut used knowledge bases such as Notion as an example of material that is harder to grep effectively on a local machine and more suitable for vectorized retrieval by agents. He also pointed to multimodal data: video, audio, and images cannot really be grepped, beyond perhaps matching file names.
The same "cached compute" framing applied there. At even modest scale, Rogut said, a vector database can offload work into cached semantic meaning. The retrieval problem is no longer just finding text in files. It is giving agents lightweight ways to narrow very large context spaces into the subset that matters.
His closing claim was that long-term winners will provide lightweight tools for finding the right context in different ways. Grep remains useful, and in his benchmark it won certain classes of tasks. But Rogut argued that agents cannot simply grep through everything forever. The systems that matter, in his words, will be the ones that provide easy tools to shrink "billion context windows into the right million."